개요
- AnalyticDB for MySQL (ADB)
- 대규모 데이터의 실시간 분석을 위해 설계된 클라우드 네이티브 데이터 웨어하우스임
- 기본적으로 MySQL 프로토콜과 호환되지만 대용량 분산 처리를 위한 고유한 문법과 아키텍처 특징이 있음
아키텍처 특징
분산 아키텍처
- 데이터를 여러 노드에 분산 저장함
- 쿼리 작성 시 데이터 분포(Distribution)를 고려해야 성능이 나옴
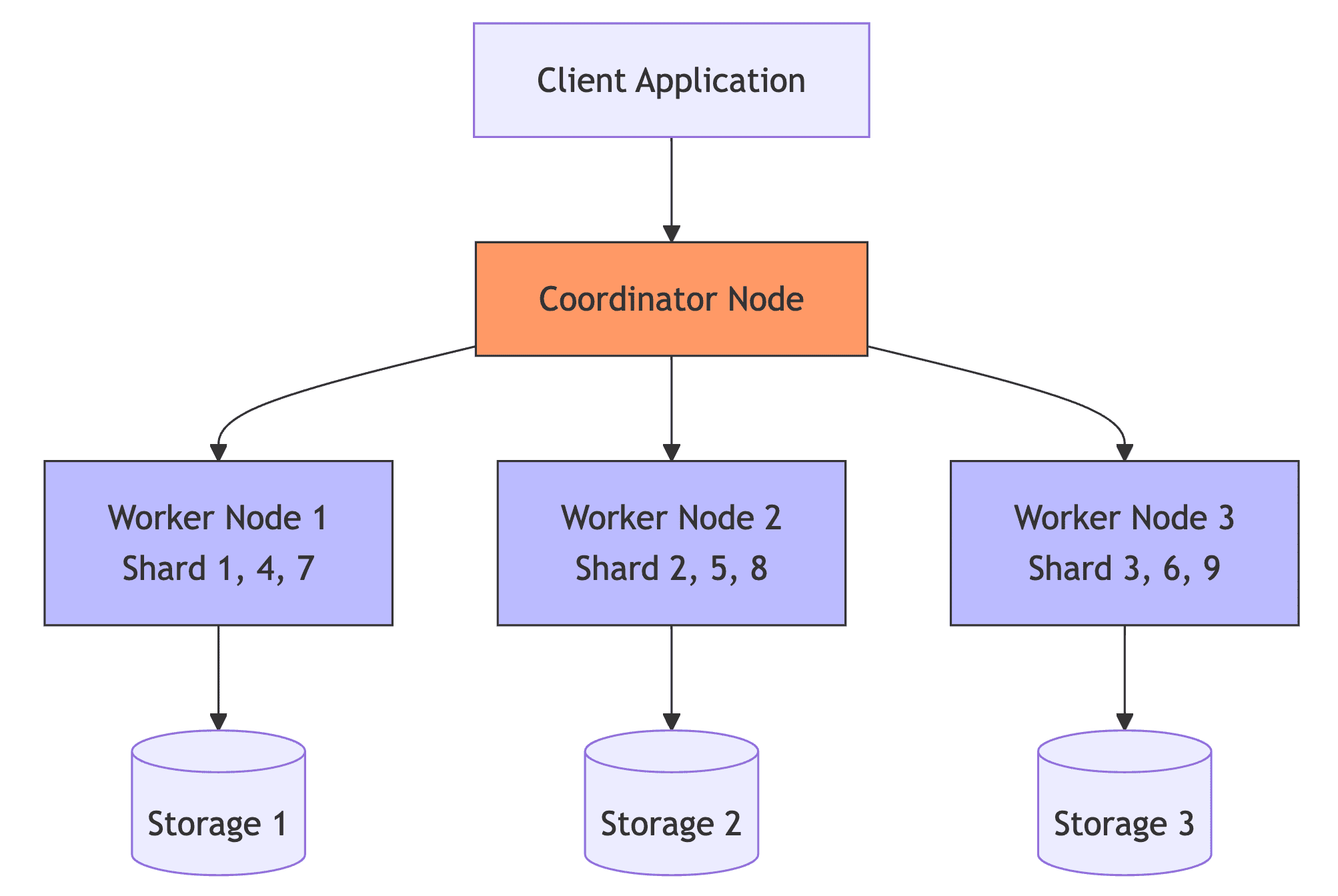
- 배포 키 (Distribution Key)
- 테이블 생성 시
DISTRIBUTED BY HASH(col_name)지정 필수 - 조인(Join)이나 집계(Group By)에 자주 사용되는 컬럼을 지정해야 데이터 이동(Shuffle)을 최소화할 수 있음
- 성능에 가장 큰 영향을 미치는 설정임
- 테이블 생성 시
전체 컬럼 인덱싱
- ADB는 기본적으로 모든 컬럼에 인덱스를 자동으로 생성함
- 일반 MySQL처럼 인덱스를 일일이 고민할 필요가 적음
WHERE절에 어떤 컬럼이 오더라도 빠르게 필터링 가능- 주의사항
- 쓰기 성능에 영향이 있을 수 있으므로, 불필요한 컬럼(예: 긴 텍스트 로그)은
INDEX_ALL='N'옵션으로 제외 가능
- 쓰기 성능에 영향이 있을 수 있으므로, 불필요한 컬럼(예: 긴 텍스트 로그)은
컬럼 기반 저장
- 분석 쿼리(
SUM,AVG,COUNT)에 최적화되어 있음 SELECT *보다는 필요한 컬럼만 명시하는 것이 훨씬 빠름
DDL
테이블 생성 옵션
| 옵션 | 설명 | 필수 여부 |
|---|---|---|
| DISTRIBUTED BY HASH | 데이터 분산 기준 컬럼 | 필수 |
| PARTITION BY VALUE | 파티션 기준 (시계열 관리) | 선택 |
| LIFECYCLE | 파티션 수명 주기 (일 단위) | 선택 |
| INDEX_ALL | 전체 컬럼 자동 인덱싱 (기본값 ‘Y’) | 선택 |
| STORAGE_POLICY | HOT/COLD/MIXED 스토리지 전략 | 선택 |
| ENGINE=’ODPS’ | MaxCompute 외부 테이블 연결 | 선택 |
기본 테이블 생성
1
2
3
4
5
6
7
8
CREATE TABLE `{TABLE_ID}` (
`id` BIGINT NOT NULL AUTO_INCREMENT,
`{COLUMN_NAME}` {DATA_TYPE},
`region` VARCHAR(20),
PRIMARY KEY (`id`)
)
DISTRIBUTE BY HASH(`id`)
INDEX_ALL = 'Y';
파티셔닝과 Lifecycle 설정
1
2
3
4
5
6
7
8
9
10
11
CREATE TABLE `orders` (
`order_id` BIGINT NOT NULL,
`customer_id` INT NOT NULL,
`order_date` DATE,
`amount` DECIMAL(10, 2),
`region` VARCHAR(20),
PRIMARY KEY (`order_id`, `order_date`)
)
DISTRIBUTED BY HASH(`order_id`)
PARTITION BY VALUE(DATE_FORMAT(`order_date`, '%Y%m'))
LIFECYCLE 365;
- PARTITION BY VALUE
- 시계열 데이터를 효율적으로 관리하기 위한 파티션 설정
DATE_FORMAT(order_date, '%Y%m')- 월별 파티션 생성
- LIFECYCLE
- 파티션의 수명 주기(일 단위)를 지정하여, 오래된 데이터 자동 삭제
LIFECYCLE 365- 365일 이후 자동 삭제
Storage Policy
1
2
3
4
5
6
7
8
9
10
CREATE TABLE `logs` (
`id` BIGINT NOT NULL,
`created_at` DATETIME,
`message` TEXT,
PRIMARY KEY (`id`, `created_at`)
)
DISTRIBUTE BY HASH(`id`)
PARTITION BY VALUE(DATE_FORMAT(`created_at`, '%Y%m%d'))
STORAGE_POLICY = 'MIXED'
HOT_PARTITION_COUNT = 30;
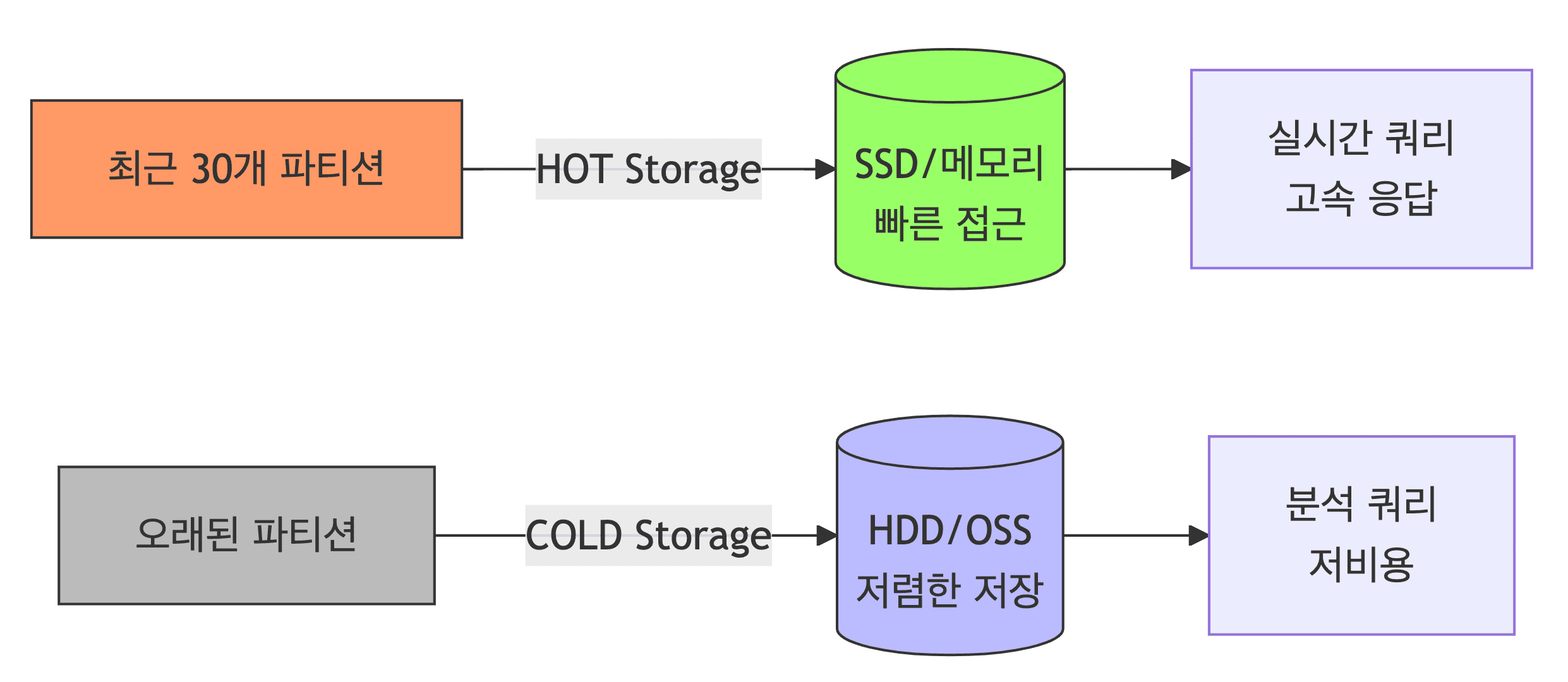
- STORAGE_POLICY
HOT- 메모리/SSD (빠른 접근, 비쌈)COLD- HDD/OSS (느린 접근, 저렴)MIXED- 혼합 (권장)
- HOT_PARTITION_COUNT
- 최근 30개의 파티션만 HOT 스토리지에 저장하고 나머지는 COLD로 이동
ODPS 외부 테이블 연결
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
CREATE TABLE `external_data` (
`id` BIGINT NOT NULL,
`val` VARCHAR(255),
`ds` VARCHAR(255),
PRIMARY KEY (`id`)
)
DISTRIBUTE BY HASH(`id`)
ENGINE='ODPS'
TABLE_PROPERTIES='{
"endpoint":"http://service.cn-hangzhou.maxcompute.aliyun-inc.com/api",
"accessid":"{ACCESS_ID}",
"accesskey":"{ACCESS_KEY}",
"project_name":"{PROJECT_ID}",
"table_name":"{ODPS_TABLE_NAME}",
"partition_column":"ds"
}';
테이블 관리
파티션 및 스토리지 정책 관리
- 파티션 정보 확인
1
SELECT * FROM INFORMATION_SCHEMA.PARTITIONS WHERE TABLE_NAME = '{TABLE_ID}';
- Lifecycle 변경
1 2
ALTER TABLE `{TABLE_ID}` PARTITIONS {LIFECYCLE}; BUILD TABLE {DB_NAME}.{TABLE_ID};
BUILD TABLE명령으로 빌드해야 반영됨 (ADB 2.0 등 특정 버전에서 필수, 최신 버전 확인 필요)
- Storage Policy 변경
1 2
ALTER TABLE `{TABLE_ID}` STORAGE_POLICY = 'MIXED' HOT_PARTITION_COUNT = 60; BUILD TABLE {DB_NAME}.{TABLE_ID};
테이블 수정
- 컬럼 추가
1
ALTER TABLE {TABLE_ID} ADD {COLUMN_NAME} {DATA_TYPE} NULL;
- 컬럼명 변경
1
ALTER TABLE {TABLE_ID} CHANGE {OLD_NAME} {NEW_NAME} {DATA_TYPE};
- 테이블 이름 변경
1
RENAME TABLE {OLD_TABLE} TO {NEW_TABLE};
DML 및 쿼리 최적화
대량 데이터 적재
- 단건
INSERT는 성능이 매우 떨어지므로 Multi-row Insert를 사용해야 함
1
2
3
4
5
6
7
8
9
-- 권장: Multi-row Insert
INSERT INTO orders (order_id, customer_id) VALUES
(1, 100),
(2, 101),
(3, 102);
-- 비권장: 단건 INSERT (느림)
INSERT INTO orders (order_id, customer_id) VALUES (1, 100);
INSERT INTO orders (order_id, customer_id) VALUES (2, 101);
데이터 복사 및 비동기 작업
- INSERT INTO … SELECT (동기식)
1
INSERT INTO {TGT_TABLE} SELECT * FROM {SRC_TABLE};
- Submit Job (비동기식 대량 작업)
1 2 3 4
/*+async_job_priority=1*/ SUBMIT JOB INSERT INTO {TGT_TABLE} SELECT * FROM {SRC_TABLE} WHERE created_at >= '2022-10-01';
- Job 상태 확인
1
SHOW JOB STATUS WHERE job='{JOB_ID}';
쿼리 힌트
- 조인 순서 제어
- 옵티마이저가 자동으로 조인 순서를 바꾸지 않도록 강제함
- 내가 쓴 순서대로 조인하게 함
1 2
/*+ REORDER_JOINS=FALSE */ SELECT * FROM A JOIN B ON A.id = B.id;
- MPP 모드 강제
- 대량의 데이터 처리 시 로컬 MySQL 엔진 대신 분산 엔진을 쓰도록 유도
조인 최적화 전략
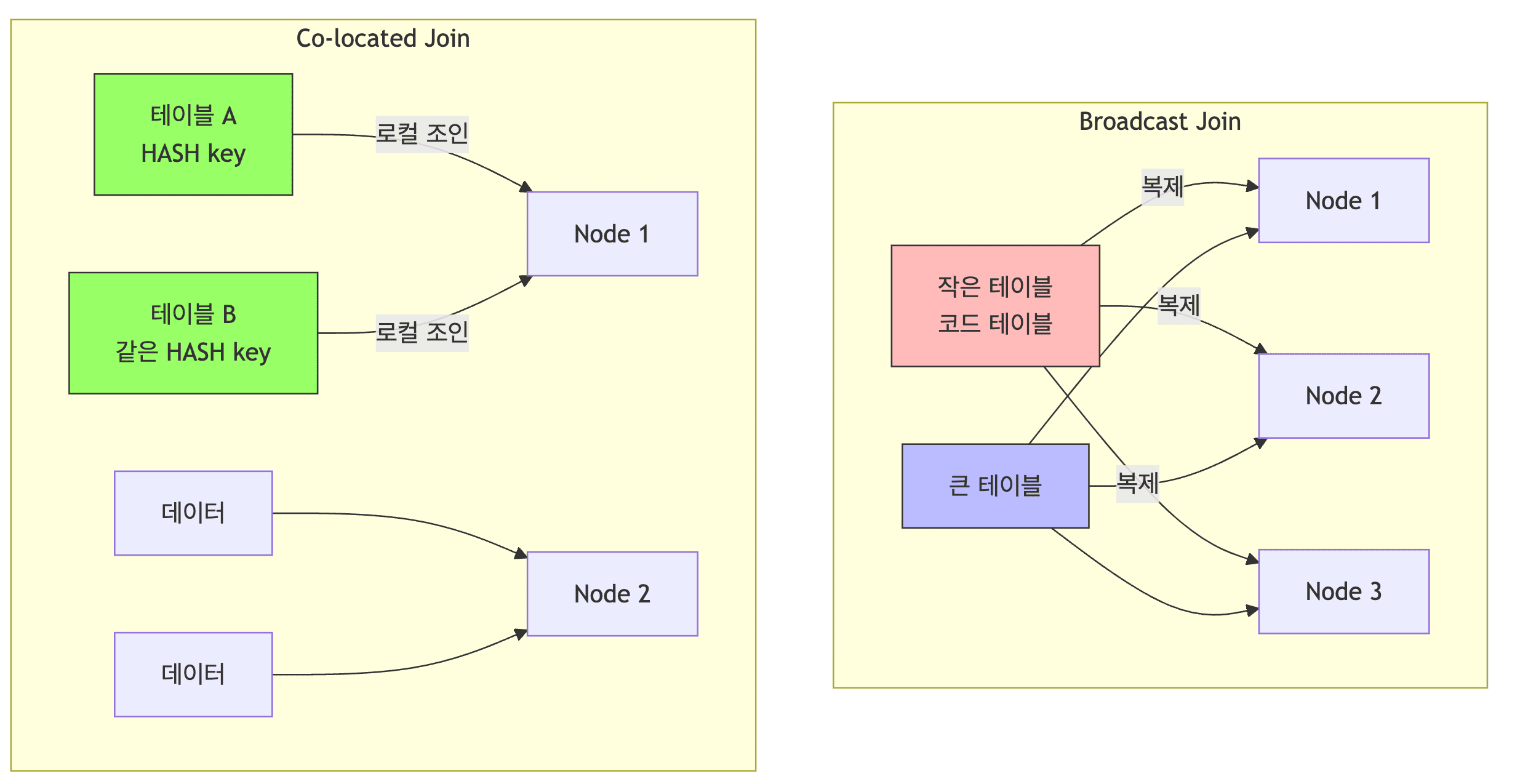
- Broadcast Join
- 작은 테이블(예: 코드 테이블)과 큰 테이블을 조인할 때 사용
- 작은 테이블을 모든 노드에 복제하여 셔플(Shuffle) 방지
- ADB는 통계 정보를 기반으로 자동 처리하지만, 쿼리 힌트로 제어 가능
- Co-located Join
- 두 테이블이 같은
DISTRIBUTED BY키를 가지고 있을 때 사용 (단, 샤드 개수도 동일해야 함) - 데이터 이동 없이 각 노드에서 로컬 조인이 발생하여 매우 빠름
- 가장 효율적인 조인 방식임
- 두 테이블이 같은
JSON 데이터 쿼리
- ADB는 JSON 타입을 지원하며, 내부적으로 인덱싱하여 빠른 검색이 가능함
1
2
3
SELECT json_extract(data, '$.user.name')
FROM logs
WHERE json_extract(data, '$.status') = 'error';
실시간 분석 쿼리
1
2
3
4
5
-- 특정 지역의 최근 1시간 매출 집계
SELECT region, SUM(amount)
FROM orders
WHERE order_date >= NOW() - INTERVAL 1 HOUR
GROUP BY region;
ADB 운영 및 관리
프로세스 및 용량 모니터링
- 실행 중인 프로세스 확인
1
SHOW FULL PROCESSLIST;
- 쿼리 타임아웃 설정
1 2
SET query_timeout = 1800000; -- 30분 SET insert_select_timeout = 3600000; -- 1시간
- 테이블별 용량 확인
1 2 3 4 5
SELECT table_name, ROUND(SUM(data_length + index_length) / (1024 * 1024), 2) AS 'Total_MB' FROM information_schema.tables GROUP BY table_name ORDER BY Total_MB DESC;
계정 및 권한 관리
- 계정 생성
1
CREATE USER '{USER_ID}' IDENTIFIED BY '{PASSWORD}';
- 권한 부여
1 2
GRANT ALL ON {DB_NAME}.* TO '{USER_ID}'; GRANT SELECT ON {DB_NAME}.{TABLE_ID} TO '{USER_ID}';
- 권한 확인
1
SHOW GRANTS FOR '{USER_ID}';
MySQL과의 차이점
지원하지 않는 기능
| 기능 | MySQL | ADB |
|---|---|---|
| 트랜잭션 | ACID 완전 지원 | 제한적 지원 (배치 처리 권장) |
| Stored Procedure | 완전 지원 | 제한적 또는 미지원 |
| Trigger | 완전 지원 | 제한적 또는 미지원 |
| Foreign Key | 완전 지원 | 문법만 지원 (제약 조건 미작동) |
- 트랜잭션 제한
- ACID를 지원하지만, OLTP성 트랜잭션(짧고 빈번한 갱신)보다는 대량의 배치
INSERT/UPDATE에 최적화되어 있음
- ACID를 지원하지만, OLTP성 트랜잭션(짧고 빈번한 갱신)보다는 대량의 배치
- Stored Procedure/Trigger
- 지원이 제한적이거나 없을 수 있음 (버전별 상이)
- Foreign Key
- 문법적으로 지원하지만, 제약 조건으로서의 기능은 하지 않음
- 데이터 무결성은 애플리케이션 레벨에서 관리 필요
ADB 설계 및 개발 가이드
- 분산 키(Distribute Key) 선정에 집중
- 조인 성능의 90%를 결정하므로, 조인 키로 주로 사용되는 컬럼을 선정해야 함
- 데이터가 특정 노드에 치우치지 않고 균등하게 분산되도록 설계
- 자동 인덱스 기능 활용
INDEX_ALL='Y'옵션 덕분에 모든 컬럼에 대해 인덱스가 자동 관리됨- 수동으로
CREATE INDEX를 관리할 필요가 없어 운영 부담이 적음
- 배치 처리 지향
- 데이터 입력은 Multi-row Insert(
INSERT INTO ... VALUES ...)로 모아서 처리 - 대량의 데이터 갱신/삭제 시
SUBMIT JOB을 활용한 비동기 처리 권장주의: ADB는
APPEND에 최적화되어 있습니다.UPDATE나DELETE는 파티션 재작성을 유발할 수 있어 비용이 매우 비싸므로, 빈번한 단건 수정/삭제는 피해야 합니다.
- 데이터 입력은 Multi-row Insert(