- 깊이 우선 탐색(DFS, Depth-First Search)은 그래프의 시작 노드에서 갈 수 있는 한 깊게 탐색하다가 더 이상 갈 곳이 없으면 이전으로 돌아오는 알고리즘임
- 스택(Stack) 또는 재귀를 사용하여 구현하며 모든 경우의 수를 탐색하거나 경로의 특징을 저장해야 할 때 유리함
DFS 알고리즘
알고리즘 개념
- 미로 찾기처럼 한 방향으로 갈 수 있을 때까지 계속 가다가 더 이상 갈 수 없게 되면 가장 가까운 갈림길로 돌아와서 다른 방향으로 다시 탐색을 진행하는 방식임
- 백트래킹(Backtracking)과 밀접한 관련이 있음
동작 흐름
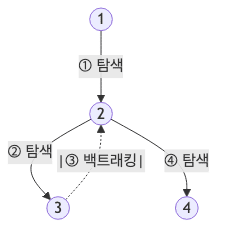
- 초기 상태
- 시작 노드인 1번 노드를 방문하고 재귀 호출을 시작함
- 방문 현황:
[1]
- 깊게 탐색
- 1번 노드와 인접한 2번 노드로 이동
- 방문 현황:
[1 -> 2](1번은 호출 스택에 대기 중)
- 더 깊게 탐색
- 2번 노드와 인접한 3번 노드로 이동
- 방문 현황:
[1 -> 2 -> 3]
- 막다른 길 및 백트래킹
- 3번 노드에서 더 이상 방문하지 않은 인접 노드가 없다면 함수가 종료됨
- 탐색 위치가 3번에서 2번 노드로 돌아옴 (Back)
- 다른 분기 탐색
- 2번 노드에서 아직 방문하지 않은 다른 인접 노드(예: 4번)가 있다면 그 곳으로 이동함
- 방문 현황:
[1 -> 2 -> 4]
판단 기준
- 어떤 문제에서 DFS를 사용해야 하는지 판단하는 기준임
모든 경로 및 해 탐색
- 미로 찾기에서 도달 가능한 모든 경로의 수를 구하거나 조건을 만족하는 해가 존재하는지 확인할 때
경로의 특징 저장
- 경로상의 노드들을 기억해야 하거나 특정 조건을 만족하는 경로만 찾아야 할 때
- ex)
- 경로에 A노드가 포함되면 안 된다
- 경로의 합이 X가 되어야 한다
- ex)
연결성 확인 및 그룹화
- 연결 요소(Connected Component)의 개수를 세거나 서로 연결되어 있는지 확인할 때
순열 및 조합 구현
- N개 중 M개를 고르는 문제 등 조합론적 문제의 기초가 됨
동작 원리
-
DFS는 후입선출(LIFO) 방식의 탐색으로 가장 나중에 방문한 노드에서 다시 깊게 들어가는 방식임
- 초기화
- 시작 노드를 방문 처리함
- 재귀 호출 (Recursive Call)
- 현재 노드와 인접한 노드 중 방문하지 않은 노드가 있다면 그 노드를 방문 처리하고 즉시 재귀 호출로 들어감
- 백트래킹 (Backtracking)
- 더 이상 갈 곳이 없으면 함수가 종료(return)되어 이전 호출 지점인 부모 노드로 돌아감
풀이 접근법
- 문제를 만났을 때 DFS로 해결하기 위한 구체적인 접근 방법임
그래프 모델링
- 노드
- 현재 상태
- 간선
- 상태 전이 (이동)
- 연결 리스트(
ArrayList[])나 2차원 배열(int[][])로 표현 가능
상태 정의 및 방문 체크
visited배열이 가장 중요함- 단순 방문 체크
visited[next] = true- 한 번 방문하면 끝
- 경로 복원이 필요한 경우 (백트래킹)
- 재귀 함수는 반드시 종료 조건이 명확해야 함
1 2 3 4 5 6 7
void dfs(int node) { if (조건 만족) return; for (int next : graph[node]) { // ... } }
시간 복잡도
인접 리스트
- $O(V + E)$
- 모든 정점($V$)을 한 번씩 방문하고 모든 간선($E$)을 한 번씩 검사함
인접 행렬
- $O(V^2)$
- 모든 노드에 대해 $V$번 반복하여 인접 여부를 확인함
결론
- DFS도 BFS와 마찬가지로 $V$가 클 때는 인접 리스트 방식이 효율적임
Java 구현
- DFS는 주로 재귀(Recursion) 방식으로 구현함
기본 구현
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// 전역 상태 (클래스 필드 등으로 관리)
boolean[] visited = new boolean[N + 1];
ArrayList<Integer>[] graph = new ArrayList[N + 1];
// DFS 구현부
void dfs(int node) {
visited[node] = true; // 현재 노드 방문 처리
// 인접 노드 탐색
for (int next : graph[node]) {
if (!visited[next]) {
dfs(next);
}
}
}