개요
- 배열과 리스트는 모두 여러 데이터를 저장하는 자료 구조이지만, 메모리 구조와 특성이 근본적으로 다름
- 배열은 고정 크기의 연속적인 메모리 공간을 사용하는 반면, 리스트는 동적 크기 조정이 가능한 자료 구조임
- 각각의 특성을 이해하고 상황에 맞게 선택하는 것이 성능 최적화의 핵심임
배열(Array)의 특징
정의
- 배열은 동일한 타입의 원소들을 연속적인 메모리 공간에 고정 크기로 저장하는 자료 구조임
- 생성 시점에 크기가 결정되며, 이후 크기 변경이 불가능함
핵심 특징
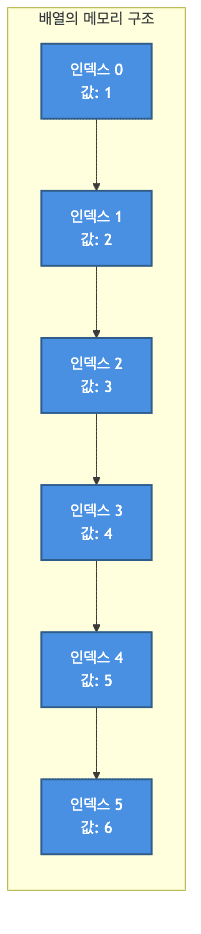
- 인덱스를 통한 직접 접근
- 인덱스를 사용하여 값에 바로 접근할 수 있음
- 시작 주소 + (인덱스 × 원소 크기) 계산으로 즉시 위치 파악
- 고정된 크기
- 배열의 크기는 선언할 때 지정할 수 있으며, 한 번 선언하면 크기를 늘리거나 줄일 수 없음
- 메모리 공간이 연속적으로 할당되어야 하므로 크기 변경 불가
- 비효율적인 삽입/삭제
- 새로운 값을 삽입하거나 특정 인덱스에 있는 값을 삭제하기 어려움
- 값을 삽입하거나 삭제하려면 해당 인덱스 주변에 있는 값들을 이동시켜야 함
- 구조의 단순성
- 구조가 간단하므로 코딩 테스트에서 많이 사용함
- 연속된 메모리 할당으로 캐시 효율성이 높음
시간 복잡도
- 접근
- (O(1))
- 인덱스를 통해 원하는 원소에 즉시 접근 가능
- 시작 주소 + (인덱스 × 원소 크기) 계산으로 위치 파악
- 탐색
- (O(n))
- 정렬되지 않은 경우 모든 원소를 순회해야 함
- 정렬된 경우 이진 탐색으로 (O(\log n)) 가능
- 삽입 및 삭제
- (O(n))
- 중간에 원소 삽입 시 뒤의 모든 원소를 한 칸씩 이동해야 함
- 맨 끝 삽입/삭제는 (O(1))이지만 크기 제한 존재
Java에서의 배열 예제
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
public class ArrayExample {
public static void main(String[] args) {
// 배열 생성 - 크기 고정
int[] numbers = new int[5];
// 배열 초기화
int[] scores = {90, 85, 92, 88, 95};
// 접근 - O(1)
System.out.println("첫 번째 점수: " + scores[0]); // 90
// 수정 - O(1)
scores[2] = 100;
// 순회 - O(n)
for (int i = 0; i < scores.length; i++) {
System.out.println(scores[i]);
}
// 크기 변경 불가 - 새 배열 생성 필요
// scores[5] = 80; // ArrayIndexOutOfBoundsException 발생
}
}
장점
- 빠른 접근 속도
- 인덱스를 통한 (O(1)) 시간 복잡도로 즉시 접근
- 메모리 효율성
- 포인터 같은 추가 참조 정보를 저장할 필요가 없음
- 연속된 메모리 할당으로 공간 낭비가 적음
- 캐시 지역성(Cache Locality)
- 연속된 메모리 구조로 CPU 캐시 효율이 높음
- 순차 접근 시 성능이 우수함
단점
- 고정 크기
- 생성 후 크기 변경 불가능
- 크기 확장이 필요한 경우 새 배열 생성 후 복사 필요
- 비효율적인 삽입/삭제
- 중간 위치 삽입/삭제 시 (O(n)) 시간 소요
- 원소 이동으로 인한 성능 저하
- 메모리 낭비 가능성
- 사용하지 않는 공간도 미리 할당되어 메모리 낭비 발생 가능
리스트(List)의 특징
정의
- 리스트는 크기가 동적으로 변할 수 있는 가변 크기 자료 구조임
- Java에서는 주로 ArrayList(동적 배열)와 LinkedList(연결 리스트) 두 가지로 구현됨
동적 배열 (ArrayList)
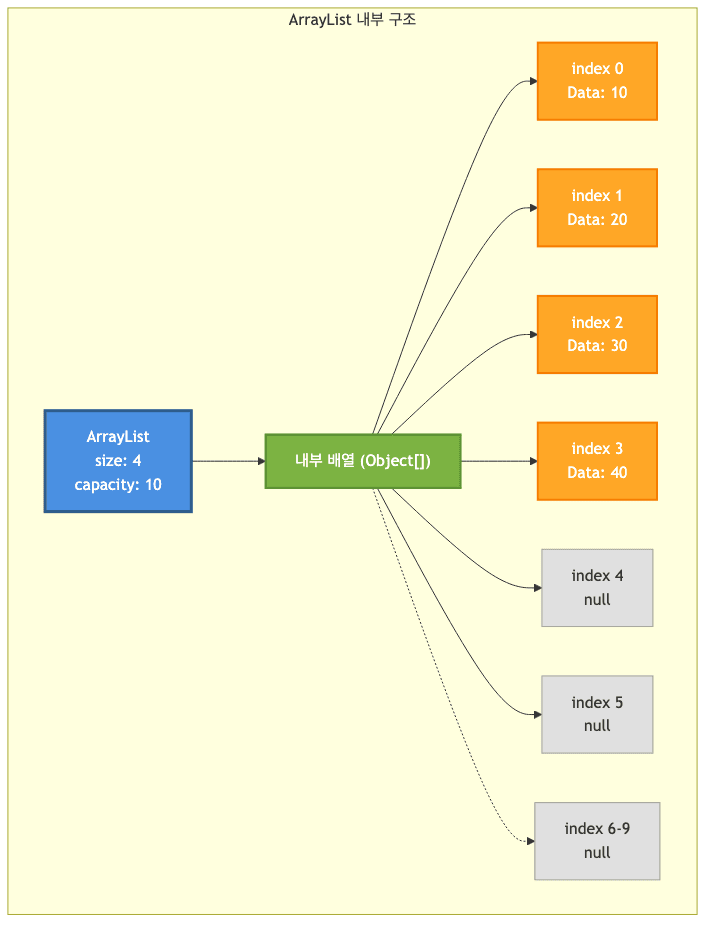
- 내부 구조
- 내부적으로 배열을 사용하되, 필요에 따라 자동으로 크기를 확장함
- 초기 용량(capacity)을 설정하고, 공간이 부족하면 더 큰 배열을 생성한 후 기존 데이터 복사
- 시간 복잡도
- 접근
- (O(1))
- 삽입 및 삭제
- 평균 (O(n))
- 맨 끝은 (O(1))
- 용량 확장
- (O(n))
- 새 배열 생성 및 복사 과정 필요
- 접근
ArrayList 동적 확장 과정
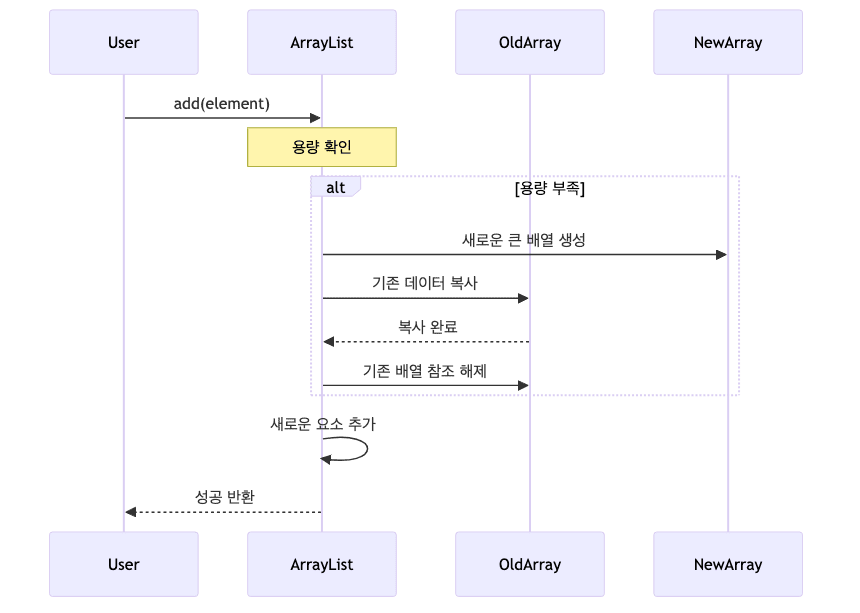
- 확장 과정
- 현재 용량이 가득 차면 새로운 더 큰 배열 생성
- 기존 데이터를 새 배열로 복사
- 기존 배열 참조 해제
- 새로운 요소 추가
- 확장 계수 (Growth Factor)
- Java 8 이후 기준 약 1.5배로 확장
- 새 용량 계산식
newCapacity = oldCapacity + (oldCapacity >> 1)- 비트 시프트 연산으로 oldCapacity의 절반을 더함
- 예시
- 초기 용량 10 → 15 → 22 → 33 순으로 증가
- 확장 비용
- 데이터 복사로 인해 (O(n)) 시간 소요
- 평상시에는 (O(1))이지만 확장 시에만 (O(n))
- 이를 상각 분석(Amortized Analysis)하면 평균 (O(1))로 간주 가능
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
import java.util.ArrayList;
public class ArrayListExample {
public static void main(String[] args) {
// ArrayList 생성 - 초기 용량 10
ArrayList<Integer> list = new ArrayList<>();
// 삽입 - 맨 끝에 추가 O(1)
list.add(10);
list.add(20);
list.add(30);
// 중간 삽입 - O(n)
list.add(1, 15); // [10, 15, 20, 30]
// 접근 - O(1)
System.out.println("두 번째 원소: " + list.get(1)); // 15
// 삭제 - O(n)
list.remove(2); // [10, 15, 30]
// 크기 동적 변경 가능
for (int i = 0; i < 100; i++) {
list.add(i); // 자동으로 용량 확장
}
System.out.println("크기: " + list.size()); // 103
}
}
연결 리스트 (LinkedList)

- 내부 구조
- 리스트는 값과 포인터를 묶은 노드를 포인터로 연결한 자료구조임
- 노드는 컴퓨터 과학에서 값과 포인터를 쌍으로 갖는 기초 단위를 부르는 말임
- 각 노드가 데이터와 다음 노드를 가리키는 포인터로 구성됨
- 메모리상 비연속적인 위치에 데이터를 저장함
- Java의 LinkedList는 이중 연결 리스트(Doubly Linked List)로 구현됨
- 핵심 특징
- 인덱스가 없으므로 값에 접근하려면 Head 포인터부터 순서대로 접근해야 함
- 다시 말해 값에 접근하는 속도가 느림
- 포인터로 연결되어 있으므로 데이터를 삽입하거나 삭제하는 연산 속도가 빠름
- 선언할 때 크기를 별도로 지정하지 않아도 되며, 크기가 변하기 쉬운 데이터를 다룰 때 적합함
- 포인터를 저장할 공간이 필요하므로 배열보다 구조가 복잡함
- 시간 복잡도
- 접근
- (O(n))
- 시작부터 순차 탐색 필요
- 삽입 및 삭제
- (O(1))
- 특정 노드 위치를 알고 있을 때만 해당
- 탐색 후 삽입 및 삭제
- (O(n))
- 탐색 과정에서 (O(n)) 소요
- 접근
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
import java.util.LinkedList;
public class LinkedListExample {
public static void main(String[] args) {
// LinkedList 생성
LinkedList<String> list = new LinkedList<>();
// 삽입 - 앞/뒤 추가 O(1)
list.addFirst("First");
list.addLast("Last");
list.add("Middle");
// 접근 - O(n)
System.out.println("첫 번째: " + list.get(0)); // First
System.out.println("마지막: " + list.getLast()); // Last
// 삭제 - 앞/뒤 O(1), 중간 O(n)
list.removeFirst();
list.removeLast();
// 중간 삽입 - O(n)
list.add(0, "New First");
System.out.println(list); // [New First, Middle]
}
}
ListIterator를 통한 O(1) 삽입 및 삭제
- 일반적인 메서드의 한계
list.add(index, element)호출 시 문제점- 해당 인덱스까지 순차 탐색 필요
- 탐색 과정에서 (O(n)) 소요
- 삽입 자체는 (O(1))이지만 전체 연산은 (O(n))
list.get(index)역시 동일한 문제- Head나 Tail에서 가까운 쪽부터 탐색
- 최악의 경우 (O(n)) 시간 소요
ListIterator를 활용한 실제 O(1) 연산- Iterator가 현재 노드 위치를 기억
- 순회 중 노드 참조를 직접 보유
- 추가 탐색 없이 즉시 삽입 및 삭제 가능
add()및remove()메서드가 (O(1)) 보장- 포인터만 조작하여 노드 연결
- 데이터 이동이나 탐색 불필요
- Iterator가 현재 노드 위치를 기억
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
import java.util.LinkedList;
import java.util.ListIterator;
public class LinkedListIteratorExample {
public static void main(String[] args) {
LinkedList<Integer> list = new LinkedList<>();
// 초기 데이터 삽입
for (int i = 1; i <= 5; i++) {
list.add(i * 10);
}
// 현재 리스트: [10, 20, 30, 40, 50]
// ListIterator를 사용한 O(1) 삽입
ListIterator<Integer> iterator = list.listIterator();
// 순회하며 조건에 맞는 위치에 O(1) 삽입
while (iterator.hasNext()) {
Integer value = iterator.next();
// 값이 30보다 크면 그 앞에 새 값 삽입
if (value > 30) {
iterator.previous(); // 현재 위치로 돌아감
iterator.add(25); // O(1) 삽입
iterator.next(); // 원래 순회 위치로 복귀
}
}
// 결과 리스트: [10, 20, 30, 25, 40, 25, 50]
System.out.println("삽입 후: " + list);
// ListIterator를 사용한 O(1) 삭제
iterator = list.listIterator();
while (iterator.hasNext()) {
Integer value = iterator.next();
// 25인 값을 모두 O(1) 삭제
if (value == 25) {
iterator.remove(); // O(1) 삭제
}
}
// 결과 리스트: [10, 20, 30, 40, 50]
System.out.println("삭제 후: " + list);
}
}
- 성능 비교
- 인덱스 기반 삽입 (
list.add(index, element))- 탐색 (O(n)) + 삽입 (O(1)) = 전체 (O(n))
- Iterator 기반 삽입 (
iterator.add(element))- 현재 위치에서 즉시 삽입 = (O(1))
- 대량 중간 삽입 시 성능 차이가 극명함
- 인덱스 기반 삽입 (
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
import java.util.LinkedList;
import java.util.ListIterator;
public class LinkedListPerformanceComparison {
public static void main(String[] args) {
int size = 10000;
// 방법 1: 인덱스 기반 삽입 - O(n^2)
LinkedList<Integer> list1 = new LinkedList<>();
for (int i = 0; i < size; i++) {
list1.add(i);
}
long start = System.currentTimeMillis();
for (int i = 0; i < 1000; i++) {
list1.add(size / 2, -1); // 중간 위치에 삽입 - O(n)
}
long indexBasedTime = System.currentTimeMillis() - start;
// 방법 2: ListIterator 사용 - O(n)
LinkedList<Integer> list2 = new LinkedList<>();
for (int i = 0; i < size; i++) {
list2.add(i);
}
start = System.currentTimeMillis();
ListIterator<Integer> iterator = list2.listIterator();
// 중간 위치까지 이동 - O(n)
for (int i = 0; i < size / 2; i++) {
iterator.next();
}
// 1000번 삽입 - 각각 O(1)
for (int i = 0; i < 1000; i++) {
iterator.add(-1); // O(1) 삽입
}
long iteratorBasedTime = System.currentTimeMillis() - start;
System.out.println("인덱스 기반 삽입: " + indexBasedTime + "ms");
System.out.println("Iterator 기반 삽입: " + iteratorBasedTime + "ms");
System.out.println("성능 차이: " + (indexBasedTime / (double) iteratorBasedTime) + "배");
}
}
- 활용 시나리오
- 순차 탐색하며 조건부 삽입 및 삭제가 필요한 경우
- 리스트를 한 번만 순회하며 여러 위치에서 수정이 필요한 경우
- 대용량 데이터에서 중간 삽입 및 삭제가 빈번한 경우
- Iterator 패턴이 적용된 알고리즘 구현 시
장점
- 동적 크기
- 런타임에 크기 조정 가능
- 메모리 효율적인 확장
- 유연한 삽입/삭제 (LinkedList)
- 특정 위치에서 (O(1)) 삽입/삭제 가능
- 포인터만 변경하면 되므로 데이터 이동 불필요
단점
- 느린 접근 속도 (LinkedList)
- 인덱스 접근 시 (O(n)) 시간 소요
- 순차 탐색 필요
- 메모리 오버헤드 (LinkedList)
- 각 노드마다 데이터 외에 추가 참조 저장 공간 필요
- Java LinkedList 노드 구조
- 데이터 참조 (Item)
- 이전 노드 참조 (Prev)
- 다음 노드 참조 (Next)
- 객체 자체의 헤더 오버헤드 존재
- 실제 데이터보다 2-3배 많은 메모리 사용
- 64비트 JVM 기준 노드당 약 24-32바이트 추가 메모리 필요
- 낮은 캐시 효율성 (LinkedList)
- 비연속적 메모리 구조로 캐시 미스 발생률 높음
배열과 리스트의 비교
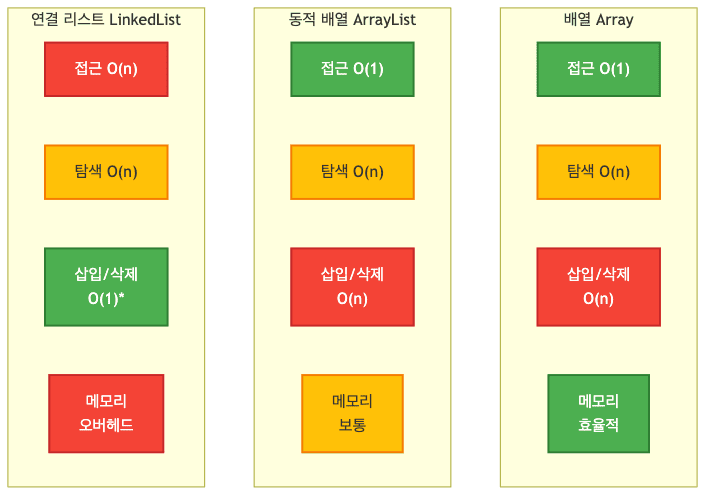
비교표
| 특징 | 배열 | ArrayList | LinkedList |
|---|---|---|---|
| 크기 | 고정 | 동적 | 동적 |
| 메모리 할당 | 초기 한 번 | 필요시 동적 증가 | 필요할 때마다 할당 |
| 임의 원소 접근 | (O(1)) | (O(1)) | (O(n)) |
| 탐색 | (O(n)) | (O(n)) | (O(n)) |
| 맨 끝 삽입 | (O(1))* | (O(1))** | (O(1)) |
| 중간 삽입/삭제 | (O(n)) | (O(n)) | (O(1))*** |
| 메모리 효율성 | 높음 | 높음 | 낮음 (포인터 오버헤드) |
| 캐시 효율성 | 높음 | 높음 | 낮음 |
* 크기 제한 있음
** 용량 확장 시 (O(n))
*** 해당 노드 위치를 이미 알고 있을 때
기본형 타입과 래퍼 타입의 메모리 차이
- 배열 (Primitive Type 지원)
- 기본형 배열 사용 가능
int[],double[],char[]등
- 데이터를 직접 저장
- 박싱(Boxing) 없이 값 자체를 메모리에 저장
- 메모리 효율성 극대화
int배열의 경우 요소당 4바이트만 사용
- 간접 참조 없음
- 배열 시작 주소에서 직접 계산으로 접근
- 기본형 배열 사용 가능
- ArrayList (Wrapper Type만 지원)
- 제네릭으로 인한 래퍼 클래스 사용 필수
ArrayList<Integer>,ArrayList<Double>등
- 박싱으로 인한 오버헤드
- 기본형 값을 객체로 감싸는 추가 과정 필요
- Auto-boxing/Unboxing 비용 발생
- 메모리 간접 참조
- ArrayList → Object[] → Integer 객체 → int 값
- 2단계 이상의 참조를 거쳐야 실제 값 접근
- 추가 메모리 사용
Integer객체당 약 16바이트 추가 (객체 헤더 포함)int배열 대비 4-5배 메모리 사용
- 제네릭으로 인한 래퍼 클래스 사용 필수
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
public class PrimitiveVsWrapper {
public static void main(String[] args) {
// 기본형 배열 - 메모리 효율적
int[] primitiveArray = new int[1000];
// 1000개 × 4바이트 = 4,000바이트
// 래퍼 타입 ArrayList - 메모리 오버헤드
ArrayList<Integer> wrapperList = new ArrayList<>();
for (int i = 0; i < 1000; i++) {
wrapperList.add(i); // Auto-boxing 발생
}
// 1000개 × (4바이트 int + 16바이트 Integer 객체) = 약 20,000바이트
// 성능 차이 예시
long start = System.nanoTime();
int sum1 = 0;
for (int i = 0; i < primitiveArray.length; i++) {
sum1 += primitiveArray[i]; // 직접 접근
}
long primitiveTime = System.nanoTime() - start;
start = System.nanoTime();
int sum2 = 0;
for (int i = 0; i < wrapperList.size(); i++) {
sum2 += wrapperList.get(i); // Auto-unboxing 발생
}
long wrapperTime = System.nanoTime() - start;
System.out.println("기본형 배열 시간: " + primitiveTime + "ns");
System.out.println("래퍼 ArrayList 시간: " + wrapperTime + "ns");
}
}
- 선택 기준
- 대량의 숫자 데이터 처리 시 기본형 배열 권장
- 크기가 고정되어 있고 성능이 중요한 경우 기본형 배열 사용
- 동적 크기 조정이 필요하고 메모리 오버헤드가 허용되는 경우 ArrayList 사용
- 고성능 연산이 필요한 경우 기본형 배열이나 전용 라이브러리 (Trove, FastUtil 등) 고려
상세 비교 예제
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
import java.util.*;
public class PerformanceComparison {
public static void main(String[] args) {
int size = 100000;
// ArrayList vs LinkedList 성능 비교
// 리스트 끝에 요소 추가 성능 비교
long start = System.currentTimeMillis();
ArrayList<Integer> arrayList = new ArrayList<>();
for (int i = 0; i < size; i++) {
arrayList.add(i);
}
long arrayListAddTime = System.currentTimeMillis() - start;
start = System.currentTimeMillis();
LinkedList<Integer> linkedList = new LinkedList<>();
for (int i = 0; i < size; i++) {
linkedList.add(i);
}
long linkedListAddTime = System.currentTimeMillis() - start;
System.out.println("=== 끝에 추가 성능 ===");
System.out.println("ArrayList: " + arrayListAddTime + "ms");
System.out.println("LinkedList: " + linkedListAddTime + "ms");
// 랜덤 위치 접근 성능 비교
Random random = new Random();
start = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
arrayList.get(random.nextInt(size));
}
long arrayListGetTime = System.currentTimeMillis() - start;
start = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
linkedList.get(random.nextInt(size));
}
long linkedListGetTime = System.currentTimeMillis() - start;
System.out.println("\n=== 랜덤 접근 성능 ===");
System.out.println("ArrayList: " + arrayListGetTime + "ms");
System.out.println("LinkedList: " + linkedListGetTime + "ms");
// 리스트 앞쪽에 요소 삽입 성능 비교
start = System.currentTimeMillis();
for (int i = 0; i < 1000; i++) {
arrayList.add(0, i);
}
long arrayListInsertTime = System.currentTimeMillis() - start;
start = System.currentTimeMillis();
for (int i = 0; i < 1000; i++) {
linkedList.addFirst(i);
}
long linkedListInsertTime = System.currentTimeMillis() - start;
System.out.println("\n=== 앞에서 삽입 성능 ===");
System.out.println("ArrayList: " + arrayListInsertTime + "ms");
System.out.println("LinkedList: " + linkedListInsertTime + "ms");
}
}
사용 시나리오
배열을 사용하는 경우
- 크기가 고정되어 있을 때
- 요일, 월별 데이터 등 크기가 명확한 경우
- 메모리 효율성이 중요한 임베디드 시스템
- 빠른 접근이 필요할 때
- 인덱스를 통한 빈번한 데이터 접근
- 순차적인 데이터 처리
- 메모리가 제한적일 때
- 추가 오버헤드 없이 순수 데이터만 저장
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
// 배열 사용 예시
public class ArrayUseCases {
// 고정된 크기의 데이터
private static final String[] DAYS_OF_WEEK = {
"월", "화", "수", "목", "금", "토", "일"
};
// 행렬 연산
public static int[][] multiplyMatrix(int[][] a, int[][] b) {
int rows = a.length;
int cols = b[0].length;
int[][] result = new int[rows][cols];
for (int i = 0; i < rows; i++) {
for (int j = 0; j < cols; j++) {
for (int k = 0; k < a[0].length; k++) {
result[i][j] += a[i][k] * b[k][j];
}
}
}
return result;
}
}
ArrayList를 사용하는 경우
- 크기가 가변적일 때
- 사용자 입력에 따라 데이터가 증가/감소하는 경우
- 빈번한 조회가 필요할 때
- 인덱스를 통한 빠른 접근이 중요한 경우
- 끝에서 주로 삽입/삭제할 때
- 스택(Stack) 구현
- 로그 수집 등
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
import java.util.ArrayList;
public class ArrayListUseCases {
// 사용자 목록 관리
public static class UserManager {
private ArrayList<String> users = new ArrayList<>();
public void addUser(String user) {
users.add(user); // O(1) - 끝에 추가
}
public String getUser(int index) {
return users.get(index); // O(1) - 빠른 접근
}
public int getUserCount() {
return users.size();
}
}
// 동적 데이터 수집
public static ArrayList<Integer> collectPrimes(int max) {
ArrayList<Integer> primes = new ArrayList<>();
for (int i = 2; i <= max; i++) {
if (isPrime(i)) {
primes.add(i);
}
}
return primes;
}
private static boolean isPrime(int n) {
if (n < 2) return false;
for (int i = 2; i * i <= n; i++) {
if (n % i == 0) return false;
}
return true;
}
}
LinkedList를 사용하는 경우
- 빈번한 삽입/삭제가 필요할 때
- 중간 위치에서 자주 삽입/삭제 발생
- 큐(Queue) 또는 덱(Deque) 구현
- 순차 접근만 필요할 때
- 처음부터 끝까지 순회하는 경우
- 메모리를 동적으로 할당하고 싶을 때
- 필요한 만큼만 메모리 사용
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
import java.util.LinkedList;
public class LinkedListUseCases {
// LRU 캐시 구현
public static class LRUCache<K, V> {
private LinkedList<K> accessOrder = new LinkedList<>();
private int capacity;
public LRUCache(int capacity) {
this.capacity = capacity;
}
public void access(K key) {
accessOrder.remove(key); // O(n) 탐색 + O(1) 삭제
accessOrder.addFirst(key); // O(1) 앞에 추가
if (accessOrder.size() > capacity) {
accessOrder.removeLast(); // O(1) 뒤에서 삭제
}
}
}
// 작업 큐 구현
public static class TaskQueue {
private LinkedList<String> tasks = new LinkedList<>();
public void addTask(String task) {
tasks.addLast(task); // O(1)
}
public String getNextTask() {
return tasks.isEmpty() ? null : tasks.removeFirst(); // O(1)
}
public boolean hasTasks() {
return !tasks.isEmpty();
}
}
}
선택 가이드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
public class DataStructureSelector {
public static void main(String[] args) {
// 배열 사용
// - 크기 고정, 빠른 접근 필요
int[] fixedSizeData = new int[100];
// ArrayList 사용 (일반적으로 가장 많이 사용)
// - 크기 가변, 빈번한 조회, 끝에서 추가/삭제
ArrayList<String> dynamicList = new ArrayList<>();
// LinkedList 사용
// - 앞/뒤에서 빈번한 삽입/삭제
// - Queue, Deque 인터페이스 구현 필요
LinkedList<Integer> queue = new LinkedList<>();
queue.addFirst(1); // 앞에 추가
queue.addLast(2); // 뒤에 추가
queue.removeFirst(); // 앞에서 삭제
// 주의: 대부분의 경우 ArrayList가 LinkedList보다 성능이 좋음
// LinkedList는 특수한 상황(Queue/Deque)에서만 사용 권장
}
}
활용 팁
Java에서의 선택 기준
- 대부분의 경우: ArrayList 사용
- 일반적인 상황에서 ArrayList가 LinkedList보다 성능이 우수함
- 메모리 효율성과 캐시 지역성이 뛰어남
- 끝에서의 추가/삭제도 충분히 빠름
- 특수한 경우에만 LinkedList 사용
- Queue, Deque 인터페이스 구현이 필요한 경우
- 양쪽 끝에서 빈번한 삽입/삭제가 발생하는 경우
성능 최적화
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
import java.util.*;
public class OptimizationTips {
// ArrayList 초기 용량 설정
public static void tip1_setInitialCapacity() {
// 나쁜 예: 기본 용량(10)으로 시작, 여러 번 확장 발생
ArrayList<Integer> list1 = new ArrayList<>();
for (int i = 0; i < 10000; i++) {
list1.add(i);
}
// 좋은 예: 초기 용량 설정으로 확장 비용 제거
ArrayList<Integer> list2 = new ArrayList<>(10000);
for (int i = 0; i < 10000; i++) {
list2.add(i);
}
}
// 상황에 맞는 자료구조 선택
public static void tip2_chooseRightStructure() {
// 빈번한 검색: ArrayList 사용
ArrayList<String> searchList = new ArrayList<>();
searchList.add("item1");
boolean found = searchList.contains("item1"); // O(n)이지만 캐시 효율 좋음
// 양쪽 끝 삽입/삭제: LinkedList 사용
LinkedList<String> queue = new LinkedList<>();
queue.addFirst("front");
queue.addLast("back");
queue.removeFirst();
// 중복 제거 필요: Set 사용
HashSet<String> uniqueItems = new HashSet<>();
uniqueItems.add("item1");
uniqueItems.add("item1"); // 중복 자동 제거
}
// List 순회 방법
public static void tip3_iterationMethods() {
ArrayList<Integer> list = new ArrayList<>();
for (int i = 0; i < 1000; i++) {
list.add(i);
}
// ArrayList: 인덱스 기반 순회 또는 향상된 for문
for (int i = 0; i < list.size(); i++) {
int value = list.get(i); // O(1)
}
// 모든 List: 향상된 for문 (가장 권장)
for (Integer value : list) {
// 처리
}
// Stream API (Java 8+)
list.stream()
.filter(x -> x % 2 == 0)
.forEach(System.out::println);
}
// 배열과 List 간 변환
public static void tip4_arrayListConversion() {
// 배열 → List
String[] array = {"a", "b", "c"};
List<String> list1 = Arrays.asList(array); // 고정 크기 리스트
List<String> list2 = new ArrayList<>(Arrays.asList(array)); // 가변 크기 리스트
// List → 배열
ArrayList<String> list = new ArrayList<>();
list.add("x");
list.add("y");
String[] newArray = list.toArray(new String[0]);
}
}
결론
- 배열은 고정 크기와 연속 메모리 할당으로 빠른 접근과 메모리 효율성을 제공함
- ArrayList는 동적 크기 조정이 가능하면서도 배열의 장점인 빠른 접근 속도를 유지함
- LinkedList는 삽입/삭제가 빈번한 경우에 유리하지만, 일반적인 상황에서는 ArrayList보다 느림
- 대부분의 상황에서는 ArrayList를 사용하는 것이 권장됨
- 자료 구조의 특성을 이해하고 상황에 맞게 선택하는 것이 성능 최적화의 핵심임
- 초기 용량 설정, 올바른 순회 방법 사용 등 작은 최적화가 큰 성능 차이를 만들 수 있음