3장에서 다루는 내용
- 성능과 DB의 관계
- 인덱스 설계 전략
- 조회 성능 개선 방법
- 주의사항
성능과 DB의 관계
성능에 핵심인 DB
- 성능 문제의 대부분은 DB에서 기인함
- 비효율적 쿼리 한 개가 서비스 전체 성능을 저하시킬 수 있음
- DB 장애는 연쇄적으로 다른 서비스에 영향을 끼침
- DB는 수평 확장에 한계가 있어 쿼리 최적화가 필수임
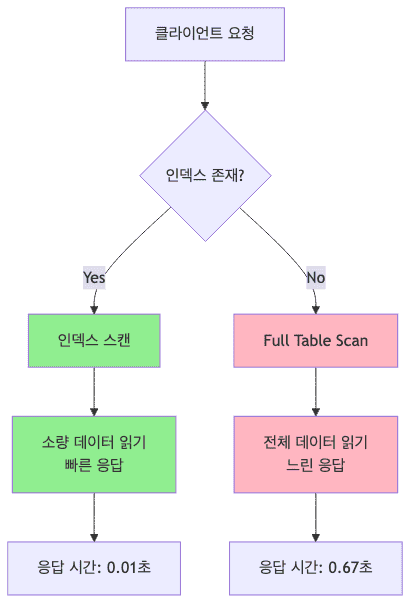
Full Scan의 문제
- 인덱스 없이 데이터를 조회하면 테이블 전체를 읽어야 함
- ex)
- 풀 스캔시 10,000건 조회 시 0.67초 소요
- 인덱스 사용 시 0.01초로 67배 빠름
- 데이터가 10억 건을 넘으면 Full Scan은 실질적으로 불가능함
- 서비스 장애로 이어질 수 있는 치명적인 성능 병목
Full Scan이 발생하는 경우
WHERE절에 사용된 칼럼에 인덱스가 없는 경우- 인덱스는 있지만 함수나 연산을 칼럼에 적용한 경우
WHERE YEAR(regdt) = 2024(인덱스 미사용)WHERE regdt >= '2024-01-01' AND regdt < '2025-01-01'(인덱스 사용)
OR조건 사용 시 일부 칼럼에만 인덱스가 있는 경우LIKE '%keyword%'같은 중간 일치 검색- 앞자리 와일드카드는 인덱스 사용 불가
LIKE 'keyword%'는 인덱스 사용 가능
- 조회하는 데이터 양이 전체의 20% 이상일 때 옵티마이저가 Full Scan 선택 가능
- 옵티마이저
- DB가 쿼리 실행 시 가장 효율적인 방법을 자동 선택하는 시스템
- 데이터가 많으면 인덱스보다 Full Scan이 더 빠를 수 있음
- 옵티마이저
인덱스 설계 전략
조회 트래픽을 고려한 인덱스 설계
- 애플리케이션 요청 수 급증 시 즉각 대응이 어려움
- DB 샤딩이나 스케일 아웃에는 시간과 비용이 많이 듦
- 트래픽이 많은 서비스에서 인덱스 설계는 필수
- 인덱스 개념
- 원하는 데이터를 빠르게 찾기 위한 자료구조
- B-Tree 구조로 특정 키 값에 대한 데이터 위치를 저장
- 조회 성능은 향상되지만 쓰기 비용이 증가함
-
인덱스 적용 예시
category칼럼에 인덱스를 추가하면 특정 카테고리 조회 시 Full Scan 없이 빠르게 접근 가능- 10억 건 데이터에서 1,000건 조회 시
- 인덱스 없을 경우 약 수십 초 소요
- 인덱스 있을 경우 약 0.01초 소요
- 카테고리별 조회가 빈번한 서비스에서 인덱스는 필수적임
1 2
select id, categoryId, authorId, title from post where categoryId = 5 order by id desc limit 20;
단일 인덱스와 복합 인덱스

- 단일 인덱스
- 하나의 칼럼에만 인덱스 생성
userId단일 인덱스만 있으면 해당 사용자의 모든 데이터를 읽어야 함- 특정 사용자의 8,000건 중 특정 날짜 데이터가 3건만 있어도 8,000건 전부 읽게 됨
- 장점
- 구현이 단순함
- 관리가 쉬움
- 단일 조건 조회에 효과적
- 단점
- 복합 조건 조회 시 비효율적
- 불필요한 데이터까지 읽어야 함
- 권장 상황
- 단일 칼럼으로만 조회하는 경우
- 선택도가 매우 높은 unique 칼럼 (이메일, 전화번호)
- 테이블 크기가 작은 경우
-
복합 인덱스
- 여러 칼럼을 조합한 인덱스
(userId, eventDate)복합 인덱스 사용 시 정확히 3건만 조회-
5천만 건 데이터에서도 밀리초 단위로 응답 가능
1 2 3 4
select eventDate, eventType, count(*) as cnt from userEvent where userId = 456 and eventDate = '2024-08-15' group by eventType;
- 장점
- 복합 조건 조회 시 성능 극대화
- 필요한 데이터만 정확히 읽음
- 범위 검색과 정렬 동시 최적화 가능
- 단점
- 칼럼 순서에 따라 사용 여부가 결정됨
- 인덱스 크기가 단일 인덱스보다 큼
- 잘못 설계하면 사용되지 않을 수 있음
- 권장 상황
WHERE절에 여러 칼럼이 자주 함께 사용되는 경우- 특정 사용자의 특정 기간 데이터 조회 (userId + date)
- 카테고리별 최신 데이터 조회 (categoryId + createdAt)
- 복합 인덱스 칼럼 순서
- 칼럼 순서가 매우 중요함
(userId, eventDate)인덱스는 userId로 먼저 검색 후 eventDate로 필터링(eventDate, userId)인덱스와는 완전히 다른 성능 특성을 가짐WHERE절에서 앞쪽 칼럼이 없으면 인덱스를 활용할 수 없음
커버링 인덱스
- 쿼리에 필요한 모든 칼럼이 인덱스에 포함되어 있어 실제 데이터 테이블을 읽지 않고 인덱스만으로 쿼리를 완료하는 방식
- 디스크 랜덤 I/O가 발생하지 않아 성능이 비약적으로 향상됨
-
적용 예시
- 인덱스 구성
(email, name)복합 인덱스 생성
- 쿼리
1 2
select email, name from user where email = 'test@example.com';
- 인덱스 구성
- 동작 방식
email로 인덱스 검색name도 이미 인덱스에 포함되어 있음- 테이블 접근 없이 인덱스만으로 결과 반환
- 일반 인덱스 대비 디스크 I/O를 절반 이하로 줄일 수 있음
- 장점
- 테이블 접근 없이 쿼리 완료
- 디스크 랜덤 I/O 제거로 성능 극대화
- 대량 데이터 조회 시에도 빠른 응답
- 단점
- 인덱스 크기가 매우 커질 수 있음
- 쓰기 성능 저하 (모든 칼럼이 인덱스에 포함)
SELECT *쿼리에는 적용 불가
- 권장 상황
- 조회 빈도가 매우 높은 쿼리
SELECT절의 칼럼 수가 적은 경우- 통계/리포트 쿼리 (집계 함수 포함)
- 읽기 전용 또는 읽기 위주의 테이블
- 설계 원칙
SELECT절의 모든 칼럼을 인덱스에 포함WHERE,ORDER BY,GROUP BY절의 칼럼도 고려- 인덱스 크기가 커지면 메모리 사용량 증가하므로 균형 필요
선택도를 고려한 인덱스 칼럼 선택
- 선택도 (Selectivity)
- 칼럼에서 중복되는 값의 비율
- 고유 값 개수 / 전체 데이터 건수
- 선택도가 낮을수록 (고유 값이 많을수록) 인덱스 효율이 높음
- 선택도 낮은 칼럼 예시
type칼럼 (A, B, C 3가지 값)- 전체 40만 건 중 A가 20만 건
- 인덱스를 만들어도 절반의 데이터를 읽어야 함
- 인덱스 효과가 거의 없음
age칼럼 (20~80까지 약 60가지 값)- type보다는 선택도가 높지만 여전히 수천 건씩 묶여 있음
- 단독 인덱스로는 부족함
-
선택도 높은 칼럼 예시
orderStatus칼럼 (READY, CONFIRMED, SHIPPED 3가지 값이지만 READY가 극소수)- 전체 100만 건 중
orderStatus='READY'가 50건만 존재 orderStatus='READY'조회 시 인덱스로 즉시 탐색 가능- 선택도가 높아 인덱스 효율이 매우 좋음
- 전체 100만 건 중
1 2 3
select * from orders where orderStatus = 'READY' order by id desc limit 50;
인덱스는 필요한 만큼만 만들기
- 인덱스의 비용
INSERT,UPDATE,DELETE시 인덱스도 함께 갱신되어야 함- 인덱스가 많으면 쓰기 연산 성능 저하
- 디스크 공간도 추가로 사용함
- 테이블당 최대 5개 미만의 인덱스 권장
- 인덱스 생성 전략
- 사용하지 않는 인덱스는 과감히 제거
- 자주 조회되는 쿼리에만 인덱스 추가
- 쓰기 연산이 많은 테이블은 인덱스 최소화
- 주기적으로 인덱스 사용률 모니터링
EXPLAIN명령어로 쿼리가 의도대로 인덱스를 타는지 반드시 확인
조회 성능 개선 방법
미리 집계하기
- 매번 실시간으로 집계하면 DB 부하가 높음
COUNT,SUM등의 집계 함수는 풀 스캔이 필요할 수 있음- 집계 결과를 미리 계산하여 별도 테이블에 저장하면 응답 시간 대폭 단축
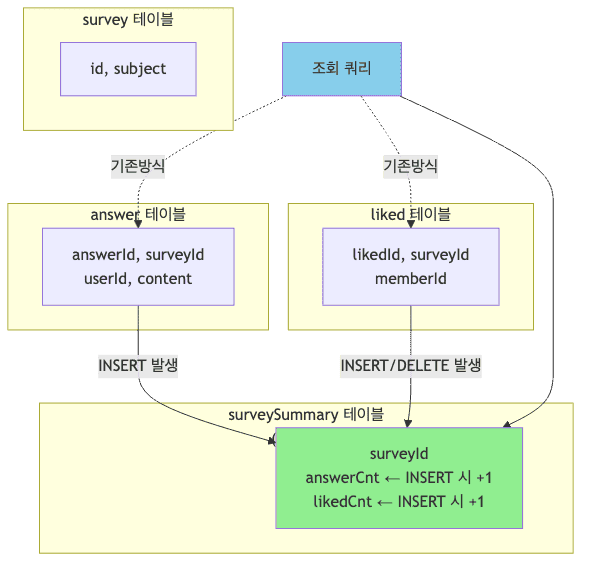
-
미리 집계 구현 방법
- 게시글 통계 시스템 예시
post테이블 - 게시글 기본 정보 저장comment테이블 - 사용자 댓글 데이터postLike테이블 - 좋아요 정보postStats테이블 - 댓글 수, 좋아요 수, 조회 수를 미리 집계
1 2 3 4 5 6 7 8 9 10 11 12
-- 데이터 삽입 시 집계 갱신 insert into comment (postId, userId, content) values (100, 5, '좋은 글입니다'); update postStats set commentCnt = commentCnt + 1 where postId = 100; insert into postLike (postId, userId) values (100, 5); update postStats set likeCnt = likeCnt + 1 where postId = 100; -- 조회 쿼리 select id, title, commentCnt, likeCnt, viewCnt from postStats order by id desc limit 20;
- 게시글 통계 시스템 예시
- 서브 쿼리 없이 단순 칼럼 조회로 즉시 응답
- 쓰기 시 약간의 오버헤드가 있지만 조회 성능은 수백 배 향상
페이지 기준 목록 조회
- 페이지 번호 방식 (
LIMIT offset, size)은 offset이 클수록 느려짐 - offset 10,000이면 앞 10,000건을 건너뛰어야 함
- ID 기준 조회 방식을 권장
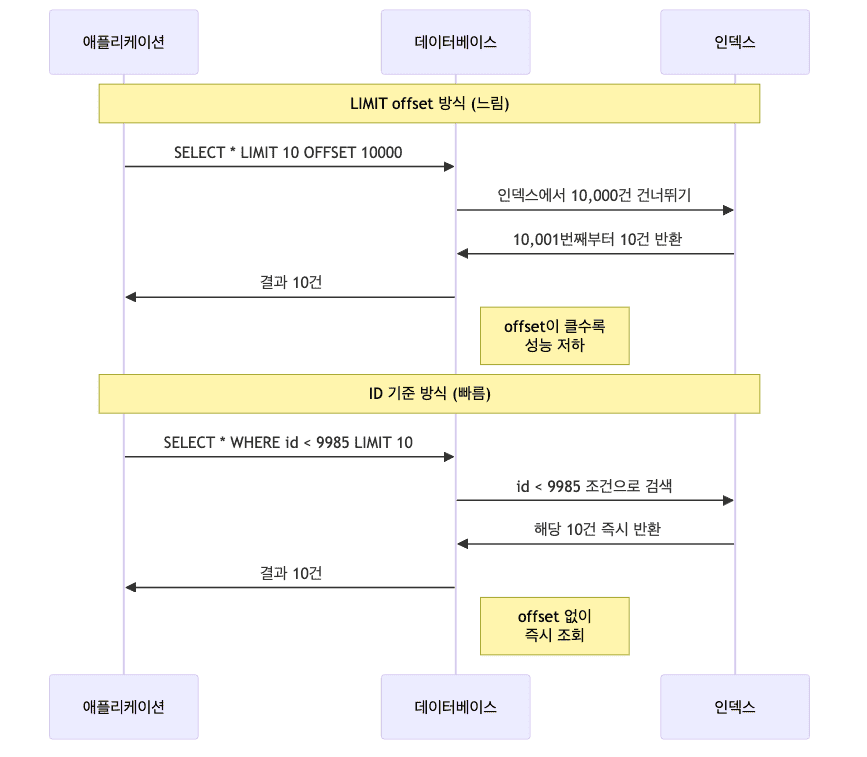
-
LIMIT offset 방식의 문제
1 2 3 4
select id, title, author, createdAt from board order by id desc limit 10 offset 5000;
- 10,000건을 읽고 버린 후 다음 10건 반환
- offset이 클수록 성능 저하
- 페이지 번호가 높아질수록 응답 시간 증가
-
ID 기준 조회 방식
1 2 3 4 5
select id, title, author, createdAt from board where id < 8520 order by id desc limit 10;
- 이전 페이지 마지막 ID를 기준으로 조회
- offset 없이
WHERE조건만으로 탐색
deleted 조건으로 인한 조회량 증가 문제
- deleted 칼럼의 문제
deleted=false조건으로 조회 시 대부분의 데이터를 읽어야 하므로 비효율적deleted칼럼 단독 인덱스는 효과가 거의 없음
-
해결 방법
- 물리적 삭제 방식
- 데이터를 실제 DELETE하여 테이블에서 제거
- 조회 성능 최적화, 테이블 크기 감소
- 삭제 데이터 복구 불가, 감사 추적 어려움
- 임시 데이터, 법적 보존 의무 없는 데이터에 적합
1 2
-- 물리적 삭제 (isDeleted 칼럼 불필요) select * from post order by id desc limit 20;
- 물리적 삭제 방식
-
테이블 분리 방식
-
삭제된 데이터를 별도 테이블로 이동
- 조회 성능 유지하면서 히스토리 데이터 보존
- 삭제 작업 복잡, 스토리지 비용 증가
- 이커머스 주문/결제, 사용자 탈퇴 기록 등에 적합
1 2 3 4
-- 주요 조회 select * from post order by id desc limit 20; -- 삭제된 데이터 조회 select * from post_archive order by id desc limit 20;
-
- 복합 인덱스 활용
(id, deleted)복합 인덱스 구성- 기존 구조 유지 가능, 구현 간단
- 인덱스 크기 증가, 물리적 삭제 대비 성능 낮음
- 레거시 시스템, 삭제 빈도 낮은 데이터에 적합
조회 범위를 시간 기준으로 제한하기
- 전체 기간 데이터 조회는 DB에 큰 부담
- 특정 시간 범위로 한정하여 조회 권장
-
오래된 데이터 조회를 막아 DB 부하 억제
1 2 3 4 5 6
select title, content, regdt from news where regdt >= '2024-08-01 00:00:00' and regdt < '2024-08-10 00:00:00' order by regdt desc limit 100;
regdt칼럼에 인덱스 추가 시 성능 극대화- 최근 데이터 위주로 조회하는 서비스에 효과적
전체 개수 세지 않기
- 페이징 시 전체 개수를
count(*)로 세는 것은 비효율적 - 전체 개수 계산은 모든 데이터를 읽어야 함
-
10억 건 데이터에서 count(*)는 수 초~수십 초 소요
-
대안
- 대략적인 개수만 표시 (약 1천만 건 등)
- 모바일 앱은 “더 보기” 방식으로 전체 개수 미제공
- 검색 엔진도 정확한 전체 개수 대신 대략치만 표시
- 전체 개수가 필수가 아니라면 생략 권장
오래된 데이터 분리 보관하기
-
데이터 파티셔닝
- 과거 데이터와 최신 데이터를 물리적으로 분리
- 조회 빈도가 낮은 데이터를 별도 테이블로 이동
- 메인 테이블 크기 축소로 검색 성능 개선
-
타임라인 삭제
- 3개월 이상 지난 데이터는 삭제하거나 별도 보관
- 데이터 증가로 인한 성능 저하 방지
-
법적 보관 의무가 있는 데이터는 아카이브 테이블로 이동
-
구현 예시
- 100일 이상 지난 activityLog 데이터 삭제
- 3개월 이상 지난 사용자 활동 이력을
activityLog_archive테이블로 이동 - 파티션 기능 활용 시 자동으로 오래된 파티션 제거 가능
-
DML 작업의 영향
- 대량 DML 작업은 시간 분산 필수
- 짧은 시간에 10,000건 이상 삭제 시 락 경합 발생 가능
- 3,000~5,000건씩 나누어 삭제 권장
주의사항
Prepared Statement 사용의 중요성
- 동일한 쿼리를 반복 실행할 때 Prepared Statement 사용 필수
- DB 엔진이 쿼리 실행 계획을 캐싱하여 재사용
- 파싱 오버헤드 제거로 성능 향상
- SQL 인젝션 공격 방어
-
특히 반복문 안에서 쿼리 실행 시 효과가 극대화됨
-
온라인 환경과 배치 환경 구분
- 실시간 트래픽과 배치 작업 분리 권장
- 배치 작업용 DB 읽기 전용 복제본(Read Replica) 활용
- 대량 집계나 통계 작업은 별도 시간대에 실행
- 테이블 단편화와 최적화
- 대량 DELETE/UPDATE 후 테이블 단편화 발생
OPTIMIZE TABLE명령으로 해소 가능하나 서비스 영향 큼- 배치 시간대나 점검 시간에만 실행 권장
쿼리 작성 시 주의 사항
-
타입이 다른 칼럼 조인 주의
- 조인하려는 칼럼의 타입이 다르면 인덱스 사용 불가
-
user.userId(integer)와push.receiverId(varchar) 조인 시 형변환 필요1 2 3 4 5 6
select u.userId, u.name, p.* from user u, push p where u.userId = cast(p.receiverId as char) and p.receiverType = 'MEMBER' order by p.id desc limit 100;
- 명시적 형변환 없이 조인하면 풀 스캔 발생
- 테이블 설계 단계에서 조인 칼럼의 타입 일치 필수
바인드 파라미터 사용하기
- SQL 문자열 직접 조합 대신 바인드 파라미터(
?) 사용 - Prepared Statement로 미리 컴파일하여 재사용
-
성능 향상 및 SQL 인젝션 방어
1 2 3 4 5 6 7 8
-- 비권장: 문자열 직접 조합 (매번 파싱 필요, 보안 위험) select * from accesslog where accessDatetime >= '2024-08-01 00:00:00' -- 권장: 바인드 파라미터 사용 select * from accesslog where accessDatetime >= ? and accessDatetime < ?
배치 쿼리 실행 시간 분산
- 특정 시간대 집중 실행되는 배치 쿼리는 DB 성능에 악영향
- 대량 DELETE는 짧은 시간 내 실행 금지
- 10,000건씩 나누어 삭제
- 각 삭제 사이에 sleep 추가
- 대량 INSERT도 시간 분산 필요
-
한 번에 대량 삽입 대신 여러 배치로 나누어 실행
-
배치 작업 분산 전략
- 새벽 2시에 1회 실행 대신 1시간마다 소량씩 실행
- DB 리소스를 점유적으로 소비하여 서비스 가용성 유지
- 배치 쿼리 실행 시 모니터링 필수
DB 최대 연결 개수 고려
- DB는 최대 연결 수가 제한됨
- API 서버 커넥션 풀 + 배치 서버 연결 = 총 연결 수
-
DB 최대 연결 개수 초과 시 신규 연결 실패
-
계산 예시
- DB 최대 연결이 200개일 경우
- API 서버 10대 × 커넥션 풀 20개 = 200개
- 배치 서버 추가 연결 시 API 서버 연결 실패 가능
- 여유 연결 수 확보 필요
-
주의사항
- API 서버 증설 시 DB 최대 연결 수도 함께 고려
- DB CPU, 메모리 리소스 상한선 확인
- 최대 연결 수 초과 시 신규 요청 실패 또는 대기
-
트랜잭션 범위 최소화

- 외부 API 호출을 트랜잭션 안에 두면 안 됨
-
외부 API 응답 지연 시 DB 커넥션이 오래 점유되어 다른 요청 지연
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
// 잘못된 예: 외부 API가 트랜잭션 안에 있음 @Transactional public void join(JoinRequest join) { memberDao.insert(member); mailClient.sendMail(...); // 트랜잭션 길어짐 } // 올바른 예: 외부 API는 트랜잭션 밖에서 호출 public void join(JoinRequest join) { transactionTemplate.execute(status -> { memberDao.insert(member); return null; }); mailClient.sendMail(...); // 트랜잭션 밖에서 처리 }
- 트랜잭션 설계 원칙
- 트랜잭션 범위는 가능한 짧게 유지
- 외부 호출, 파일 I/O는 트랜잭션 밖에서 처리
- 필요시 보상 트랜잭션 또는 재시도 로직 구현
배운 점
- DB 설계와 인덱스는 서비스 성능의 기반임
- 조회 트래픽이 많은 서비스는 인덱스 설계가 필수
- 복합 인덱스 칼럼 순서가 성능에 큰 영향을 끼침
- 선택도를 고려한 인덱스 설계가 중요함
- 인덱스는 조회 성능을 높이지만 쓰기 비용도 고려해야 함
- 미리 집계하면 조회 성능을 수백 배 향상시킬 수 있음
- LIMIT offset 대신 ID 기준 조회 방식이 효율적
- 전체 개수를 세는 것보다 대략치 표시가 실용적
- 오래된 데이터는 분리 보관하여 성능 유지
- 트랜잭션 범위는 최소화하여 DB 리소스 효율적 사용
- 외부 API 호출은 트랜잭션 밖에서 처리하여 커넥션 낭비 방지
- 대량 배치 작업은 시간 분산하여 DB 부하 최소화
- 바인드 파라미터 사용으로 성능과 보안 동시 확보
- DB 최대 연결 개수를 고려한 시스템 설계 필요