개요
- BigQuery에서 프로세스 관리는 Slot(슬롯) 관리와 쿼리 최적화로 귀결됨
- 전통적인 OS 프로세스 관리 개념 대신, 분산된 연산 자원인 Slot을 효율적으로 배분하고 모니터링하는 것이 핵심임
Slot 개념
Slot이란
- Slot은 BigQuery에서 SQL 쿼리를 실행하는 데 사용되는 가상 CPU(vCPU)와 RAM의 단위임
- 쿼리를 실행하면 BigQuery는 이 작업을 수많은 작은 작업(Stage)으로 쪼개고, 각 작업을 병렬로 처리하기 위해 여러 Slot에 할당함
- 복잡한 쿼리일수록 더 많은 Slot이 필요하며, 사용 가능한 Slot이 부족하면 쿼리는 대기(Queueing) 상태가 되거나 실행 속도가 느려짐
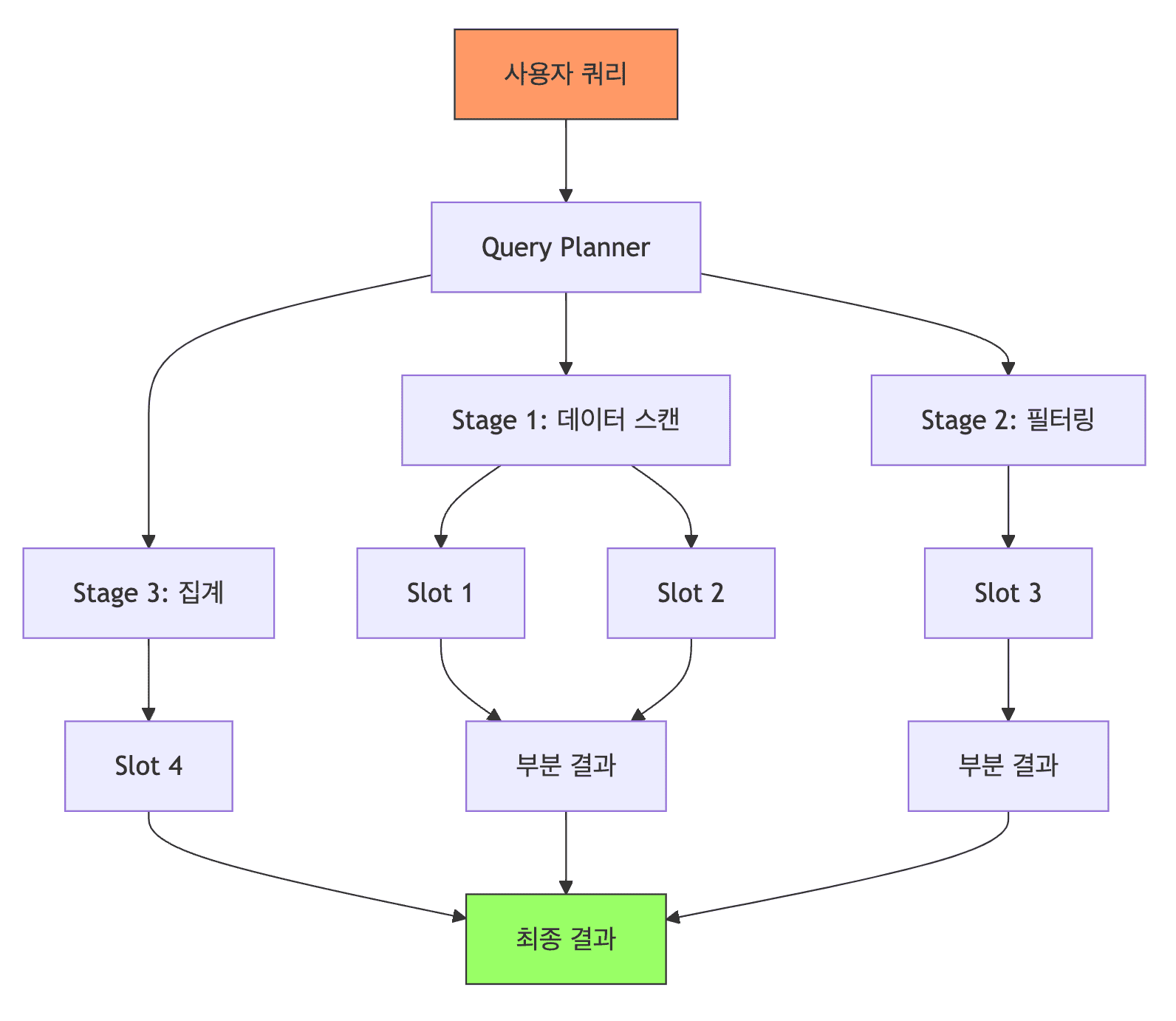
BigQuery 아키텍처 구성
- Colossus (스토리지)
- 데이터가 저장되는 구글의 분산 파일 시스템
- 데이터는 Capacitor라는 컬럼 기반 포맷으로 압축되어 저장됨
- Dremel (컴퓨팅)
- 쿼리를 실행하는 엔진
- 수천 개의 서버에 작업을 분산시켜 Colossus에서 데이터를 읽어와 연산함
- Jupiter (네트워크)
- 이 둘 사이를 초고속(페타비트급) 네트워크로 연결하여, 마치 메모리에서 읽는 것처럼 빠르게 데이터를 전송함
Slot 관리 및 가격 정책
On-Demand (주문형)
-
기본값임
- 방식
- 쿼리가 스캔한 데이터 용량(TB)당 과금 ($6.00/TB)
- Slot 관리
- 구글이 알아서 관리함
- 프로젝트당 최대 2,000 Slot(기본값)까지 순간적으로 빌려줌
- 장점
- 관리가 필요 없고, 쿼리를 안 날리면 비용이 0원
- 단점
- 비용 예측이 어렵고, 대량의 쿼리가 몰리면 Slot 부족으로 속도가 느려질 수 있음
Edition (용량 기반)
-
Standard, Enterprise, Enterprise Plus가 있음
- 방식
- Autoscaling 지원: 최소/최대 슬롯 범위를 설정하면 워크로드에 따라 자동 조정됨
- 사용할 Slot의 용량(Capacity)에 따라 비용을 지불
- Slot 관리
- 사용자가 Reservation(예약)을 생성하여 관리하지만, 실제 할당은 동적으로 이루어짐
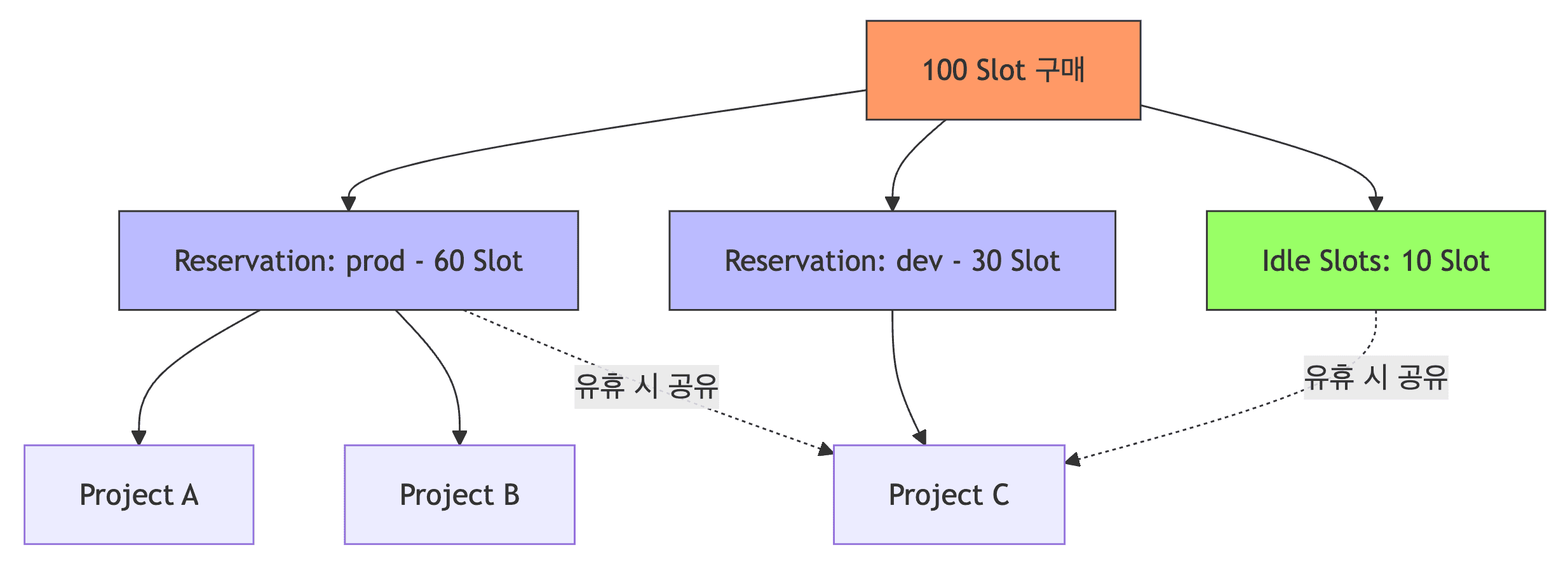
- Reservations (예약)
- 구매한 Slot을 특정 목적(예:
prod,dev,etl)의 버킷으로 나눔
- 구매한 Slot을 특정 목적(예:
- Assignments (할당)
- 특정 프로젝트나 폴더를 위에서 만든 예약에 연결함
- Idle Slot Sharing (유휴 슬롯 공유)
prod예약이 놀고 있을 때dev쿼리가 그 Slot을 가져다 쓸 수 있어 효율적임
프로세스 모니터링
INFORMATION_SCHEMA 활용
-
현재 실행 중이거나 과거에 실행된 쿼리의 상세 정보를 조회할 수 있음
- 실행 중인 쿼리 확인
1 2 3 4 5 6 7 8 9 10 11
SELECT creation_time, project_id, user_email, job_id, priority, state, TIMESTAMP_DIFF(CURRENT_TIMESTAMP(), start_time, SECOND) as running_time_sec FROM `{REGION}-{LOCATION}`.INFORMATION_SCHEMA.JOBS_BY_PROJECT WHERE state != "DONE" ORDER BY running_time_sec DESC;
- 완료되지 않은 모든 프로세스 job 확인
1 2 3
SELECT * FROM `{PROJECT_ID}`.`{REGION_NAME}`.`INFORMATION_SCHEMA`.`JOBS_BY_PROJECT` WHERE STATE != "DONE"
- 완료되지 않은 모든 프로세스 job id 확인
1 2 3
SELECT job_id FROM `{PROJECT_ID}`.`{REGION_NAME}`.`INFORMATION_SCHEMA`.`JOBS_BY_PROJECT` WHERE STATE != "DONE"
- USER별 완료되지 않은 프로세스 job 수 확인
1 2 3
SELECT user_email, count(*) FROM `{PROJECT_ID}`.`{REGION_NAME}`.`INFORMATION_SCHEMA`.`JOBS_BY_PROJECT` WHERE STATE != "DONE" GROUP BY user_email
- 비용이 높은 쿼리 찾기 (최근 7일)
1 2 3 4 5 6 7 8 9
SELECT job_id, user_email, total_bytes_billed, query FROM `{REGION}-{LOCATION}`.INFORMATION_SCHEMA.JOBS_BY_PROJECT WHERE creation_time > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 7 DAY) ORDER BY total_bytes_billed DESC LIMIT 10;
쿼리 우선순위 조정
| Priority | 설명 | 특징 |
|---|---|---|
| Interactive | 대화형 (기본값) | 가능한 한 빨리 실행됨 |
| Batch | 배치 | 유휴 자원이 있을 때 실행됨 24시간 내 실행 보장 Interactive 쿼리의 자원을 뺏지 않음 비용 절감 및 부하 분산에 유용 |
쿼리 취소
-
잘못된 쿼리가 돌고 있다면 CLI나 콘솔에서 강제 종료할 수 있음
- 프로세스 중지
- 주의: SQL(
CALL ...)로는 직접 취소할 수 없음 - BigQuery 콘솔(UI)에서 ‘취소’ 버튼을 누르거나, CLI를 사용해야 함
- 주의: SQL(
- bq CLI 사용
1
bq cancel {JOB_ID}
쿼리 최적화
효율적인 쿼리 작성 가이드
- SELECT * 금지
- 컬럼 기반 저장소이므로 필요한 컬럼만 명시해야 스캔 비용이 줄어듦 ```sql – 비권장 SELECT * FROM orders WHERE created_at = ‘2025-01-01’;
– 권장 SELECT order_id, customer_id, amount FROM orders WHERE created_at = ‘2025-01-01’; ```
- 파티셔닝 & 클러스터링
- 날짜별로 파티셔닝하고, 자주 필터링하는 컬럼(예:
user_id)으로 클러스터링하면 스캔량을 획기적으로 줄일 수 있음 WHERE partition_col = '2025-01-01'조건이 없으면 전체를 다 읽어버리니 주의1 2 3 4
CREATE TABLE orders PARTITION BY DATE(created_at) CLUSTER BY customer_id, region AS SELECT * FROM source_table;
- 날짜별로 파티셔닝하고, 자주 필터링하는 컬럼(예:
- 미리보기 활용
- Tip: 데이터 확인이 목적이면 쿼리하지 말고 테이블 미리보기(Preview) 탭을 사용하세요.
- 쿼리 비용이 무료입니다.
LIMIT를 걸고SELECT *하는 습관은 비용 낭비의 주범입니다.
- LIMIT는 비용 절감 아님
LIMIT 10을 해도 전체 데이터를 스캔할 수 있음- 비용을 줄이려면
WHERE절을 잘 써야 함 ```sql – 비용이 비쌈 (전체 스캔 후 10개만 반환) SELECT * FROM large_table LIMIT 10;
– 비용 절감 (파티션 필터링) SELECT * FROM large_table WHERE DATE(created_at) = ‘2025-01-01’ LIMIT 10; ```
최적화 체크리스트
| 항목 | 설명 | 영향 |
|---|---|---|
| SELECT 컬럼 지정 | 필요한 컬럼만 명시 | 높음 |
| 파티션 필터링 | WHERE 절에 파티션 키 포함 | 높음 |
| 클러스터링 활용 | 자주 필터링하는 컬럼으로 클러스터링 | 중간 |
| 미리보기 사용 | 데이터 확인 시 Preview 탭 활용 | 낮음 |
| Batch 우선순위 | 긴급하지 않은 쿼리는 Batch로 실행 | 중간 |
정리
Slot 관리 요약
- BigQuery 프로세스 관리 = Slot 관리 + 쿼리 튜닝
- On-Demand
- 편하지만 예측 불가능
- Capacity (Editions)
- 예측 가능하고 Slot 공유 기능으로 효율적이지만 관리가 필요
최적화 핵심
- 파티셔닝 필수
SELECT *금지INFORMATION_SCHEMA로 주기적인 모니터링