개요
Scanner와BufferedReader는 입력을 읽는 방식이 다름StringTokenizer와String.split()은 문자열을 분리하는 메커니즘이 다름- 각 방식의 특성을 이해하고 상황에 맞게 선택하는 것이 성능 최적화의 핵심임
전체 프로세스 흐름

- 입력 단계
BufferedReader- 빠름/수동 파싱 필요
Scanner- 느림/자동 형변환 제공
- 파싱 단계
StringTokenizer- 메모리 효율적/빠름
String.split()- 유연함/배열 할당
- 출력 단계
StringBuilder- 일괄 출력/최상의 성능
BufferedWriter- 버퍼 출력/우수한 성능
println- 동기화 출력/성능 저하
Scanner와 BufferedReader
Scanner의 특징
- 메커니즘
InputStream을 감싸서 한 글자씩 읽으면서 내부에서 정규식 기반 토큰화와 타입 파싱까지 처리함- 버퍼 크기가 작음 (약 1KB)
- 매 입력마다 정규식 파싱과 토큰화가 발생
- 타입 변환
nextInt(),nextLong(),nextDouble()등 다양한 타입으로 직접 읽기 가능- 자동 형변환 제공
- 개발자가 직접 파싱할 필요 없음
- 성능
- 버퍼가 작고 정규식 처리로 인해 상대적으로 느림
- 같은 데이터양에서
BufferedReader대비 수배 이상 느릴 수 있음
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
import java.util.Scanner;
public class ScannerExample {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
// 정수 입력
int n = sc.nextInt();
// 실수 입력
double d = sc.nextDouble();
// 문자열 입력
String str = sc.next(); // 공백 전까지
String line = sc.nextLine(); // 한 줄 전체
sc.close();
}
}
Scanner 사용 시 주의사항
- 버퍼 찌꺼기 문제
nextInt(),next(),nextDouble()등 사용 후nextLine()호출 시 문제 발생- 이전 메서드가 개행 문자(
\n)를 버퍼에 남김 nextLine()이 남은 개행 문자만 읽고 종료되어 입력 무시
- 문제 예시
1
2
3
Scanner sc = new Scanner(System.in);
int n = sc.nextInt(); // "5\n" 입력 시 5만 읽고 \n은 버퍼에 남음
String line = sc.nextLine(); // 남은 \n만 읽어서 빈 문자열 반환
- 해결 방법
- 방법 1
nextInt()후nextLine()을 한 번 더 호출하여 버퍼 비우기
- 방법 2
- 모든 입력을
nextLine()으로 받은 후Integer.parseInt()사용
- 모든 입력을
- 방법 3 (권장)
BufferedReader사용으로 근본적인 문제 회피
- 방법 1
1
2
3
4
5
6
7
8
9
10
// 해결 방법 1
Scanner sc = new Scanner(System.in);
int n = sc.nextInt();
sc.nextLine(); // 버퍼 비우기
String line = sc.nextLine(); // 정상 입력
// 해결 방법 2 (권장)
Scanner sc = new Scanner(System.in);
int n = Integer.parseInt(sc.nextLine());
String line = sc.nextLine();
BufferedReader의 특징
- 메커니즘
Reader를 감싸서 버퍼를 채운 뒤 한 줄 단위로 문자열을 읽어옴- 버퍼 크기가 큼 (기본 8KB)
- 한 번에 많은 데이터를 읽어 메모리에 저장
- 타입 변환
readLine()으로 항상String만 반환- 숫자로 사용하려면 직접 파싱 필요
Integer.parseInt()Double.parseDouble()등
- 성능
- 8KB 버퍼로 한 번에 많이 읽어 입출력 횟수 감소
- 대용량 입출력에서
Scanner보다 훨씬 빠름 - 문자열 파싱을 개발자가 명시적으로 수행
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.IOException;
public class BufferedReaderExample {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
// 한 줄 읽기
String line = br.readLine();
// 정수로 변환
int n = Integer.parseInt(br.readLine());
// 실수로 변환
double d = Double.parseDouble(br.readLine());
br.close();
}
}
Scanner와 BufferedReader 비교
| 특징 | Scanner | BufferedReader |
|---|---|---|
| 버퍼 크기 | 약 1KB | 기본 8KB |
| 입력 방식 | 정규식 기반 토큰화 | 한 줄 단위 문자열 |
| 타입 변환 | 자동 (nextInt() 등) |
수동 (parseInt() 등) |
| 예외 처리 | 내부에서 예외 숨김 | IOException 처리 필수 |
| 성능 | 느림 | 빠름 |
| 사용 편의성 | 높음 | 보통 |
| 대용량 처리 | 부적합 | 적합 |
예외 처리 차이
Scanner의 예외 처리- 내부적으로 예외를 숨김
InputMismatchException등을 런타임에 던지지만 컴파일 타임에는 체크하지 않음- 입력 오류 발생 시 조용히 실패하거나 예외 던짐
- 간단한 프로그램에서는 편리하지만 예외 처리 누락 위험
BufferedReader의 예외 처리IOExceptionchecked exception 강제- 컴파일 타임에 예외 처리를 강제하여 안정성 증가
throws IOException또는 try-catch 블록 필수- 명시적 예외 처리로 더 안전한 코드 작성 가능
스레드 안전성 비교
BufferedReader의 스레드 안전성- 내부적으로
lock객체를 사용하여 동기화 처리 - 멀티스레드 환경에서 하나의 리더 객체를 여러 스레드가 공유해도 안전
- 임계 영역에 대한 동기화 보장
- 서버 사이드 개발에서 동시성 문제 방지
- 내부적으로
Scanner의 스레드 안전성- 동기화되지 않은 설계
- 멀티스레드 환경에서 경쟁 상태 발생 가능
- 스레드별로 별도의 인스턴스 생성 필요
- 단일 스레드 기반의 단순 작업에 최적화
입력 처리 메커니즘
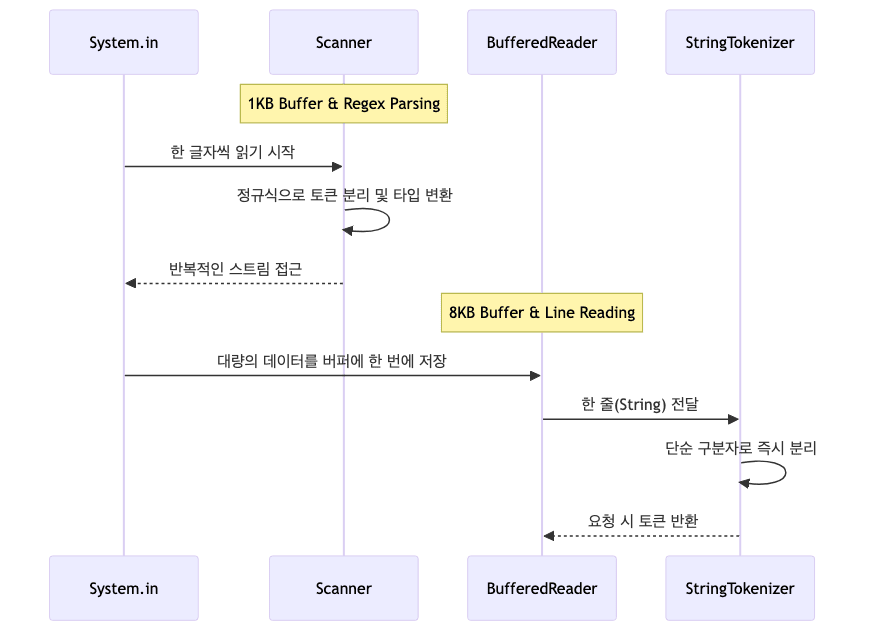
Scanner의 처리 방식- 1KB 버퍼로 한 글자씩 읽기 시작
- 정규식으로 토큰 분리 및 타입 변환
- 반복적인 스트림 접근으로 성능 저하
BufferedReader의 처리 방식- 8KB 버퍼에 대량의 데이터를 한 번에 저장
- 한 줄 단위로
String전달 StringTokenizer는 단순 구분자로 즉시 분리- 요청 시에만 토큰 반환
주의사항
Scanner사용 시 주의점Scanner(System.in)사용 후close()호출 시 문제 발생- 표준 입력 스트림(
System.in) 자체가 닫힘 - 프로그램 내 다른 곳에서 더 이상 입력을 받을 수 없게 됨
- 표준 입력 스트림(
- 해결 방법
Scanner를 닫지 않고 프로그램 종료 시 자동으로 정리되도록 함- 또는 try-with-resources 사용 시 주의
- Java 버전별 차이
- Java 21 이상에서
Scanner성능 일부 개선 - 여전히
BufferedReader와의 격차는 존재 - 대용량 입력 처리 시
BufferedReader권장
- Java 21 이상에서
사용 시나리오
Scanner를 사용하는 경우- 간단한 콘솔 입력
- 입력량이 작고 성능 요구가 높지 않을 때
- 다양한 타입을 편하게 읽고 싶을 때
- 학습 목적이나 간단한 테스트 코드
BufferedReader를 사용하는 경우- 코딩 테스트처럼 입력이 크고 속도가 중요한 상황
- 파일이나 네트워크에서 대량 텍스트를 읽어올 때
- 시간 제한이 타이트한 알고리즘 문제
StringTokenizer와 String.split()
StringTokenizer의 특징
- 메커니즘
- 문자열을 단일 구분자 기준으로 토큰으로 분리
- 내부 구현이 단순함
nextToken()을 호출할 때마다 다음 토큰을 하나씩 반환Iterator스타일의 동작 방식
- 구분자 처리
- 단순한 문자 또는 문자열만 구분자로 사용 가능
- 정규식 미지원
- 빈 문자열 처리
- 빈 문자열을 토큰으로 취급하지 않음
- 연속 구분자 사이 값이 없으면 건너뜀
- 성능
- 단순한 구조로
String.split()보다 약 2배 빠름 - 정규식 파싱 비용 없음
- 단순한 구조로
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
import java.util.StringTokenizer;
public class StringTokenizerExample {
public static void main(String[] args) {
String input = "10 20 30 40 50";
// 공백 구분자로 토큰 분리
StringTokenizer st = new StringTokenizer(input);
while (st.hasMoreTokens()) {
String token = st.nextToken();
System.out.println(token);
}
// 다른 구분자 지정
String csv = "apple,banana,orange";
StringTokenizer st2 = new StringTokenizer(csv, ",");
while (st2.hasMoreTokens()) {
System.out.println(st2.nextToken());
}
}
}
String.split()의 특징
- 메커니즘
- 문자열을 정규식(Regex) 기준으로 분리
- 문자열 배열(
String[])을 한 번에 반환 - 정규식 엔진 사용으로 내부 처리가 복잡함
- 구분자 처리
- 정규식 패턴 사용 가능
- 복잡한 패턴 매칭 지원
- 여러 구분자를 한 번에 처리 가능
- 빈 문자열 처리
- 빈 문자열도 토큰으로 포함
limit옵션으로 빈 값 처리 방식 조정 가능
- 성능
- 정규식 파싱 비용으로
StringTokenizer보다 느림 - 복잡한 패턴 분리에는 필수적
- 정규식 파싱 비용으로
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
public class StringSplitExample {
public static void main(String[] args) {
String input = "10 20 30 40 50";
// 공백 구분자로 분리
String[] tokens = input.split(" ");
for (String token : tokens) {
System.out.println(token);
}
// 정규식 사용
String complex = "apple,banana;orange:grape";
String[] fruits = complex.split("[,;:]");
for (String fruit : fruits) {
System.out.println(fruit);
}
// 빈 문자열 처리
String empty = "a,,b,,c";
String[] result = empty.split(",");
// 결과: ["a", "", "b", "", "c"]
}
}
StringTokenizer와 String.split() 비교
| 특징 | StringTokenizer | String.split() |
|---|---|---|
| 반환 타입 | Iterator 방식 (토큰 하나씩) | 배열 (String[]) |
| 구분자 | 단순 문자/문자열 | 정규식 패턴 |
| 빈 문자열 | 건너뜀 | 포함됨 |
| 성능 | 빠름 (약 2배) | 느림 |
| 유연성 | 낮음 | 높음 |
| 복잡한 패턴 | 불가능 | 가능 |
메모리 효율성 비교
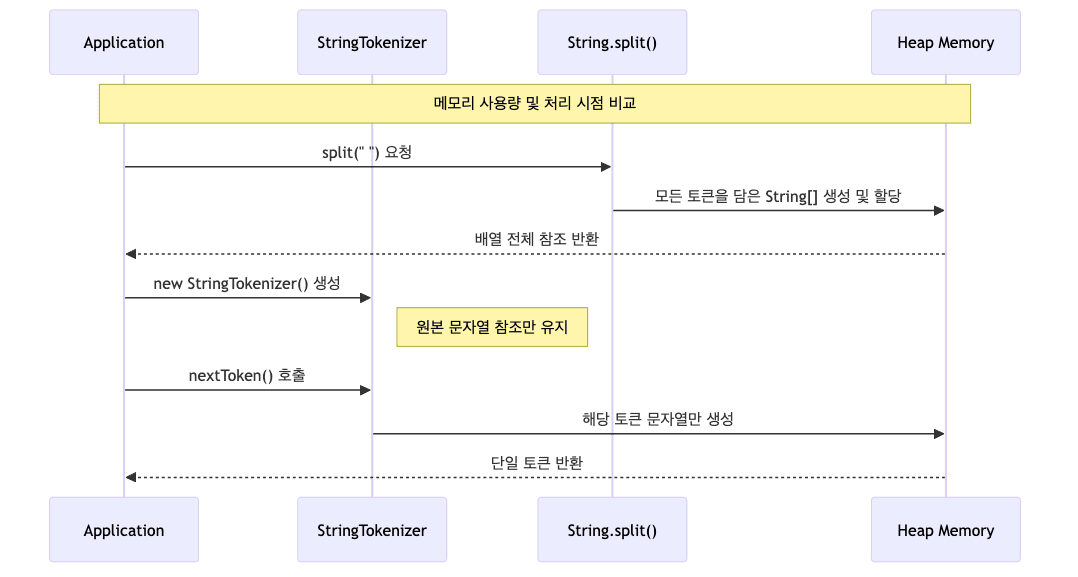
StringTokenizer의 지연 처리 방식- 열거형(
Enumeration) 패턴과 유사하게 동작 nextToken()호출 시점에만 원본 문자열 탐색- 필요한 시점에 토큰을 하나씩 추출
- 분리된 결과를 저장하기 위한 별도의 큰 배열 생성하지 않음
- 메모리 사용량이 적고 효율적
- 대용량 데이터 처리 시 유리
- 열거형(
String.split()의 즉시 할당 방식- 정규식으로 문자열 분리 후 모든 결과를
String[]배열에 담아 반환 - 배열 전체가 메모리에 한 번에 할당됨
- 입력 데이터가 수백만 건 이상일 경우 문제 발생 가능
- 커다란 배열 객체가 메모리에 한 번에 올라감
OutOfMemoryError위험 증가
- 메모리가 제한적인 환경에서 가비지 컬렉터 부하 증가
- 정규식 컴파일 비용 추가 발생
- 정규식으로 문자열 분리 후 모든 결과를
- 정규식 컴파일 비용
String.split()은 호출될 때마다 정규식 컴파일- 반복문 내에서 빈번하게 사용 시 성능 하락의 주요 원인
- 동일한 패턴 반복 사용 시
Pattern.compile()사용 권장
- Java 8 이후 최적화
- 단일 문자를 구분자로 사용할 경우 Fast-path 최적화 적용
- 예시
split(" ")또는split(",")등 단일 문자- 정규식 엔진을 거치지 않고 빠른 경로로 처리
- 복잡한 정규식 패턴에는 여전히 정규식 엔진 사용
- 성능 차이
- 단일 문자 구분자
- Fast-path로
StringTokenizer와 성능 격차 감소
- Fast-path로
- 복잡한 패턴
- 여전히 정규식 컴파일 비용 발생
- 단일 문자 구분자
String.split() 사용 시 주의사항
- 정규식 메타 문자 이스케이프 필요
- 특수 문자를 구분자로 사용 시 백슬래시(
\\) 이스케이프 처리 필수 - 정규식 메타 문자 목록
- 특수 문자를 구분자로 사용 시 백슬래시(
1
2
3
. (점) * (별표) + (플러스) ? (물음표)
^ (캐럿) $ (달러) { } (중괄호)
[ ] (대괄호) ( ) (소괄호) | (파이프) \ (백슬래시)
- 잘못된 사용 예시
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
// 잘못된 사용 - 의도와 다르게 동작
String text = "a.b.c";
String[] parts = text.split("."); // 모든 문자를 구분자로 인식
// 결과: 빈 배열 또는 예상치 못한 결과
String data = "a|b|c";
String[] items = data.split("|"); // 빈 문자열로 분리됨
// 결과: ["a", "|", "b", "|", "c"]
String count = "1+2+3";
String[] nums = count.split("+"); // + 는 수량자로 인식됨
// 결과: PatternSyntaxException 또는 예상치 못한 결과
String pattern = "a*b*c";
String[] parts2 = pattern.split("*"); // * 는 수량자로 인식됨
// 결과: PatternSyntaxException
- 올바른 사용 방법
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
// 올바른 사용 - 이스케이프 처리
String text = "a.b.c";
String[] parts = text.split("\\."); // 점(.)을 이스케이프
// 결과: ["a", "b", "c"]
String data = "a|b|c";
String[] items = data.split("\\|"); // 파이프(|)를 이스케이프
// 결과: ["a", "b", "c"]
String count = "1+2+3";
String[] nums = count.split("\\+"); // 플러스(+)를 이스케이프
// 결과: ["1", "2", "3"]
String pattern = "a*b*c";
String[] parts2 = pattern.split("\\*"); // 별표(*)를 이스케이프
// 결과: ["a", "b", "c"]
- 성능 영향
- 메타 문자를 구분자로 사용하면 Fast-path 최적화 미적용
- 단일 문자라도 정규식 엔진을 거치게 되어 성능 저하
- 간단한 구분자는
StringTokenizer사용 권장
사용 시나리오
StringTokenizer를 사용하는 경우- 공백이나 콤마 등 단순한 구분자 하나로 빠르게 토큰 분할
- 알고리즘 문제에서
BufferedReader와 함께 빠른 입력 처리 - 성능이 중요하고 구분자가 단순한 경우
String.split()을 사용하는 경우- 정규식이 필요한 복잡한 패턴 분리
- 여러 종류의 구분자 처리
- 한 번에 배열로 받아서 컬렉션으로 변환하는 경우
- 빈 문자열 처리가 필요한 경우
조합별 활용 가이드
Scanner + 내부 토큰화
- 특징
- 가장 간단한 방식
- 코드 작성이 편리함
- 성능
- 가장 느림
- 적합한 상황
- 소규모 테스트 코드
- 학습용 프로그램
- 입력량이 매우 적은 경우
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import java.util.Scanner;
public class ScannerSimple {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int n = sc.nextInt();
int[] arr = new int[n];
for (int i = 0; i < n; i++) {
arr[i] = sc.nextInt();
}
sc.close();
}
}
BufferedReader + StringTokenizer
- 특징
- 코딩 테스트의 기본 조합
- 빠른 입력과 간단한 토큰 분리
- 성능
- 매우 빠름
- 적합한 상황
- 코딩 테스트 (백준, 프로그래머스 등)
- 대량 입력 처리
- 시간 제한이 타이트한 문제
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import java.io.*;
import java.util.StringTokenizer;
public class FastInput {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int n = Integer.parseInt(br.readLine());
StringTokenizer st = new StringTokenizer(br.readLine());
int[] arr = new int[n];
for (int i = 0; i < n; i++) {
arr[i] = Integer.parseInt(st.nextToken());
}
br.close();
}
}
BufferedReader + String.split()
- 특징
- 입력은 빠르지만 토큰 분리는 유연함
- 성능
- 빠름 (
StringTokenizer보다는 느림)
- 빠름 (
- 적합한 상황
- 입력량이 크고 토큰 패턴이 복잡한 경우
- 정규식이 필요한 경우
- 배열로 받아서 처리하기 편한 경우
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import java.io.*;
public class FlexibleInput {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int n = Integer.parseInt(br.readLine());
String[] tokens = br.readLine().split(" ");
int[] arr = new int[n];
for (int i = 0; i < n; i++) {
arr[i] = Integer.parseInt(tokens[i]);
}
br.close();
}
}
성능 비교 예제
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
import java.io.*;
import java.util.*;
public class PerformanceComparison {
public static void main(String[] args) throws IOException {
// 테스트 데이터 생성
int dataSize = 100000;
StringBuilder testData = new StringBuilder();
testData.append(dataSize).append("\n");
for (int i = 0; i < dataSize; i++) {
testData.append(i).append(" ");
}
// Scanner 방식
long start = System.nanoTime();
Scanner sc = new Scanner(testData.toString());
int n1 = sc.nextInt();
int[] arr1 = new int[n1];
for (int i = 0; i < n1; i++) {
arr1[i] = sc.nextInt();
}
long scannerTime = System.nanoTime() - start;
sc.close();
// BufferedReader + StringTokenizer
start = System.nanoTime();
BufferedReader br = new BufferedReader(new StringReader(testData.toString()));
int n2 = Integer.parseInt(br.readLine());
StringTokenizer st = new StringTokenizer(br.readLine());
int[] arr2 = new int[n2];
for (int i = 0; i < n2; i++) {
arr2[i] = Integer.parseInt(st.nextToken());
}
long tokenizerTime = System.nanoTime() - start;
br.close();
// BufferedReader + String.split()
start = System.nanoTime();
br = new BufferedReader(new StringReader(testData.toString()));
int n3 = Integer.parseInt(br.readLine());
String[] tokens = br.readLine().split(" ");
int[] arr3 = new int[n3];
for (int i = 0; i < n3; i++) {
arr3[i] = Integer.parseInt(tokens[i]);
}
long splitTime = System.nanoTime() - start;
br.close();
System.out.println("Scanner: " + (scannerTime / 1_000_000) + "ms");
System.out.println("BufferedReader + StringTokenizer: " + (tokenizerTime / 1_000_000) + "ms");
System.out.println("BufferedReader + String.split(): " + (splitTime / 1_000_000) + "ms");
}
}
선택 가이드
입력 크기 기준
- 입력 크기가 작은 경우 (수백 줄 이하)
- Scanner 사용 가능
- 편의성 우선
- 입력 크기가 큰 경우 (수천 줄 이상)
- BufferedReader 사용 권장
- 성능 우선
시간 제한 기준
- 시간 제한이 넉넉한 경우
- Scanner 사용 가능
- 시간 제한이 타이트한 경우
BufferedReader+StringTokenizer조합 권장
토큰 패턴 기준
- 단순한 구분자 (공백, 콤마 등)
StringTokenizer권장- 성능 최우선
- 복잡한 패턴
String.split()사용- 정규식 활용
코딩 테스트 기준
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// 기본 템플릿 - `BufferedReader` + `StringTokenizer`
import java.io.*;
import java.util.StringTokenizer;
public class Solution {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
int n = Integer.parseInt(br.readLine());
StringTokenizer st = new StringTokenizer(br.readLine());
// 알고리즘 구현
bw.flush();
bw.close();
br.close();
}
}
출력 최적화
System.out.println의 특징
- 메커니즘
- 매 호출마다 자동으로 flush 수행
- 버퍼링 없이 즉시 출력
- 내부적으로 동기화(synchronized) 처리
- 성능
- 가장 느림
- 출력량이 많을 경우 성능 저하 심각
- 적합한 상황
- 출력량이 적은 경우
- 디버깅 목적
- 간단한 프로그램
BufferedWriter의 특징
- 메커니즘
- 내부 버퍼에 데이터를 모았다가 한 번에 출력
- 명시적으로
flush()또는close()호출 필요 write()와newLine()메서드 사용
- 성능
System.out.println보다 훨씬 빠름- 대량 출력 시 필수적
- 적합한 상황
- 코딩 테스트에서 많은 결과 출력
- 대용량 데이터 처리
- 성능이 중요한 경우
1
2
3
4
5
6
7
8
9
10
11
12
13
14
import java.io.*;
public class BufferedWriterExample {
public static void main(String[] args) throws IOException {
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
for (int i = 0; i < 100000; i++) {
bw.write(i + "\n");
}
bw.flush();
bw.close();
}
}
StringBuilder의 활용
- 메커니즘
- 문자열을 메모리에 모두 조립한 후 한 번에 출력
- 가변 문자열로
+연산자보다 효율적 - 최종적으로
toString()으로 변환 후 출력
- 성능
- 문자열 연결 작업이 빈번할 때 가장 효율적
- 메모리 사용량은 증가하지만 속도는 빠름
- 적합한 상황
- 결과를 모두 조립한 후 한 번에 출력
- 문자열 연결이 많은 경우
- 성능 최적화 팁
- 잘못된 사용
sb.append(a + " " + b)- 내부적으로 또 다른
StringBuilder생성 - 불필요한 객체 생성 오버헤드
- 올바른 사용
sb.append(a).append(" ").append(b)- 연속적인
append()호출로 최적화 - 불필요한 중간 객체 생성 방지
- 초기 용량 설정으로 성능 향상
- 출력량이 많을 경우 내부 배열 확장 발생
- 예상 크기를 아는 경우 초기 용량 지정 권장
- 잘못된 사용
1
2
3
4
5
6
7
8
9
10
11
12
// 기본 생성자 - 초기 용량 16
StringBuilder sb = new StringBuilder();
// 초기 용량 지정 - 배열 확장 최소화
int expectedSize = 100000;
StringBuilder sb = new StringBuilder(expectedSize);
// 실제 사용 예시
StringBuilder result = new StringBuilder(n * 10); // n개의 결과, 각 10자 예상
for (int i = 0; i < n; i++) {
result.append(i).append("\n");
}
1
2
3
4
5
6
7
8
9
10
11
public class StringBuilderExample {
public static void main(String[] args) {
StringBuilder sb = new StringBuilder();
for (int i = 0; i < 100000; i++) {
sb.append(i).append("\n");
}
System.out.print(sb);
}
}
StringBuilder와 StringBuffer 비교
StringBuilder의 특징- 비동기화(Non-synchronized) 설계
- 멀티스레드 환경에서 안전하지 않음
- 단일 스레드 환경에서 가장 빠른 성능
- 일반적인 상황에서 권장
StringBuffer의 특징- 동기화(Synchronized) 처리
- 멀티스레드 환경에서 안전
- 동기화 오버헤드로 인해
StringBuilder보다 느림 - 여러 스레드가 동시에 문자열을 조작할 때만 필요
- 비교 요약
- 성능
StringBuilder>StringBuffer
- 스레드 안전성
StringBuffer>StringBuilder
- 일반적인 선택 기준
- 단일 스레드 환경 또는 로컬 변수
StringBuilder사용
- 여러 스레드가 공유하는 객체
StringBuffer사용
- 단일 스레드 환경 또는 로컬 변수
- 성능
BufferedReader와의 대칭성BufferedReader- 동기화 처리 (스레드 안전)
StringBuilder- 비동기화 처리 (빠른 성능)
StringBuffer- 동기화 처리 (스레드 안전)
출력 방식 비교
| 특징 | System.out.println | BufferedWriter | StringBuilder |
|---|---|---|---|
| 버퍼링 | 없음 (즉시 출력) | 있음 | 메모리에 조립 |
| 성능 | 느림 | 빠름 | 매우 빠름 |
| 사용 편의성 | 높음 | 보통 | 보통 |
| 메모리 사용 | 적음 | 보통 | 많음 |
코딩 테스트 출력 권장 패턴
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
import java.io.*;
import java.util.StringTokenizer;
public class OptimizedSolution {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
StringBuilder sb = new StringBuilder();
int n = Integer.parseInt(br.readLine());
for (int i = 0; i < n; i++) {
// 계산 수행
int result = i * 2;
sb.append(result).append("\n");
}
bw.write(sb.toString());
bw.flush();
bw.close();
br.close();
}
}
- 권장 조합
- 입력
BufferedReader+StringTokenizer
- 출력
BufferedWriter또는StringBuilder+System.out.print
- 복잡한 출력 포맷
StringBuilder로 조립 후BufferedWriter로 출력
- 입력
입출력 최적화 흐름
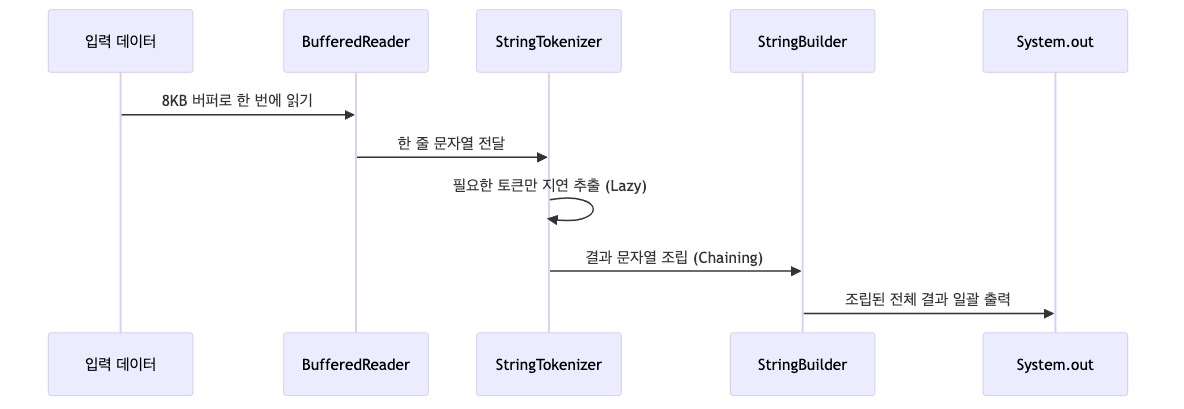
- 최적화된 데이터 흐름
- 입력
BufferedReader가 8KB 버퍼로 데이터를 한 번에 읽기- 읽기 횟수 최소화
- 파싱
StringTokenizer가 필요한 토큰만 지연 추출 (Lazy)- 메모리 효율성 극대화
- 출력
StringBuilder로 결과 문자열 조립 (Chaining)- 조립된 전체 결과를
System.out에 일괄 출력
- 입력
- 성능 최적화 포인트
- 입출력 횟수 최소화
- 8KB 단위 버퍼링
- 불필요한 메모리 할당 방지
- 지연 처리 방식
- 출력 동기화 오버헤드 제거
- 일괄 출력
- 입출력 횟수 최소화
결론
Scanner는 편리하지만 대용량 입력에서는 느림BufferedReader는 빠르지만 직접 파싱 필요StringTokenizer는 단순하고 빠름String.split()은 유연하지만 상대적으로 느림- 코딩 테스트에서는
BufferedReader+StringTokenizer조합이 가장 효율적