JVM과 GC 그리고 객체
- 널널한 개발자님의 독하게 시작하는 Java Part 2에서 세대별 컬렉션 이론과 주요 GC 알고리즘(Mark-Sweep, Mark-Copy, Mark-Compact), 도달 가능성 분석, 클래식 가비지 컬렉터 종류, 객체 메모리 레이아웃 구조, Object 클래스의 주요 메서드와 동등성·동일성 개념을 학습하며 JVM의 메모리 관리 메커니즘을 정리함
세대별 컬렉션 이론
기본 가설
-
약한 세대 가설(Weak Generational Hypothesis)
- 대다수의 객체는 생성 후 곧바로 사라짐
- 새로 생성된 객체의 생존 기간이 짧다는 경험적 법칙
-
강한 세대 가설(Strong Generational Hypothesis)
- GC 과정에서 살아남은 횟수가 늘어날수록 해당 객체의 생존 가능성이 높음
- 오래된 객체일수록 계속 살아남을 확률이 높음
핫스팟 VM의 메모리 비율
- 효율성 근거
- Infant Mortality
- 대다수 객체가 생성 직후 소멸되는 통계적 특성 (98% 이상)
- Eden(80%) + Survivor(10%) = 약 90% 공간을 활용하여 대부분의 객체를 Young Gen에서 처리 가능
- 생존율이 높을 경우 Old Gen으로 조기 승격(Premature Promotion)될 수 있음
- Infant Mortality
JVM 힙 영역의 상세 구조

Young Generation
-
Eden 영역
- 객체 생성 직후 저장되는 공간임
- Minor GC 발생 시 살아남은 객체는 Survivor 영역으로 이동함
- 대부분의 객체가 여기서 소멸됨
- Copy & Scavenge 알고리즘을 사용함
-
Survivor 0 및 1 영역
- Minor GC에서 살아남은 객체들이 거쳐가는 공간임
- Minor GC 발생 시 Eden, S0에서 살아남은 객체는 S1으로 이동함
- age bit를 사용해 GC 생존 횟수를 기록함 (참조 계수가 아님)
- age가 임계값(MaxTenuringThreshold, 기본 15)에 도달하면 Old 영역으로 승격됨
- 중요
- 두 Survivor 영역 중 하나는 항상 비어있음
- 이는 Mark and Copy 알고리즘을 수행하기 위함
- Eden과 “비어있지 않은 Survivor”에서 살아남은 객체들이 “비어있는 Survivor”로 한꺼번에 복사되면서 파편화를 자연스럽게 해결함
- 이 과정이 끝나면 기존 공간들은 통째로 비워짐
- Minor GC에서 살아남은 객체들이 거쳐가는 공간임
Old Generation
- Young 영역에서 소멸하지 않고 남은 객체들이 사용하는 영역임
- Full GC 발생 시 회수 대상이 됨
- age bit가 특정 임계값(기본 15)을 넘으면 이동함
- Mark & Compact 알고리즘을 사용함
Permanent
- Metaspace
- Java 8부터 도입됨
- 클래스와 메서드에 관한 메타 정보를 Native 메모리 영역에 저장함
- 이전의 PermGen을 대체함
- 동적으로 크기가 조정됨
주요 가비지 컬렉션 알고리즘
Mark and Sweep
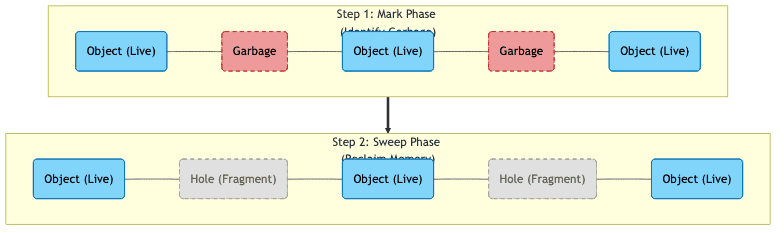
-
동작 방식
- 회수 대상을 표시(Mark)한 후 제거(Sweep)하는 가장 기본적인 방식
- GC 루트에서 시작하여 도달 가능한 모든 객체를 마킹함
- 마킹되지 않은 객체를 회수함
-
장점
- 구현이 간단함
- 메모리 오버헤드가 적음
-
단점
- 메모리 파편화(Fragmentation) 문제가 발생할 수 있음
- 연속된 큰 메모리 공간이 필요한 객체 할당이 어려워질 수 있음
Mark and Copy
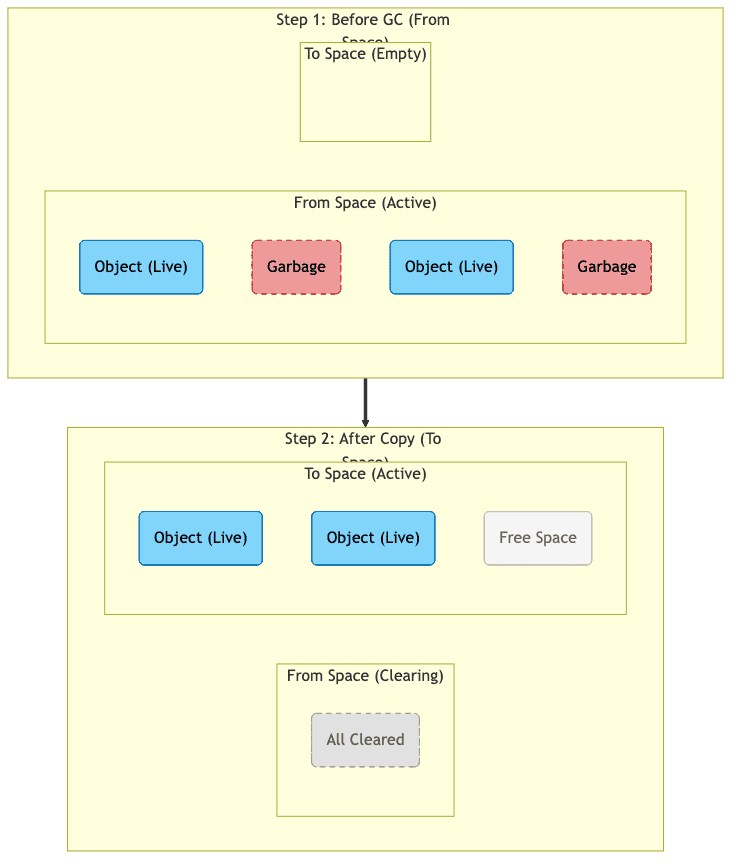
-
동작 방식
- 가용 메모리 공간을 두 영역으로 나누어 사용함
- 살아남은 객체를 다른 공간으로 복사함
- 기존 공간 전체를 비움
-
장점
- 메모리 파편화를 방지함
- 할당이 매우 빠름(단순한 포인터 이동)
-
단점
- 가용 공간이 절반으로 줄어듦
- 살아남은 객체가 많으면 복사 비용이 큼
-
활용
- Young Generation에서 주로 사용됨
- Eden과 Survivor의 8:1 비율로 메모리 낭비를 최소화함
Mark and Compact
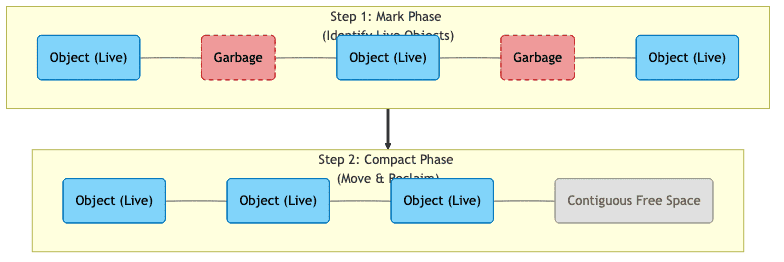
-
동작 방식
- 생존 객체를 한쪽 구석으로 모음(Compaction)
- 나머지 공간을 비움
- 인스턴스 이동 시 Stop-The-World 현상이 발생함
-
장점
- 메모리 파편화를 해결함
- 메모리 공간을 효율적으로 사용함
-
단점
- 객체 이동으로 인한 오버헤드가 큼
- Stop-The-World 시간이 길어질 수 있음
-
활용
- Old Generation에서 주로 사용됨
도달 가능성 분석 및 GC 루트
도달 가능성 분석 알고리즘
- GC 루트 객체에서 시작하여 참조 체인을 따라가며 도달 가능한 객체를 판단함
- 도달 불가능한 객체는 회수 대상으로 표시됨
GC 루트 객체
-
JVM 스택의 지역변수
- 현재 실행 중인 메서드의 지역변수와 매개변수가 참조하는 객체
-
정적 필드(Static Fields)
- 클래스의
static변수가 참조하는 객체
- 클래스의
-
상수(Constants)
- Runtime Constant Pool에 저장된 상수가 참조하는 객체
-
활성화된 스레드(Active Threads)
- 실행 중인 스레드 객체 자체
- 스레드 스택의 모든 프레임에 있는 지역변수가 참조하는 객체
-
JNI 참조
- Native 메서드가 참조하고 있는 Java 객체
-
동기화 모니터
- synchronized 블록에서 사용 중인 락 객체
-
도달 가능성
- GC Root → 객체1 → 객체2 … 이렇게 연결된 모든 객체는 Alive로 간주됨
클래식 가비지 컬렉터의 종류
Serial GC
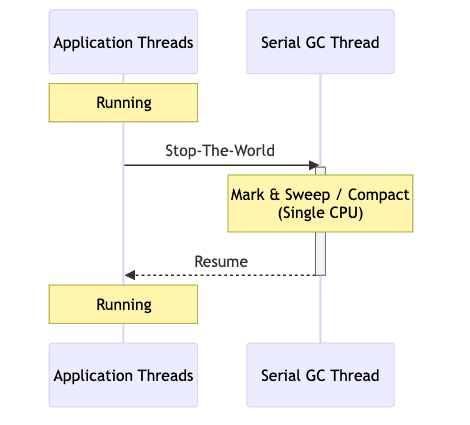
-
특징
- 단일 스레드로 작동 (GC 수행 시 1개의 CPU만 사용)
- 회수가 끝날 때까지 모든 애플리케이션 스레드를 정지시킴 (Stop-The-World)
- Young Generation에서는 Mark-Copy 알고리즘 사용
- Old Generation에서는 Mark-Sweep-Compact 알고리즘 사용
-
주요 사용처
- 클라이언트 모드나 소규모 애플리케이션
- CPU 코어가 1개인 환경
- 힙 크기가 작은 환경 (수백 MB 이하)
-
장점
- 간단하고 효율적인 알고리즘
- 메모리 오버헤드가 적음
- 단일 코어 환경에서 최적화됨
-
단점
- 긴 Stop-The-World 시간
- 멀티코어 환경에서 비효율적
- 힙이 커질수록 중단 시간이 길어짐
-
설정
-XX:+UseSerialGC옵션으로 활성화
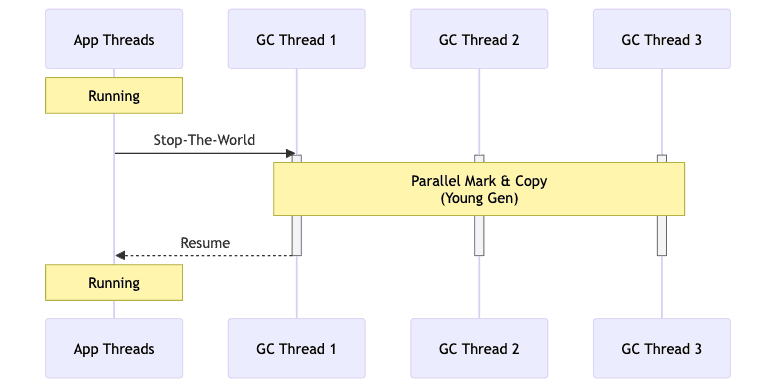
ParNew GC
-
특징
- Serial GC를 다중 스레드로 병렬화한 버전
- Young Generation 전용 GC (Old Generation은 다른 GC 필요)
- 주로 CMS GC와 함께 사용됨
- Young Generation에서 Mark-Copy 알고리즘을 병렬로 수행
-
주요 사용처
- CMS GC를 사용하는 환경의 Young Generation 담당
- 멀티코어 서버 환경
-
장점
- Serial GC 대비 빠른 Young GC
- 멀티코어를 활용한 병렬 처리
-
단점
- CMS가 deprecated되면서 함께 사용 중단
- Young GC만 담당 (전체 솔루션 아님)
-
설정
-XX:+UseParNewGC(현재는 deprecated)-XX:ParallelGCThreads=n(병렬 스레드 수 지정)
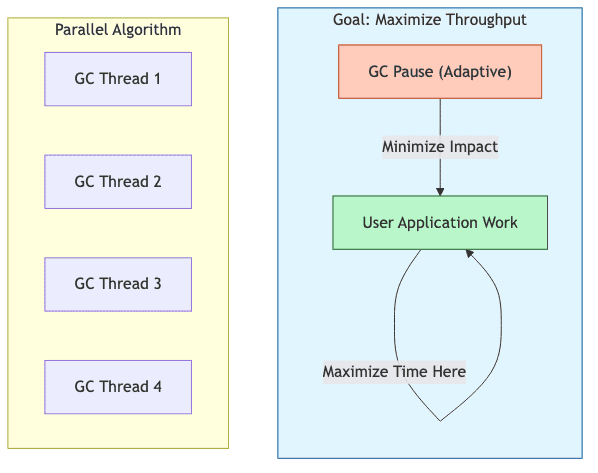
Parallel Scavenge GC
-
특징
- 처리량(Throughput) 최대화를 목표로 설계됨
- Young Generation과 Old Generation 모두 병렬 처리
- 적응형(Adaptive) 크기 조정 정책 지원
- Young Generation: Mark-Copy (Parallel)
- Old Generation: Mark-Sweep-Compact (Parallel)
-
ParNew와의 차이점
- ParNew: CMS와 조합, 응답 시간 중시
- Parallel Scavenge: 처리량 우선, 전체 애플리케이션 성능 최적화
-
주요 사용처
- 배치 처리, 데이터 분석 등 처리량이 중요한 애플리케이션
- 백그라운드 작업이 많은 환경
- 응답 시간보다 전체 처리량이 중요한 경우
-
장점
- 높은 처리량 (전체 작업 시간 대비 GC 시간 최소화)
- 자동 튜닝 기능 (
-XX:+UseAdaptiveSizePolicy) - 목표 처리량 설정 가능
-
단점
- 개별 GC 중단 시간이 상대적으로 길 수 있음
- 응답 시간 민감한 애플리케이션에는 부적합
-
설정
-XX:+UseParallelGC(Young + Old 모두 병렬)-XX:MaxGCPauseMillis=n(최대 중단 시간 목표)-XX:GCTimeRatio=n(처리량 목표, 기본값 99 = GC 시간 1%)-XX:+UseAdaptiveSizePolicy(자동 튜닝)
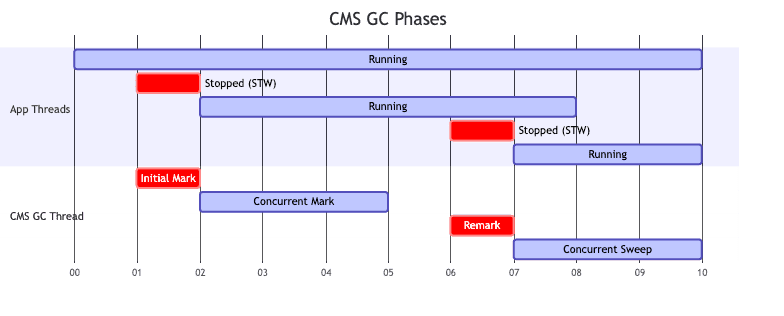
CMS (Concurrent Mark Sweep) GC
-
특징
- 응답 시간(Low Latency) 최소화를 목표로 설계됨
- 애플리케이션 스레드와 동시 실행(Concurrent) 가능
- Old Generation 전용 (Young Gen은 ParNew 사용)
- 4단계 동작
- Initial Mark (STW, 짧음)
- GC Root 직접 참조 객체만 마킹
- Concurrent Mark
- 애플리케이션과 동시에 전체 마킹
- Remark (STW, 짧음)
- Concurrent Mark 단계에서 변경된 사항 재마킹
- Concurrent Sweep
- 애플리케이션과 동시에 쓰레기 수거
- Initial Mark (STW, 짧음)
-
주요 사용처
- 웹 애플리케이션 서버
- 응답 시간이 중요한 실시간 서비스
-
장점
- 매우 짧은 STW 시간 (2번만 발생)
- 대부분의 작업을 애플리케이션과 동시 실행
-
단점
- Compaction 없음 → 메모리 단편화 발생
- Concurrent Mode Failure: Old Gen이 가득 차면 Full GC 발생
- CPU 리소스 사용 (동시 실행으로 인한 오버헤드)
- Java 9에서 Deprecated, Java 14에서 완전 제거됨
-
설정
-XX:+UseConcMarkSweepGC(Java 8까지만)-XX:CMSInitiatingOccupancyFraction=n(Old Gen 사용률이 n%일 때 GC 시작)
G1 (Garbage First) GC

-
특징
- JDK 9부터 기본 GC로 채택됨
- Region 기반 힙 구조 (1~32MB 크기의 독립 영역)
- 쓰레기가 가장 많은 Region을 우선 회수 (Garbage First)
- 예측 가능한 중단 시간 제공
- 전통적인 Young/Old 세대 구분이 아닌 동적 Region 할당
-
Region 타입
- Eden
- 새 객체 할당
- Survivor
- Young GC에서 살아남은 객체
- Old
- 여러 번 살아남은 객체
- Humongous
- Region 크기의 50% 이상인 대형 객체 전용
- Free
- 사용되지 않는 빈 영역
- Eden
-
동작 방식
-
Young GC (Minor GC)
- Eden과 Survivor 영역 회수
- 병렬로 빠르게 수행
- STW 발생하지만 매우 짧음
-
Mixed GC
- Young 영역 + Old 영역 일부(쓰레기가 많은 Region) 함께 회수
- 여러 번에 걸쳐 점진적으로 수행
- Collection Set (CSet): 회수할 Region 집합
-
Full GC (최후의 수단)
- 전체 힙 회수 (Serial GC처럼 동작)
- 긴 STW 발생 → 피해야 함
-
-
주요 알고리즘
- Snapshot-At-The-Beginning (SATB): Concurrent Marking 중 객체 변경 추적
- Remembered Set (RSet): Region 간 참조 추적
- Collection Set (CSet): 회수 대상 Region 집합
-
주요 사용처
- 대용량 힙 (4GB 이상) 서버 애플리케이션
- 멀티코어 환경
- 예측 가능한 중단 시간이 필요한 경우
-
장점
- 예측 가능한 STW 시간
- 큰 힙(6GB~수백GB)에서 효율적
- 메모리 파편화 최소화 (Compaction 수행)
- 처리량과 응답 시간의 균형
-
단점
- 작은 힙(<4GB)에서는 오버헤드가 큼
- 복잡한 알고리즘으로 인한 CPU 오버헤드
- RSet, CSet 관리에 추가 메모리 사용
-
설정
-XX:+UseG1GC(JDK 9부터 기본값)-XX:MaxGCPauseMillis=200(목표 중단 시간, 기본 200ms)-XX:G1HeapRegionSize=n(Region 크기, 1/2/4/8/16/32MB)-XX:InitiatingHeapOccupancyPercent=45(전체 힙 사용률이 45%일 때 Marking 시작)-Xms/-Xmx(최소/최대 힙 크기)
GC 선택 가이드
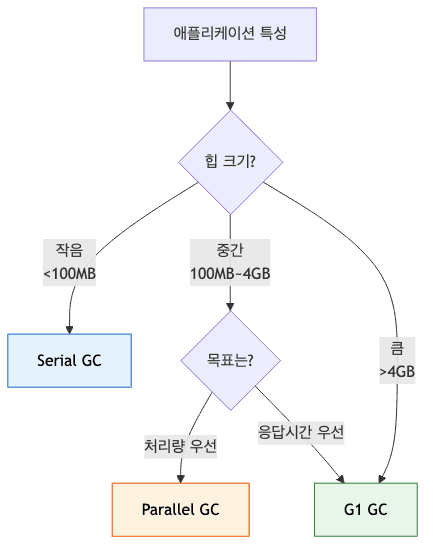
| GC | 사용 시기 | 힙 크기 | 목표 |
|---|---|---|---|
| Serial | 단일 CPU, 클라이언트 | <100MB | 단순함 |
| Parallel | 배치, 백그라운드 작업 | 100MB~4GB | 처리량 최대화 |
| G1 | 대부분의 서버 애플리케이션 | >4GB | 균형 (처리량 + 응답시간) |
| ZGC/Shenandoah | 초저지연 요구 | >8GB | 응답시간 <10ms |
추가 참고사항
Java 버전별 기본 GC
- Java 8: Parallel GC
- Java 9~현재: G1 GC
- Java 11+: ZGC, Shenandoah (실험적)
- Java 15+: ZGC (프로덕션 준비 완료)
GC 모니터링
1
2
3
4
5
6
7
8
# GC 로그 활성화
-Xlog:gc*:file=gc.log
# GC 상세 정보 (Java 8)
-XX:+PrintGCDetails -XX:+PrintGCDateStamps
# GC 시간 측정
-XX:+PrintGCApplicationStoppedTime
GC 수동 실행
1
2
3
4
5
6
7
8
9
10
11
12
public class Main {
public static void main(String[] args) {
{
// 대용량 메모리 할당을 통해 GC 유도
byte[] placeholder = new byte[64 * 1024 * 1024]; // 64MB
}
// 지역 변수가 스코프를 벗어난 후 명시적 호출
int a = 0;
System.gc(); // GC 제안 (보장되지 않음)
}
}
- 주의사항
System.gc()는 GC를 제안(Request)할 뿐, 실행을 강제(Command)하지 않음- 대부분의 경우 JVM이 요청을 무시하거나 최적의 타이밍까지 미룸
- Full GC를 유발하여 애플리케이션 성능에 심각한 영향을 줄 수 있으므로 실무 코드에서는 절대 사용해선 안 됨 (디버깅/테스트 용도 한정)
객체 메모리 레이아웃
객체 헤더 구조
-
Mark Word
- 해시코드(Identity HashCode)를 저장함
- 객체의 나이(GC 생존 횟수, 4비트)를 저장함
- 락 플래그(Lock flag) 정보가 포함됨
- 크기
- 32비트 JVM(4바이트), 64비트 JVM(8바이트), Compressed OOPs 활성화 시(4바이트 가능)
-
Klass Word (Class Pointer)
- 클래스의 메타 데이터가 저장된 Metaspace 영역을 가리킴
- 타입 정보에 대한 포인터
Hash (함수)의 특징
-
정의
- $f(x) \rightarrow y$만 가능한 단방향 함수
-
특징
- 단방향성
- 출력값(y)을 통해 입력값(x)을 유추할 수 없음
- 고정된 결과 길이
- 입력 값의 크기와 상관없이 항상 일정한 길이(또는 크기)의 결과 값을 반환함
- 무결성 보장
- 데이터의 변경 유무를 확인하는 데 사용됨 (IT 기술 전반에서 활용)
- 단방향성
-
대표적 알고리즘
- MD-5, SHA-1
- SHA-128, 256, 384, 512
락 플래그 상태
| 상태 | 의미 | 저장 정보 |
|---|---|---|
| 01 | Unlock (언락) | 객체 해시코드, 나이 |
| 00 | Lightweight locking (경량 잠금) | 스택의 Lock Record 포인터 |
| 10 | Heavyweight locking (중량 잠금) | Monitor 객체 포인터 |
| 11 | GC Marked (마킹됨) | GC 처리 중 |
- 참고
- Biased Locking(편향 잠금)은 Java 15부터 기본 비활성화됨 (-XX:+UseBiasedLocking으로 켜기 가능)
객체 레이아웃 확인
-
JOL(Java Object Layout) 라이브러리를 사용하여 확인 가능함
-
JOL 라이브러리 설정 (IntelliJ IDEA)
lib폴더에jol-core-0.17.jar파일을 다운로드함- IntelliJ 상단 메뉴에서 File > Project Structure… 로 이동함
- 왼쪽 패널에서 Modules를 선택함
- 가운데 창에서 Dependencies 탭을 선택함
- 하단의 + 아이콘을 클릭한 후, JARs or directories…를 선택함
- 파일 탐색기가 열리면 프로젝트 내의
lib폴더로 이동하여jol-core-0.17.jar파일을 선택하고 OK를 클릭함 - Project Structure 창 하단의 OK 버튼을 눌러 설정을 저장함
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
import org.openjdk.jol.info.ClassLayout;
// 분석할 샘플 클래스 (필드 구성에 따라 레이아웃이 달라짐)
class Customer {
int id = 1001; // 4 bytes
boolean active = true; // 1 byte (Padding 발생 가능)
}
public class JolAnalysis {
public static void main(String[] args) {
Customer user = new Customer();
// 클래스 레이아웃 명세 출력
System.out.println(ClassLayout.parseClass(Customer.class).toPrintable());
// 인스턴스 레이아웃 (해시코드 생성 전 - Biased Locking 가능 상태)
System.out.println("Before HashCode:\n" + ClassLayout.parseInstance(user).toPrintable());
// 해시코드 생성 (Identity HashCode가 헤더에 기록됨)
System.out.printf("HashCode: %x\n", user.hashCode());
// 인스턴스 레이아웃 (해시코드 생성 후 - 상태 변화 확인)
System.out.println("After HashCode:\n" + ClassLayout.parseInstance(user).toPrintable());
}
}
Object 클래스와 주요 메서드
Object 클래스의 역할
- 모든 Java 클래스의 최상위 부모 클래스임
- 모든 객체가 공통으로 가져야 할 기본 메서드를 정의함
주요 메서드
equals()
- 기본 동작
- 참조자와 대상이 같은지 주소값을 비교함
==연산자와 동일한 동작을 수행함
1
2
3
public boolean equals(Object obj) {
return (this == obj);
}
- 재정의 필요성
- 논리적 동등성을 비교하려면 재정의해야 함
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
class MyTest {
int a = 10;
// 객체 내부의 데이터를 비교하도록 재정의
@Override
public boolean equals(Object obj) {
// 자기 자신과의 비교 (성능 최적화)
if (this == obj) return true;
// null 체크 및 타입 체크
if (!(obj instanceof MyTest)) {
return false;
}
// 타입 캐스팅 후 필드 비교
MyTest other = (MyTest) obj;
return this.a == other.a;
}
}
- equals 규약
- 반사성
x.equals(x)는 항상 true
- 대칭성
x.equals(y)가 true면y.equals(x)도 true
- 추이성
x.equals(y),y.equals(z)가 true면x.equals(z)도 true
- 일관성
- 여러 번 호출해도 결과 동일
- Null-safe
x.equals(null)은 항상 false
- 반사성
hashCode()
-
역할
- 객체 식별을 위한 고유한 해시 결과값을 반환함
- 해시 기반 컬렉션(HashMap, HashSet)에서 사용됨
- 기본 동작
native메서드로 구현되어 있으며, 일반적으로 객체의 메모리 주소를 기반으로 생성됨 (객체가 이동해도 hash 값은 유지됨)
-
규약
equals()가true인 두 객체는 같은 해시코드를 반환해야 함equals()를 재정의하면hashCode()도 함께 재정의해야 함
1 2 3 4
@Override public int hashCode() { return Objects.hash(a); }
toString()
-
기본 동작
- ‘클래스명@해시코드’ 형태의 문자열을 반환함
1 2 3
public String toString() { return getClass().getName() + "@" + Integer.toHexString(hashCode()); }
-
재정의 예시
1 2 3 4
@Override public String toString() { return "MyTest{a=" + a + "}"; }
동등성과 동일성
동등성 (Equality)
- 두 인스턴스의 내용이 일치하는지 비교하는 것임
equals()메서드 재정의를 통해 구현함-
논리적 비교를 수행함
1 2 3
String s1 = new String("Hello"); String s2 = new String("Hello"); s1.equals(s2); // true (내용이 같음)
동일성 (Identity)
- 같은 인스턴스에 대한 참조자인지 주소값을 비교하는 것임
- 상등 연산자(
==)를 사용함 -
물리적 비교를 수행함
1 2 3
String s1 = new String("Hello"); String s2 = new String("Hello"); s1 == s2; // false (다른 객체)
연습 문제
-
세대별 가비지 컬렉션(Generational GC)의 주요 가설은 무엇일까요?
a. 대부분의 객체는 금방 사용되지 않게 된다.
- 세대별 GC는 새로 생성된 객체는 금방 사라지고, 오래된 객체는 계속 살아남을 가능성이 높다는 가설에 기반함
- 이를 통해 GC 효율을 높임
-
가비지 컬렉션 알고리즘 중 Mark and Sweep 방식의 주된 단점을 개선하기 위해 도입된 방법은 무엇인가요?
a. 메모리 단편화 해결
- Mark and Sweep은 사용되지 않는 공간을 그대로 두어 메모리 단편화를 유발함
- 이를 해결하기 위해 객체를 모으는 Compact나 Copy 과정이 추가됨
-
JVM 도달 가능성 분석(Reachability Analysis)에서 ‘GC Root’는 무엇을 의미하나요?
a. 도달 가능성 탐색을 시작하는 기준이 되는 객체
- GC Root는 도달 가능성 탐색의 시작점임
- 스택의 지역 변수, static 필드 등 항상 참조된다고 간주되는 객체들이 Root가 될 수 있음
-
Java 객체의 메모리 레이아웃 중 해시코드, 객체 나이, 락 정보 등 객체의 상태 메타데이터가 저장되는 부분은 어디일까요?
a. Mark Word
- 객체 헤더의 Mark Word는 객체의 식별 정보나 상태를 나타내는 다양한 메타데이터를 포함함
- 해시코드, GC 나이, 락 정보 등이 여기 저장됨
-
Java에서 두 객체 참조 변수(
obj1,obj2)를obj1 == obj2와 같이==연산자로 비교할 때 확인하는 것은 무엇인가요?a. 두 참조 변수가 메모리 상에서 동일한 객체 인스턴스를 가리키는지 (동일성)
==연산자는 두 변수가 메모리에서 완전히 같은 인스턴스를 참조하는지, 즉 동일성을 비교함- 내용이 같은지(동등성)는 보통
equals()메서드를 사용해서 확인함
정리
- 세대별 컬렉션 이론은 약한/강한 세대 가설을 기반으로 Young과 Old를 분리하여 효율을 높임
- Mark-Sweep은 단순하지만 파편화 문제가 있고, Mark-Copy는 파편화를 해결하지만 메모리 낭비가 있음
- Mark-Compact는 Old Generation에 적합하며 파편화를 해결하지만 이동 비용이 큼
- 도달 가능성 분석은 GC 루트에서 시작하여 참조 체인을 따라가며 회수 대상을 판단함
- Serial GC는 단일 스레드로 동작하며, G1 GC는 Region 단위로 관리하여 예측 가능한 성능을 제공함
- 객체 헤더는 Mark Word와 Klass Word로 구성되며 해시코드, GC 나이, 락 정보를 저장함
- Object 클래스는 모든 클래스의 부모로
equals(),hashCode(),toString()등의 기본 메서드를 제공함 - 동등성은 내용 비교(
equals()), 동일성은 주소 비교(==)를 의미함 equals()를 재정의하면hashCode()도 함께 재정의하여 규약을 지켜야 함