학습 개요
- C++ 언어에서는 프로그램 작성에 유용하게 활용할 수 있는 표준 템플릿 라이브러리(STL)를 제공함
- STL에서 제공하는 컨테이너, 반복자, 알고리즘을 이해하고, 이를 활용하기 위한 여러 가지 구문들에 대하여 학습함
- STL 컨테이너 중
vector와map의 예를 통해 순차 컨테이너와 연상 컨테이너의 활용 방법에 대하여 학습함
학습 목표
- 표준 템플릿 라이브러리(STL)의 구성 요소를 이해할 수 있음
- STL의
vector클래스 템플릿을 사용할 수 있음 - STL의
map클래스 템플릿을 사용할 수 있음
주요 용어
- 표준 템플릿 라이브러리(STL)
- C++의 표준 라이브러리로 제공되는 컨테이너 클래스 템플릿
- 순차 컨테이너
- 선형적인 구조로 객체들을 저장하는 컨테이너
- 연상 컨테이너
- 인덱스 구조를 이용하여 키를 이용한 검색 기능을 제공하는 컨테이너
- 무순서 연상 컨테이너
- 해시 함수를 이용하여 키를 이용한 검색 기능을 제공하는 컨테이너
- 반복자(iterator)
- STL에서 컨테이너에 저장된 객체에 대한 포인터 역할을 하는 것
- STL 알고리즘
- STL에서 컨테이너의 원소에 대해 적용할 수 있도록 제공되는 여러 가지 연산의 집합
- 함수 객체(function object, functor)
- 마치 함수인 것처럼 호출하여 사용할 수 있는 객체
강의록
표준 템플릿 라이브러리(STL)
표준 템플릿 라이브러리
- 표준 템플릿 라이브러리(Standard Template Library, STL)이란?
- C++에 제공되는 표준 컨테이너 클래스 템플릿 라이브러리
- 벡터, 리스트, 스택, 큐 등의 컨테이너와 이들을 처리하기 위해 사용할 수 있는 여러 가지 연산을 포함함
- STL의 구성 요소
- 컨테이너(container)
- 데이터 저장
- 반복자(iterator)
- 포인터의 역할
- 알고리즘(algorithm)
- 데이터 처리 기능
- 컨테이너(container)
STL 컨테이너
- 데이터 저장을 위한 템플릿의 집합
int나float과 같은 기본 자료형 데이터나 사용자 정의 클래스의 객체 등을 저장함- 다양한 연산이 제공되어 편리하게 데이터를 활용할 수 있음
- 배열 역시 일종의 컨테이너의 역할을 하지만, 배열을 조작하기 위한 연산(데이터 삽입, 삭제, 검색 등)을 프로그래머가 모두 구현해야 함
- STL 컨테이너의 종류
- 순차 컨테이너
- 동일한 자료형의 객체들을 선형적인 구조로 저장함
종류 특성 vector크기의 확장이 가능한 배열 []연산자로 지정한 첨자를 이용하여 빠른 직접 접근끝에 삽입(또는 삭제)하는 것은 빠르나 그 외의 위치에 삽입(또는 삭제)하는 것은 느림 list이중 연결 리스트 어느 위치든 삽입이나 삭제가 효율적임 직접 접근이 비효율적이므로 제공하지 않음 dequevector와 list의 혼합 형태로, 이들의 특성이 모두 필요할 때 사용할 수 있으나 성능은 낮음
- 순차 컨테이너
- 연상 컨테이너
- 탐색 트리와 같은 인덱스 구조를 이용하는 컨테이너
-
키를 이용한 효율적인 검색 기능을 제공함
종류 특성 set키 객체만 저장하며, 키가 중복되지 않음 multiset키 객체만 저장하며, 동일한 키가 중복될 수 있음 map(키 객체, 값 객체)의 쌍을 저장 키가 중복되지 않음 multimap(키 객체, 값 객체)의 쌍을 저장 동일한 키가 중복될 수 있음
- 무순서 연산 컨테이너
- 연산 컨테이너처럼 키를 이용한 검색 기능을 제공
-
해시 함수를 이용하여 데이터 검색 시간이 일정함
종류 특성 unordered_setset,multiset,map,multimap과 같으나 해시 함수를 이용하여 저장 및 검색을 함unordered_multisetset,multiset,map,multimap과 같으나 해시 함수를 이용하여 저장 및 검색을 함unordered_mapset,multiset,map,multimap과 같으나 해시 함수를 이용하여 저장 및 검색을 함unordered_multimapset,multiset,map,multimap과 같으나 해시 함수를 이용하여 저장 및 검색을 함
- 컨테이너 어댑터
-
기본 컨테이너를 기반으로 특정 용도에 맞게 유도된 컨테이너
종류 특성 queueFIFO(First In, First Out) 구조 priority_queue우선 순위에 따라 데이터를 액세스할 수 있는 구조 stackLIFO(Last In, First Out) 구조
-
- 반복자(
iterator)란?- 포인터의 개념이 일반화된 것
-
컨테이너의 유형에 따라 서로 다른 형태의 반복자가 사용됨
종류 특성 순방향(forward) 반복자 컨테이너의 순방향으로만 움직일 수 있음 ++연산자 사용양방향(bidirectional) 반복자 컨테이너의 순방향과 역방향으로 움직일 수 있음 ++,--연산자 사용랜덤 액세스 반복자 양방향 반복자의 기능과 함께 임의의 위치로 이동할 수 있음
STL 활용 예 - vector
vector
vector란?- 1차원 배열의 개념을 구현한 순차 컨테이너 유형의 클래스 템플릿
- 배열의 일반적인 기능을 포함하면서 여러 가지 유용한 멤버 함수 및 관리 기능이 도입되어 있음
- 배열처럼 크기가 고정되어 있지 않고 필요에 따라 저장 공간을 확장할 수 있음
- 필요한 헤더 파일
<vector>
-
vector객체의 선언 구문1
vector<ClassName> objName(n);
n- 벡터에 저장할 객체의 수
-
ex) 10개의 float 값을 저장하는
vector의 선언1
vector<float> fVector(10);
[]연산자vector에 대한 직접 접근 연산자- 배열처럼 첨자를 지정하여 원소를 직접 접근할 수 있게 함
-
[]연산자의 사용 예1 2 3
vector<float> fVector(10); fVector[2] = 10.0f; cout << fVector[2];
-
첨자가 올바른 범위의 값인지 검사하지 않음
1 2
vector<float> fVector(10); fVector[12] = 10.0f; // 실행 중 에러 발생
- 멤버 함수
at()- 직접 접근을 위한 멤버 함수
- 첨자의 범위를 검사함
- 지정된 첨자가 범위를 벗어날 경우 예외 발생
-
at()함수의 사용 예1 2 3 4
vector<int> iVector = { 1, 2, 3, 4 }; iVector.at(2) = 10; cout << iVector.at(2) << endl; cout << iVector.at(4) << endl; // 예외 발생
- 멤버 함수
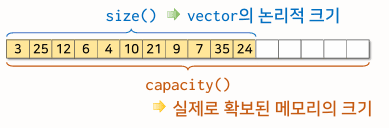
size()와capacity()vector는 크기는 실행 중 확장할 수 있음- 미래의 확장에 대비하여 여분의 공간을 미리 확보할 수 있음
- 논리적인
vector의 크기와 실제 할당된 메모리의 크기는 다를 수 있음
- 멤버 함수
push_back()과pop_back()vector의 끝에 데이터를 저장하거나 꺼냄
- 멤버 함수
insert()와erase()vector의 지정된 위치에 데이터를 삽입하거나 삭제함- 함수의 실행에 따라
size()의 값은 증가하거나 감소함 capacity()의 값은 데이터 추가로 인해 확보된 메모리가 부족하여 확장될 때 바뀜
- 함수의 실행에 따라
vector의 사용 예 - Vector1.cpp
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
#include <iostream>
#include <vector>
using namespace std;
int main()
{
vector<int> intVec(5); // 벡터 객체 생성
for (int i = 0; i < intVec.size(); i++) {
intVec[i] = i + 1;
}
cout << "벡터의 논리적 크기 : " << intVec.size() << endl;
cout << "벡터의 물리적 크기 : " << intVec.capacity() << endl;
cout << "저장된 데이터 : ";
for (int i = 0; i < intVec.size(); i++) {
cout << intVec[i] << " ";
}
cout << endl << endl;
cout << "1개의 데이터 push_back" << endl;
intVec.push_back(11);
cout << "벡터의 논리적 크기 : " << intVec.size() << endl;
cout << "벡터의 물리적 크기 : " << intVec.capacity() << endl;
cout << "저장된 데이터 : ";
for (int i = 0; i < intVec.size(); i++)
cout << intVec[i] << " ";
cout << endl << endl;
cout << "5개의 데이터 push_back" << endl;
for (int i = 1; i <= 5; i++)
intVec.push_back(i + 11);
cout << "벡터의 논리적 크기 : " << intVec.size() << endl;
cout << "벡터의 물리적 크기 : " << intVec.capacity() << endl;
cout << "저장된 데이터 : ";
for (int i = 0; i < intVec.size(); i++)
cout << intVec[i] << " ";
cout << endl << endl << "3개의 데이터 pop_back" << endl;
for (int i = 0; i < 3; i++) {
intVec.pop_back();
}
cout << "벡터의 논리적 크기 : " << intVec.size() << endl;
cout << "벡터의 물리적 크기 : " << intVec.capacity() << endl;
cout << "저장된 데이터 : ";
for (int i = 0; i < intVec.size(); i++) {
cout << intVec[i] << " ";
}
cout << endl;
return 0;
}
// 벡터의 논리적 크기 : 5
// 벡터의 물리적 크기 : 5
// 저장된 데이터 : 1 2 3 4 5
// 1개의 데이터 push_back
// 벡터의 논리적 크기 : 6
// 벡터의 물리적 크기 : 7
// 저장된 데이터 : 1 2 3 4 5 11
// 5개의 데이터 push_back
// 벡터의 논리적 크기 : 11
// 벡터의 물리적 크기 : 15
// 저장된 데이터 : 1 2 3 4 5 11 12 13 14 15 16
// 3개의 데이터 pop_back
// 벡터의 논리적 크기 : 8
// 벡터의 물리적 크기 : 15
// 저장된 데이터 : 1 2 3 4 5 11 12 13
vector의 크기 확장 및 데이터 조작 함수
| 함수 | 용도 |
|---|---|
push_back(value) |
끝에 데이터를 추가 |
pop_back() |
끝에 있는 데이터를 제거 |
resize(n) |
논리적 크기의 변경 |
reserve(n) |
capacity()가 최소한 n을 반환하도록 확장 |
empty() |
비어 있는 벡터의 경우 true반환 |
erase(it) |
반복자 it가 가리키는 위치 삭제 |
erase(it1, it2) |
[it1, it2)범위의 데이터 삭제 |
insert(it, value) |
반복자 it가 가리키는 위치에 value삽입 |
vector와 반복자
-
반복자의 선언
1
vector<ClassName>::iterator it;
-
반복자의 값을 구하는
vector의 멤버 함수begin()- 첫 번째 원소를 가리키는 랜덤 액세스 반복자를 반환함
end()- 마지막 원소의 다음 위치를 가리키는 랜덤 액세스 반복자를 반환함

vector의 반복자 활용 예 - Vector2.cpp
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
#include <iostream>
#include <vector>
using namespace std;
int main()
{
vector<int> intVec(5);
for (int i = 0; i < intVec.size(); i++)
intVec[i] = i + 1;
vector<int>::iterator it = intVec.begin();
cout << "저장된 데이터 : ";
for (; it < intVec.end(); it++)
cout << *it << " ";
cout << endl;
it = intVec.begin();
cout << "3번째 데이터 : ";
cout << *(it + 2) << endl;
return 0;
}
// 저장된 데이터 : 1 2 3 4 5
// 3번째 데이터 : 3
알고리즘의 활용
sort()함수
sort()의 용법-
랜덤 액세스 반복자에 의해 지정된 범위의 값들을 정렬함
1
sort(first, last);
1
sort(first, last, comp);
first- 정렬할 범위의 시작 원소에 대한 포인터
last- 정렬할 범위의 마지막 원소의 다음 위치에 대한 포인터
comp- 정렬 순서를 정하는 함수(callback 함수)
a의 순서가b보다 앞인 경우comp(a, b) == true
-
merge()함수
merge()의 용법-
동일한 기준으로 정렬된 두 개의 데이터 집합을 동일한 기준으로 정렬된 하나의 데이터 집합으로 결합하는 함수
1
merge(first1, last1, first2, last2, dest);
1
merge(first1, last1, first2, last2, dest, comp);
first1, last1- 첫 번째 정렬된 데이터의 범위
first2, last2- 두 번째 정렬된 데이터의 범위
dest- 합병 결과가 저장될 시작 위치
comp- 합병 순서를 정하는 함수
-
알고리즘의 활용 예 - Vector3.cpp
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
#include <iostream>
#include <vector>
#include <cstdlib>
#include <ctime>
#include <algorithm>
using namespace std;
int main()
{
srand((unsigned)time(NULL)); // 난수 발생기 초기화
vector<int> iv1(5); // 크기 5짜리 벡터 생성
cout << "벡터1 : ";
for (auto &i : iv1)
{
i = rand() % 100; // 0~99의 난수 발생
cout << i << " ";
}
cout << endl;
sort(iv1.begin(), iv1.end()); // 정렬 알고리즘
cout << "정렬된 벡터1 : ";
for (auto i : iv1)
{
cout << i << " ";
}
cout << endl << endl;
vector<int> iv2(5);
cout << "벡터2 : ";
for (auto &i : iv2)
{
i = rand() % 100; // 0~99의 난수 발생
cout << i << " ";
}
cout << endl;
sort(iv2.begin(), iv2.end()); // 정렬 알고리즘
cout << "정렬된 벡터2 : ";
for (auto i : iv2)
{
cout << i << " ";
}
cout << endl << endl;
// 합병 결과를 저장할 벡터
vector<int> iv3(iv1.size() + iv2.size());
// iv1과 iv2를 합병한 결과를 iv3에 저장
merge(iv1.begin(), iv1.end(), iv2.begin(), iv2.end(), iv3.begin());
cout << "벡터1과 벡터2를 합병한 결과 : ";
for (auto i : iv3)
{
cout << i << " ";
}
cout << endl;
return 0;
}
// 벡터1 : 97 62 77 57 69
// 정렬된 벡터1 : 57 62 69 77 97
// 벡터2 : 47 99 48 99 33
// 정렬된 벡터2 : 33 47 48 99 99
// 벡터1과 벡터2를 합병한 결과 : 33 47 48 57 62 69 77 97 99 99
정렬 순서의 결정
-
정렬 순서 지정을 위한 콜백 함수 전달
1
sort(first, last, comp);
1 2 3 4 5 6 7 8 9 10
template<typename T> bool gt(const T &a, const T &b) { return a > b; } void f(vector<int>& iv) { // 내림차순 정렬 sort(iv.begin(), iv.end(), gt<int>()); }
-
함수 객체를 이용한 콜백 함수 전달
- 함수 객체
- 함수처럼 사용될 수 있는 객체
()연산자를 다중 정의함
1 2 3 4 5 6
template<typename T> class GREATER { public: bool operator()(const T &a, const T &b) const { return a > b; } };
1 2 3
GREATER<int> greaterthan; if (greaterthan(20, 10)) cout << "20은 10보다 큼";
1 2 3 4 5 6 7 8 9 10 11
template<typename T> class GREATER { public: bool operator()(const T &a, const T &b) const { return a > b; } }; void f(vector<int>& iv) { // 내림차순 정렬 sort(iv.begin(), iv.end(), GREATER<int>()); }
- 함수 객체
STL 활용 예 - map
map
map이란?- 저장하는 데이터의 형태는 (키, 값)의 쌍
- 키를 이용하여 데이터에 직접 접근할 수 있는 연상 컨테이너
- 키(key)
- 데이터 집합에서 특정 데이터를 검색하거나 데이터 집합을 정렬하는 기준이 되는 속성
- ex) (이름, 전화번호) 쌍이 저장되어 있는 연락처 목록
- 이름을 키로 하여 전화번호 검색
- 키(key)
map에 저장되는 데이터는 키가 모두 다름- 트리 형태의 데이터 구조를 이용함으로써 검색 시간이 데이터 수의 로그 함수에 비례함
- 필요한 헤더 파일
<map>
map의 활용
-
map객체의 선언1
map<KeyType, ValueType, Traits> objName;
KeyType- 키의 자료형
ValueType- 키와 연관된 데이터의 자료형
Traits- map 내에서의 상대적 순서를 결정하는 함수 객체의 클래스
- 디폴트는
less<KeyType>
-
키가 이름, 값이 주소이고, 각각을
string으로 표현할 때, (이름, 주소)의 쌍을 저장하는map1
map<string, string> addrbook;
- 데이터 저장
-
insert()함수1 2 3 4
map<string, string> addrbook; addrbook.insert(make_pair("김철수", "서울시 종로구")); addrbook.insert({"홍길동", "서울시 중구"}); addrbook.insert({"김철수", "서울시 성동구"}); // 삽입 불가능
pairfirst와second라는 2개의 데이터 멤버를 포함하는 템플릿 구조체
make_pairpair객체를 반환하는 함수 템플릿
- 동일한 키를 갖는 데이터가 이미 존재할 경우 삽입이 이루어지지 않음
-
[]연산자-
키를 이용한 데이터 직접 접근
1 2 3 4
addrbook ("김철수", "서울시 종로구") ("홍길동", "서울시 중구") ("박영식", "대전시 동구")-
“서울시 중구” 출력
1
cout << addrbook["홍길동"];
-
(“박영식”, “대전시 동구”) 삽입
1
addrbook["박영식"] = "대전시 동구";
-
“김철수”의 데이터 수정
1
addrbook["김철수"] = "서울시 성동구";
-
-
find()함수를 이용한 검색-
지정된 키를 갖는 데이터를 가리키는 반복자 반환
1 2 3 4
addrbook ("김철수", "서울시 종로구") ("홍길동", "서울시 중구") ("박영식", "대전시 동구")-
it는pair객체 (“박영식”, “대전시 동구”)를 가리킴1
auto it = addrbook.find("박영식");
-
it에addrbook.end()가 저장됨1
auto it = addrbook.find("이서연");
-
-
erase()함수를 이용한 데이터 삭제- 삭제할 데이터를 가리키는 반복자를 지정하는 방법
-
it가 가리키는 데이터 삭제1
addrbook.erase(it1);
-
- 삭제할 데이터를 가리키는 반복자의 범위를 지정하는 방법
-
[it1, it2)범위의 데이터 삭제1
addrbook.erase(it1, it2);
-
- 키를 지정하여 데이터를 삭제하는 방법
-
키가 “박영식”인 데이터 삭제
1
addrbook.erase("박영식");
-
- 삭제할 데이터를 가리키는 반복자를 지정하는 방법
map의 활용 예 - PBookMap.cpp
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
#include <iostream>
#include <string>
#include <map>
using namespace std;
template<typename T>
class LESS_T {
public:
bool operator()(const T &a, const T &b) const {
return a < b;
}
};
int main()
{
map<string, string, LESS_T<string>> pBook {
{"한정훈", "010-2233-4354"},
{"박영철", "010-2233-4455"}
};
pBook["김철수"] = "010-1234-5678";
pBook.insert(make_pair("최승호", "010-7531-3456"));
pBook.insert({"박영철", "010-1357-2468"}); // 동일 키이므로 삽입 안 됨
for (auto pb = pBook.begin(); pb != pBook.end(); ++pb) {
cout << pb->first << " " << pb->second << endl;
}
cout << pBook.size() << "명이 등록되어 있습니다." << endl;
cout << endl;
string str;
cout << "찾을 이름 : ";
cin >> str;
auto result = pBook.find(str);
if (result != pBook.end()) {
cout << result->first << "님의 전화번호는 " << result->second << " 입니다." << endl;
} else {
cout << str << "님을 찾을 수 없습니다." << endl;
}
return 0;
}
// 김철수 010-1234-5678
// 박영철 010-2233-4455
// 최승호 010-7531-3456
// 한정훈 010-2233-4354
// 4명이 등록되어 있습니다.
// 찾을 이름 : 박영철
// 박영철님의 전화번호는 010-2233-4455 입니다.
정리 하기
- 표준 템플릿 라이브러리는 컨테이너, 알고리즘, 반복자로 구성 됨
- STL에서 제공하는 컨테이너에는 순차 컨테이너, 연상 컨테이너, 무순서 연상 컨테이너가 있음
- 반복자(
iterator)는 컨테이너 내의 객체를 가리키는 포인터의 개념에 해당 됨 - STL의 컨테이너에 대해서는 템플릿에 선언된 멤버 함수들 외에 STL 알고리즘을 통해 여러 가지 유용한 연산을 적용할 수 있음
vector는 확장 가능한 배열에 해당되는 STL 컨테이너 클래스 템플릿임sort(),merge()등의 알고리즘에 콜백 함수를 전달할 때 함수 객체를 이용하면 일반적인 함수를 전달하는 것에 비해 효율적으로 동작할 수 있음- STL의
map을 이용하면 트리 형태의 데이터 구조를 이용하여 (키, 값) 쌍의 데이터를 저장하고, 키를 이용하여 데이터에 직접 접근할 수 있음
연습 문제
-
STL의 세 가지 구성 요소 중 포인터의 역할을 하는 것은?
a. 반복자(
iterator)- STL을 구성하는 세 가지 요소는 컨테이너, 반복자, 알고리즘임
- 컨테이너는 자료형 데이터나 사용자 정의 클래스의 객체 등을 저장하는 역할을 하고, 반복자는 포인터와 같은 기능을 제공하며, 알고리즘은 컨테이너의 원소에 대해 적용할 수 있는 여러 가지 연산을 제공함
-
다음 중 순차 컨테이너에 해당되는 것은?
a.
vector- 순차 컨테이너는 객체들을 선형적인 구조로 저장하는 컨테이너로서,
vector,list,deque,stack,queue,priority_queue등이 이에 해당 됨
- 순차 컨테이너는 객체들을 선형적인 구조로 저장하는 컨테이너로서,
-
다음 중
vector에 대한 올바른 설명은?a.
vector객체의 논리적 크기는 실제로 할당된 메모리의 크기와 다를 수 있음vector는 배열과 같은 기능을 제공하나, 크기가 필요에 따라 확장될 수 있음- 크기를 확장할 때는 논리적 크기를 수용할 수 있도록 확장되나, 실제 크기가 논리적 크기와 일치하지 않을 수 있으며, 미래의 확장에 대비해 공간을 확장함으로써 논리적 크기가 변화할 때마다 저장 공간을 새로 할당함에 따른 비효율성을 줄임
pop_back()함수는 벡터의 논리적 크기를 감소 시킴
-
위 지문은 함수 객체를 정의하기 위한 클래스 템플릿을 선언한 것이다. ㈀에 넣을 적절한 내용은?
1 2 3 4 5 6 7
template<typename T> class GREATER { public: bool // ________(ㄱ)________ (const T& a, const T& b) const { return a > b; } };
a.
operator()- 함수 객체는 마치 함수를 호출하는 것처럼 사용할 수 있는 객체로, 함수 객체를 만들기 위해서는
()연산자를 다중 정의 해야 함
- 함수 객체는 마치 함수를 호출하는 것처럼 사용할 수 있는 객체로, 함수 객체를 만들기 위해서는
-
STL의
map에 대한 올바른 설명은? a. (키, 값)의 쌍을 저장하여 키를 이용하여 데이터에 직접 접근할 수 있는 연상 컨테이너이다.map은 (키, 값)의 쌍을 저장하여 키를 이용한 직접 접근을 할 수 있는 연상 컨테이너임- 이때
map객체에 저장된 데이터의 키는 모두 서로 달라야 함 - 데이터가 트리 형태의 데이터 구조로 저장되므로, 특정 키를 갖는 항목을 검색하는 데 드는 시간은 데이터 수의 로그 함수에 비례함
정리 하기
- 표준 템플릿 라이브러리는 컨테이너, 알고리즘, 반복자로 구성됨
- STL에서 제공하는 컨테이너에는 순차 컨테이너, 연상 컨테이너, 무순서 연상 컨테이너가 있음
- 반복자(
iterator)는 컨테이너 내의 객체를 가리키는 포인터의 개념에 해당 됨 - STL의 컨테이너에 대해서는 템플릿에 선언된 멤버 함수들 외에 STL 알고리즘을 통해 여러 가지 유용한 연산을 적용할 수 있음
vector는 확장 가능한 배열에 해당되는 STL 컨테이너 클래스 템플릿임sort(),merge()등의 알고리즘에 콜백 함수를 전달할 때 함수 객체를 이용하면 일반적인 함수를 전달하는 것에 비해 효율적으로 동작할 수 있음