학습 개요
- 오늘 날 우리는 데이터 중심 사회 속에서 살아가고 있으며, 데이터는 단순한 수집의 대상이 아니라 가치를 창출하고 문제를 해결하기 위한 핵심 자산으로 인식되고 있음
- 데이터를 효과적으로 활용하기 위해서는 데이터의 속성을 이해하고, 체계적인 분석 과정을 통해 인사이트를 도출할 수 있어야 함
- 데이터 분석의 개념과 목적, 분석 과정의 주요 단계를 살펴보고, 데이터 분석이 어떻게 현실 세계의 의사 결정과 문제 해결에 활용 되는 지를 이해함
- 데이터의 유형과 형태에 따라 달라지는 데이터 분석 방법도 학습함
- 데이터 분석 환경 구축에 많은 공헌을 하고 있는 오픈 소스의 철학과 역사적 배경, 그리고 오픈 소스 기반 기술들이 데이터 분석 환경에서 어떻게 활용 되는 지를 파악함
- 파이썬을 비롯한 주요 오픈 소스 도구와 라이브러리의 개방성과 협업성을 이해함으로써, 앞으로 데이터 분석 작업에서 오픈 소스 생태계를 적극 활용할 수 있는 기반을 마련함
학습 목표
- 데이터 분석의 정의와 중요성을 설명할 수 있음
- 데이터 분석 과정의 주요 단계의 목적과 방법을 설명할 수 있음
- 데이터의 특징과 형태에 데이터의 종류를 나열할 수 있음
- 오픈 소스 소프트웨어와 오픈 데이터의 특징 및 장점을 설명할 수 있음
강의록
데이터 분석의 이해
데이터와 정보
- 데이터 정의
- 데이터에 숨겨진 의미를 발견하고, 이를 바탕으로 의사 결정에 활용할 수 있는 인사이트를 도출하는 일련의 과정
- 정보의 정의
- 정보는 데이터를 목적에 맞게 가공한 결과물
- 데이터와 정보 관계
- 현상 → 관찰 · 측정 → 데이터 → 처리 · 가공 → 정보
데이터 분석의 개념
- 데이터에 숨겨진 의미를 발견하고, 이를 바탕으로 의사 결정에 활용할 수 있는 인사이트를 도출하는 일련의 과정
- 데이터를 정리 · 처리 · 변환하여 유의미한 정보를 도출
- 데이터를 구조화하고 패턴을 파악하며 특정 현상의 원인을 찾거나 미래를 예측하기 위한 논리적이고 체계적인 접근
- 데이터에 감춰진 가치와 인사이트를 발견
- 의사 결정의 질 향상 및 비즈니스 문제의 근본 원인 파악
- 데이터 품질 문제, 데이터의 규모와 복잡성, 적절한 분석 방법론 선택, 분석 결과 해석과 커뮤니케이션, 데이터 윤리와 개인 정보 보호 등 다양한 도전 과제가 존재
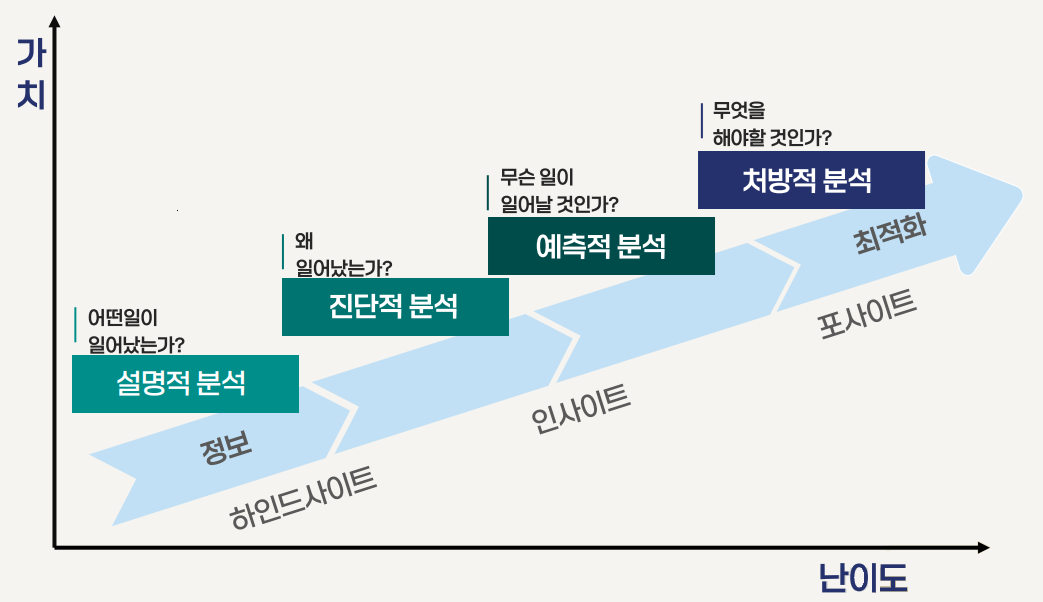
데이터 분석의 4단계
- 설명적 분석: 어떤 일이 일어났는가? (정보 → hindsight)
- 진단적 분석: 왜 일어났는가?
- 예측적 분석: 무슨 일이 일어날 것인가? (인사이트 → foresight)
- 처방적 분석: 무엇을 해야 할 것인가? (최적화)
데이터 분석 적용 사례: PHM
-
장비나 시스템의 상태를 실시간으로 감시하고, 고장 가능성을 예측하여 최적의 유지 보수 및 관리 방안 제공

데이터 분석 적용 사례
| 구분 | 주요 사례 |
|---|---|
| 개인 맞춤형 마케팅 | 전자상거래에서 스포츠 브랜드 신제품 추천 |
| 금융 | 은행의 대출 프로세스 자동화 |
| 스포츠 | 오클랜드 애슬레틱스 ‘머니볼 전략’ |
| 공공 정책 | 코로나19 대응 정책, 백신 계획 |
| 운영 | 제조업의 스마트 팩토리 |
| 의료 | 암 환자 맞춤형 치료법 개발 |
| 도시 행정 및 치안 | 교통 신호 체계 설계, 치안 개선 |
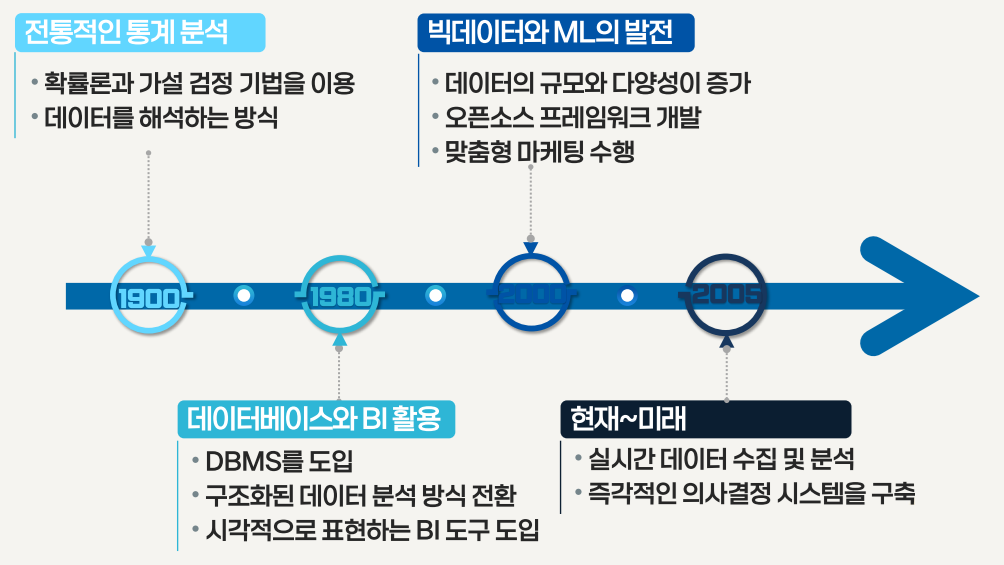
데이터 분석의 발전 과정
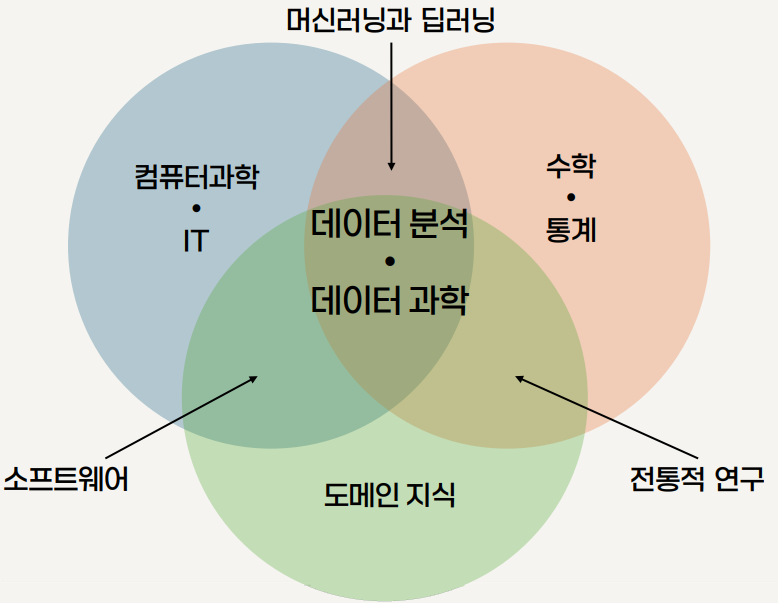
데이터 분석의 3요소
데이터 분석과 데이터 과학
| 항목 | 데이터 분석 | 데이터 과학 |
|---|---|---|
| 개념 | 수집된 데이터를 정리 · 가공하여 의미 있는 정보를 도출하는 과정 | 예측 모델을 만들고, 자동화된 의사 결정 시스템을 구축하는 포괄적 과정 |
| 접근 방식 | 통계, 데이터 시각화, 기본적인 머신 러닝 등을 활용 | 통계, 머신 러닝, 컴퓨터 프로그래밍, 데이터 엔지니어링 등을 종합적으로 활용 |
| 목적 | 데이터 기반 의사 결정 지원이 중심 | 의사 결정의 자동화 및 최적화 |
| 범위 | 데이터 과학의 한 부분 | 데이터 분석을 포함하는 상위 개념 |
| 과정 | 데이터 수집 → 전처리 → EDA → 분석 → 시각화 → 인사이트 도출 | 데이터 수집 → 전처리 → 분석 → 자동화 시스템 구현 |
| 분야 | 마케팅, 리포트 작성, 경영 전략 수립 등 | 제품 추천, 예측 시스템, 자율 주행, 인공지능 서비스 등 |
데이터의 특징과 데이터 분석 과정
데이터 분석 과정
-
데이터를 적절한 방법으로 수집하고 정제한 후, 패턴을 탐색하고 모델링을 수행하여 결과를 해석하는 체계적인 접근이 필요
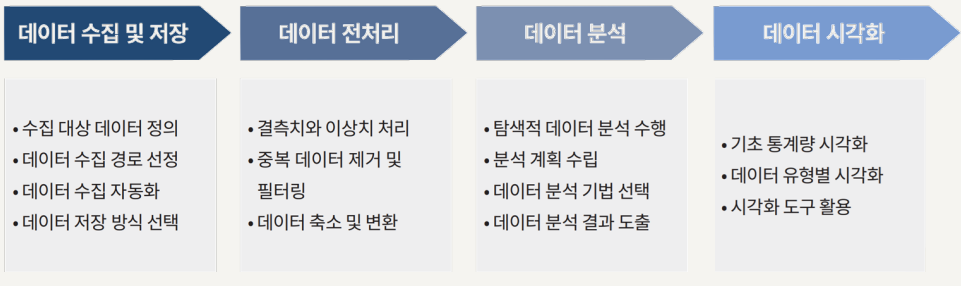
데이터 수집 및 저장 단계
- 단순히 데이터를 모으는 것이 아니라 수집한 데이터를 효율적으로 보관하고, 분석 목적에 적합한지 검토
- 데이터 수집 과정
- 데이터 분석 목표를 기반으로 데이터 수집 목적 설정
- 데이터 출처 결정
- 내부 데이터: 기업이나 기관 내부에서 생성 된 데이터
- 외부 데이터: 정부의 공공 데이터, 소셜 미디어 데이터, 연구 기관의 통계 자료 등 기관 외부에서 제공하는 데이터
- 데이터 수집 방법 결정
- 파일 다운로드, 데이터베이스, 웹 스크래핑, API, 센서(IoT)
데이터 전처리 단계
-
데이터를 정리하고 변환하여 분석이 가능하도록 가공하는 과정
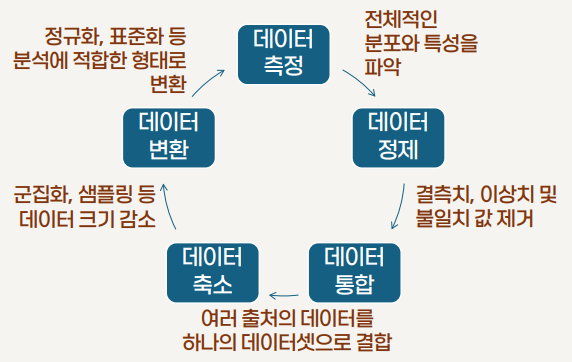
데이터 분석 단계
- 통계 기법, 데이터 간의 관계 파악, 예측 모델 구축 등의 데이터 분석 기법 적용
- EDA
- 데이터의 분포와 특성을 이해하기 위한 과정
- 데이터를 요약하고 시각적으로 표현
- 주요 패턴과 이상치 파악, 변수 간 관계 분석
- 통계 분석
- 평균, 중앙 값, 표준 편차 등 기본 기술 통계
- 가설 검정, 상관 분석, 회귀 분석 등 통계 기법 활용
- 데이터에서 발견된 패턴의 통계적 유의성 검증
- 머신 러닝 및 딥 러닝
- 과거 데이터를 학습하여 미래 예측이나 데이터 분류
- 자동화 된 의사 결정 모델 구축
- 복잡한 패턴을 발견 및 대규모 데이터에서 인사이트 도출
데이터 시각화 단계
- 데이터 셋의 정보와 관계를 그래프, 차트, 다이어그램 등의 시각적 요소를 활용하여 직관적으로 표현
- 데이터 시각화의 역할
- 데이터 탐색과 패턴 발견
- 복잡한 데이터의 요약
- 데이터 분석 결과 전달
데이터 속성에 따른 분류
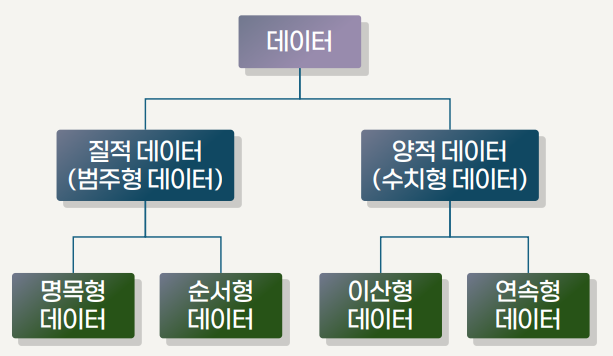
데이터 형태에 따른 분류
- 정형 데이터 (structured data)
- 일정한 규칙과 구조를 갖춘 데이터
- 행과 열로 구성 된 표 형태로 관계형 데이터베이스에 저장
- 비정형 데이터 (unstructured data)
- 정해진 구조 없이 자유로운 형태로 존재하는 데이터
- 문장, 이미지, 영상, 음성 등 다양한 형식
- 분석이 어려운 반면 소비자 감정 및 행동 패턴 등 많은 정보량
- 반정형 데이터 (semi-structured data)
- 정형 데이터와 비정형 데이터의 중간 형태
- 데이터 항목 간 일정한 규칙이나 구조가 존재하나, 완전히 테이블 형태로 고정 불가능
오픈 소스의 이해
오픈 소스의 개념
- 인류의 지적 자산(소스 코드와 데이터)을 개방함으로써 더 많은 사람들과 함께 공유하고 협력하겠다는 철학
- 1960년대 미국 대학가의 반문화 운동과 해커 문화에서 시작되어 “정보는 자유로워야 한다”는 신념으로 발전
- 오픈 철학의 확장
- 소스 코드가 공개되어 누구나 자유롭게 접근, 사용, 복제, 수정, 재배포할 수 있는 소프트웨어 분야
- MIT OCW, MOOC 등 대학 강의를 무료로 공개
- 정부와 공공 기관이 보유한 데이터를 시민들에게 공개
리처드 스톨먼 (RMS: Richard Mathew Stallman)
- 컴퓨터 과학자이자 소프트웨어 자유론의 강한 지지자
- 자유 소프트웨어 운동의 중심 역할 및 오픈 소스 소프트웨어 초석 마련
- GNU 프로젝트 시작
- 자유 소프트웨어 재단(FSF) 설립
- GNU 시작의 계기
- 사건1: PDP-10에 설치할 DEC사의 OS 사용에 복사 뿐만 아니라 자료 또한 유출하지 않겠다는 NDA를 요구
- 사건2: 유닉스 라이센스 비용은 카피당 $99(소스 코드 포함)에서 $250,000로 올림
FSF의 확장
- 에릭 레이몬드의 1997년 에세이 ‘성당과 시장’
- FSF에서 또 다른 분수령
- 두 방식의 개발 모델
- 성당: 핵심 그룹이 개발을 수행하는 독점적 SW 개발에서 전형적으로 나타나는 폐쇄적 하향식 접근 방식
- 시장: 네트워크를 통해 무료로 공유되는 개방적 공개 개발 방식
- Open Source Initiative(OSI) 설립의 시초
지속 가능 모델?
- 성공적 OSS 개발을 위해 개발자의 지속 참여 필수
- 기업의 관점
- OSS는 개발 비용을 외부화, 초기 개발 비용을 감소
- 기업의 코드 공개가 다른 개발자의 코드 공개를 유도할 수 있으므로, 기업은 직간접적으로 OSS 개발에 참여
- 개인의 관점
- 내재적 동기
- 취미 생활로서, 수정 사항 공유 및 선물하는 즐거움
- 내가 도운 대로 상대방도 도울 것이라는 일반화된 호혜성
- 외재적 동기
- OSS 개발자로서의 명성은 노동 시장에서 신호 효과 유도
- 내재적 동기
파이썬과 오픈 소스 환경
- 오픈 소스 철학을 기반으로 설계되고 발전해온 언어
- 언어 자체와 이를 둘러싼 수많은 라이브러리, 프레임워크, 커뮤니티 활동이 모두 오픈 소스 방식으로 운영
- 개발 환경
- IDLE: 기본 제공되는 개발 환경
- Jupyter Notebook: 코드를 블록(셀) 단위로 실행
- 구글 Colab: 별도 설치 없이 웹 브라우저에서 바로 사용
- 다양한 오픈 소스 라이브러리
- Selenium, lxml, Pandas, statsmodels
- Matplotlib, Seaborn, Scikit-learn
연습 문제
-
데이터 분석의 주요 목적 중 하나로 가장 적절한 것은?
a. 데이터를 정리하여 인사이트를 도출하고 의사 결정에 활용하는 것
-
다음 중 데이터 분석의 일반적인 4단계에 포함되지 않는 것은?
a. 암호화 분석
-
다음 중 오픈 소스 철학의 핵심 가치가 아닌 것은?
a. 폐쇄성과 보안성
정리 하기
- 데이터 분석은 데이터를 정리 · 처리 · 변환하여 유의미한 정보를 도출하는 과정임
- 데이터 분석은 인사이트와 가치 창출, 비효율적 프로세스 개선, 사회적 문제 해결, 데이터 기반 의사 결정을 가능하게 함
- 데이터 분석은 컴퓨터 과학, 도메인 지식, 통계 및 수학의 3요소로 구성 됨
- 데이터는 속성, 형태에 따라 다양하게 분류되며 그에 따른 분석 방법이 필요함
- 오픈 소스는 소프트웨어나 데이터가 공개되어 누구나 자유롭게 접근, 사용, 수정, 재배포할 수 있음
- 파이썬 프로그래밍 환경은 IDLE, Jupyter Notebook, Google Colab 등이 있음
- 데이터 분석에 필요한 파이썬 패키지는 Selenium, lxml, NumPy, Pandas, Statsmodels, Matplotlib, Seaborn, Scikit-learn 등의 오픈 소스 라이브러리가 있음