학습 개요
- 데이터 분석은 분석 기법 뿐만 아니라 분석에 사용되는 데이터의 품질에 크게 좌우됨
- 잘못되거나 부정확한 데이터를 기반으로 한 분석은 오류가 포함된 결과를 초래할 수 있으며, 이는 데이터 기반 의사 결정의 신뢰도를 떨어뜨림
- 따라서 분석 이전 단계에서 데이터를 정제하고 구조화하는 전처리 작업은 데이터 분석의 성패를 가르는 중요한 과정임
- 데이터 전처리의 필요성과 정의, 그리고 전처리 단계에서 수행되는 작업을 살펴봄
- 결측치와 이상치, 불일치 값 등 분석을 방해하는 요소들을 식별하고 정제하는 기법을 학습하며, 데이터 통합, 축소, 변환을 통해 데이터의 정확성과 일관성을 높이는 방법을 익힘
- 데이터의 구조와 특성을 정량적으로 파악하기 위한 측정 기법을 소개하고, pandas 라이브러리를 활용한 통계량 계산과 describe() 메소드의 활용법을 실습함
학습 목표
- 데이터 품질의 주요 요소를 이해할 수 있음
- 데이터 전처리의 세부 과정을 나열할 수 있음
- Pandas 라이브러리를 활용하여 데이터의 기본 통계량을 측정하고 분석할 수 있음
강의록
데이터 전처리의 이해
데이터 전처리의 필요성
- GIGO(Garbage In, Garbage Out)
- 잘못되거나 부정확한 데이터를 입력하면 어떤 정교한 분석 기법을 적용하더라도 잘못된 결과가 출력 된다는 사실을 함축
- 데이터의 품질 향상을 통해 분석 결과의 질을 향상 시키기 위한 방안이 요구
데이터 전처리 대상 데이터
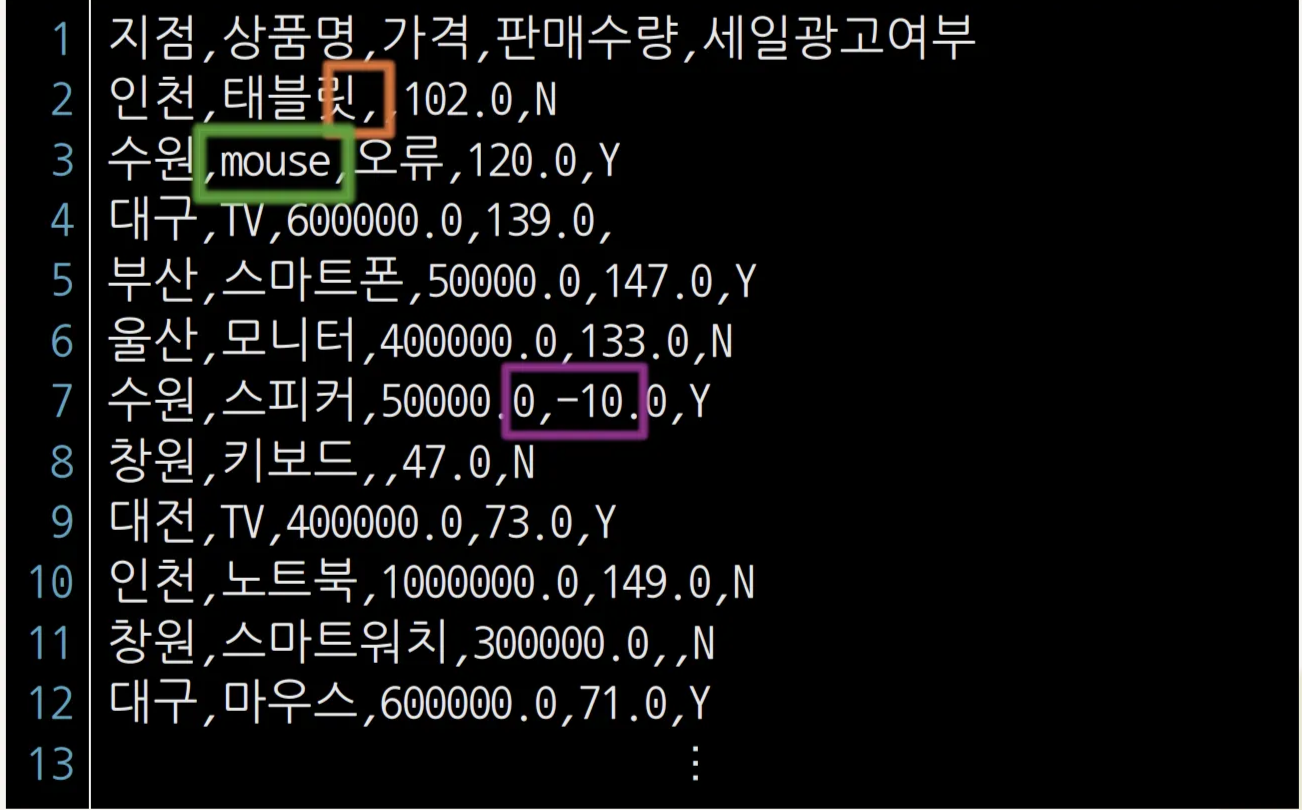
데이터 전처리의 필요성
- 정교한 데이터 분석 결과를 얻기 위해 데이터 분석에 다양한 변화 발생
- 사용되는 데이터의 규모가 점차 증가
- 신기술의 대중화로 다양하고 새로운 유형의 데이터 수집
- 여러 이질적인 소스로부터 데이터 수집
- 불필요/불일치/중복 데이터, 결측치, 이상치 등이 포함
- 데이터의 품질 향상을 통한 분석 결과의 질을 향상
- 결측치, 이상치, 값 불일치 등 데이터의 품질을 저하 시키는 요인 제거
- 데이터 정제, 통합, 축소, 변환과 같은 전처리 과정을 통해 데이터의 정확성과 일관성을 향상
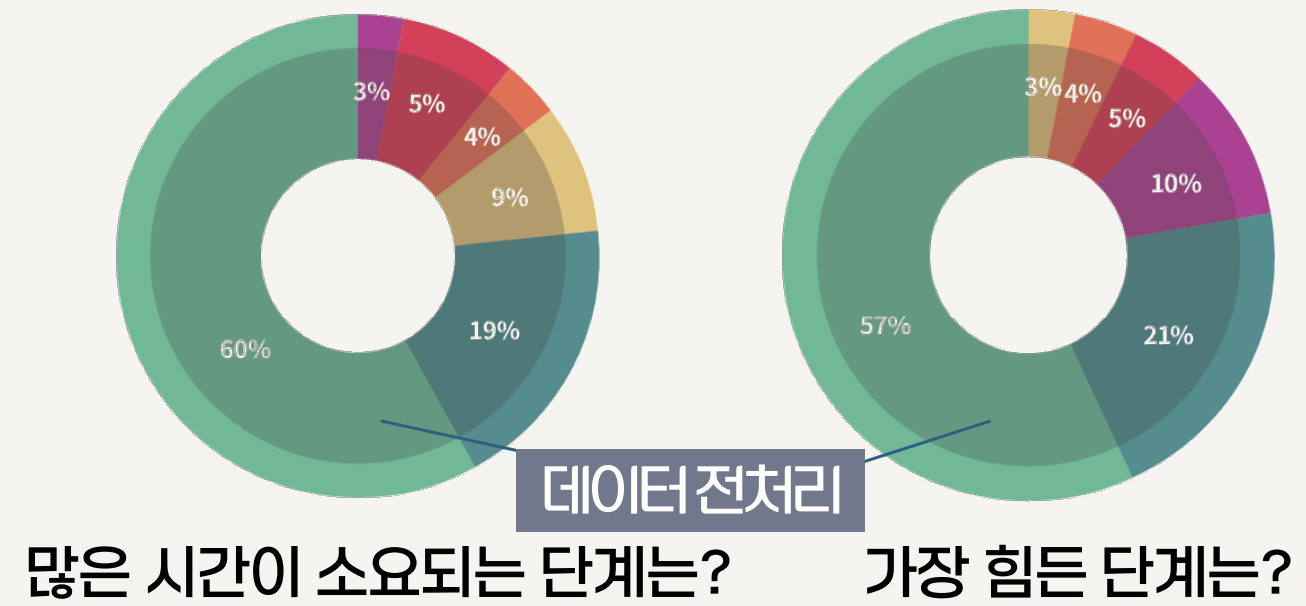
데이터 전처리의 위상
- 2021년 Forbes가 데이터 과학자 80명에게 설문
-
Cleaning Big Data: Most Time-Consuming, Least Enjoyable Data Science Task, Survey Says
데이터 전처리의 정의
- 데이터 분석에 앞서 원시 데이터(raw data)를 정제하고 변환하여 분석에 적합한 형태로 만드는 일련의 작업
- 데이터 분석의 전 단계에서 수행되며, 데이터의 정확성과 신뢰성을 확보
데이터 전처리의 어려움
- 방대한 데이터 양
- 수치형 데이터뿐만 아니라, 텍스트, 이미지, 로그 파일 등 다양한 형식이 존재
- 주관적 판단의 개입 여지
- 정해진 정답이 없으며, 상황에 따라 적절한 결정
- 다양한 처리 방법
- 처리 방법이 고정되어 있지 않으며, 다양한 접근법이 존재
- 시간과 노력 소모
- 여러 단계를 반복적으로 확인하고 검토하는 과정
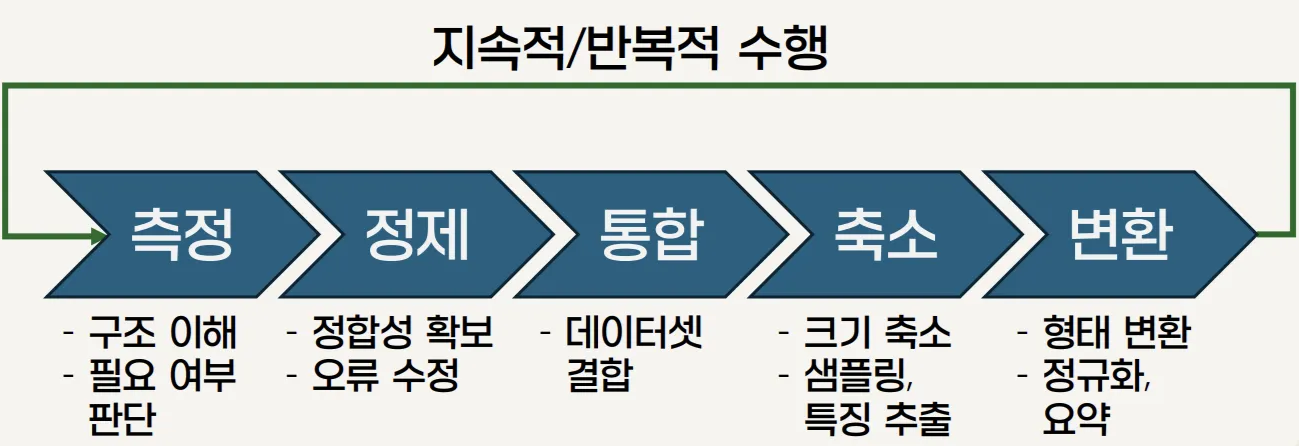
데이터 측정과 정제
- 데이터 측정
- 다양한 측정 요소들을 활용하여 데이터의 구조와 특징을 정량적으로 파악
- 데이터 정제
- 불완전성을 보완하고, 이상치를 탐지 및 완화하며, 데이터 간의 불일치성을 수정하는 일련의 과정
- 결측치(missing values) 처리
- 데이터셋 내에 특정 관측 값이 누락되어 있는 상태
- 이상치(outlier) 처리
- 데이터에 포함된 불규칙한 변동이나 오류를 의미
데이터 통합, 축소 및 변환
- 데이터 통합(data integration)
- 서로 다른 데이터 저장소로부터 데이터를 결합
- 하나의 일관된 데이터 집합을 구축하는 작업으로, 중복과 불일치를 제거
- 데이터 축소(data reduction)
- 방대한 데이터를 효율적으로 처리하기 위해 데이터의 크기를 줄이면서도 중요한 정보를 보존하는 과정
- 데이터 변환(data transformation)
- 데이터의 구조나 값을 규칙에 따라 변환하여 분석이 효율적으로 수행되도록 지원
데이터 전처리의 예
1
2
3
4
5
6
7
8
9
10
11
12
13
import pandas as pd
from sklearn.cluster import KMeans
data = {'나이': [25, 30, 22, 35, 40, 50, 28, 33, 45, 55],
'소득': [3000, 4000, 2800, 5000, 6000, 7000,
3200, 4500, 6200, 7200]
}
df = pd.DataFrame(data)
kmeans = KMeans(n_clusters = 3, random_state = 42)
df['군집'] = kmeans.fit_predict(df[['나이', '소득']])
print(df)
Pandas를 이용한 데이터 측정
데이터 측정
- 데이터의 형태, 값의 분포, 평균이나 중앙 값 같은 대표 값 등 데이터의 특성과 구조를 파악하는 과정
- 이를 통해 데이터 전처리 및 분석의 방향을 결정
- pandas 라이브러리의 역할
- 데이터의 저장 뿐만 아니라 평균, 분산, 최솟 값, 최댓 값 등 다양한 통계량 계산을 위한 기능 제공
- 데이터의 상태를 요약하는
describe(),info()메소드 사용
- 데이터 측정 요소
- 데이터 측정 기준
- 전체/레코드/그룹 별 측정
- 요약 통계 지표
- 데이터의 특징을 간단히 정리 · 이해
- 기타 통계 지표
- 데이터의 분포를 파악
- 데이터 측정 기준
요약 통계 지표
| 구분 | 지표 | 설명 |
|---|---|---|
| 중심 경향 | 평균 | 모든 값을 더한 후 개수로 나눈 값으로, 데이터의 대표성을 나타냄. 이상치에 민감 |
| 중심 경향 | 중앙 값 | 데이터를 크기 순으로 정렬했을 때 한가운데 위치한 값으로, 이상치의 영향을 덜 받음 |
| 중심 경향 | 최빈 값 | 데이터에서 가장 자주 출현하는 값으로, 범주형 데이터 분석에 유용 |
| 분산 정도 | 분산 | 각 데이터 값이 평균에서 얼마나 떨어져 있는 지를 제곱하여 평균 낸 값 |
| 분산 정도 | 표준편차 | 분산의 제곱근으로, 데이터의 흩어진 정도를 원래 단위로 표현해 직관적 |
| 분산 정도 | 범위 | 최댓 값에서 최솟 값을 뺀 값으로, 데이터의 전체 분포 폭을 파악하는 데 유용 |
| 분산 정도 | 사분위수 | 하위 25%(Q1), 50%(Q2, 중앙 값), 75%(Q3) 지점을 나타내며 데이터 분포를 시각적으로 이해하는 데 활용 |
| 분산 정도 | 사분위 범위(IQR) | Q3에서 Q1을 뺀 값으로, 중앙 50% 구간의 범위를 나타내며 이상치 탐지에 활용 |
기타 통계 지표
| 지표 | 설명 |
|---|---|
| 합계 | 모든 데이터 값을 더한 값으로, 데이터 총 합을 빠르게 확인할 때 사용 |
| 개수 | 데이터 항목 수를 나타내며, 결측치 여부 및 데이터 완전성 점검에 유용 |
| 최댓 값 | 데이터 집합에서 가장 큰 값으로, 데이터의 상한 경계를 확인하는 데 도움 |
| 최솟 값 | 데이터 집합에서 가장 작은 값으로, 데이터의 하한 경계 를 확인하는 데 도움 |
| 왜도 | 데이터 분포가 평균을 중심으로 대칭적인지, 한쪽으로 치우쳤는지를 나타내는 지표 |
| 첨도 | 데이터 분포의 뾰족한 정도를 측정하며, 이상치의 빈도 를 파악하는 데 유용 |
describe() 메소드
| 데이터 유형 | 제공 통계량 | 설명 |
|---|---|---|
| 수치형 데이터 | count | 데이터 개수 (결측치 제외) |
| 수치형 데이터 | mean | 평균 |
| 수치형 데이터 | std | 표준편차 |
| 수치형 데이터 | min | 최솟 값 |
| 수치형 데이터 | 25% | 제1사분위수(Q1), 하위 25% 위치 값 |
| 수치형 데이터 | 50% | 제2사분위수(Q2), 중앙 값(median), 하위 50% 위치 값 |
| 수치형 데이터 | 75% | 제3사분위수(Q3), 하위 75% 위치 값 |
| 수치형 데이터 | max | 최댓 값 |
| 범주형 데이터 | count | 데이터 개수 (결측치 제외) |
| 범주형 데이터 | unique | 고유 값(unique) 개수 |
| 범주형 데이터 | top | 최빈 값 |
| 범주형 데이터 | freq | 최빈 값의 빈도 |
describe() 메소드의 활용
1
2
3
4
5
6
7
8
9
10
11
12
13
14
data = {
'name': ['김민수', '이지영', '박준호', '최서연', '정도윤'],
'age': [25, 30, 28, 22, 35],
'city': ['서울', '부산', '인천', '서울', '대전'],
'score': [90, 85, 95, 80, np.nan]
}
df = pd.DataFrame(data)
print(df.describe())
print(df.describe(include=[np.number]))
print(df.describe(include=['object']))
연습 문제
-
다음 중 데이터 전처리 과정에 포함되지 않는 것은?
a. 변수 간 상관 관계 분석
- 데이터 전처리 과정
- 결측 값 처리
- 데이터 형식 변환
- 이상치 처리
- 데이터 전처리 과정
-
다음 중 이상치에 대한 설명으로 적절한 것은?
a. 다른 관측 값들과 비교해 극단적으로 차이나는 값이다
-
데이터 전처리 과정에서 변수 간 단위가 다를 경우 주로 사용하는 처리 기법은?
a. 정규화 또는 표준화
정리 하기
- 데이터 전처리는 원시 데이터를 분석에 적합한 형태로 정제하고 변환하는 과정임
- 입력 데이터의 품질이 분석 결과의 품질을 좌우함
- 데이터 측정은 특성 파악과 전처리 필요성 판단을 위한 기초 단계임
- 데이터 정제는 결측치, 잡음, 이상치 등을 처리하여 데이터 품질을 향상 시킴
- 데이터 통합은 여러 소스의 데이터를 결합하여 일관된 데이터 셋을 구성함
- 데이터 축소는 차원 축소, 데이터 압축 등을 통해 처리 효율성을 높임
- 데이터 변환은 정규화, 이산화 등을 통해 분석에 적합한 형태로 변형함
describe()메소드를 통해 데이터의 기술 통계량과 구조를 파악함