학습 개요
- 데이터 분석의 시작은 데이터를 이해하는 것에서 출발함
- 단순히 데이터를 처리하는 것을 넘어, 분석 대상 데이터를 통해 의미 있는 패턴과 통찰을 발견하고 이를 기반으로 문제를 해결하거나 의사 결정을 지원할 수 있어야 함
- 이를 위해 데이터 분석이 수행되는 절차와 분석 방법론에 대한 명확한 이해가 필요함
- 데이터 분석의 정의와 필요성, 그리고 분석 과정의 순환적 흐름에 대해 학습함
- 데이터 분석의 발전 과정(규칙 기반 분석, 통계적 모형, 기계 학습, 딥 러닝)과 특징을 비교함
- 탐색적 데이터 분석(EDA)의 중요성과 자동화 도구의 활용 방안을 통해, 실무 분석에서 데이터를 어떻게 바라보고 접근할 것인 지에 대해 학습함
학습 목표
- 데이터 분석의 개념과 필요성을 이해할 수 있음
- 데이터 분석의 주요 과정에서 수행되는 작업을 설명할 수 있음
- EDA의 중요성을 이해하고 기본적인 기법을 활용할 수 있음
강의록
데이터 분석의 이해
데이터 분석의 이해
- 데이터에서 의미 있는 패턴과 통찰을 발견하여 합리적인 의사 결정을 지원하는 기술
- 데이터 분석의 필요성
- 의사 결정의 질을 향상
- 비즈니스 문제의 근본 원인 파악
- 미래 예측 능력
- 데이터 분석 응용 분야 예
- 비즈니스 환경
- 고객 행동 이해, 시장 트렌드 파악, 운영 효율성 개선, 리스크 관리 등
- 공공 부문
- 정책 효과 평가, 자원 배분 최적화, 사회 문제 해결 등
- 비즈니스 환경
데이터 분석의 어려움과 과제
- 결측치, 오류, 중복, 불일치 등 다양한 품질 문제 존재
- 규모와 복잡성
- 빅데이터 시대의 5V(Volume, Velocity, Variety, Veracity, Value) 문제
- 기존 분석 도구와 방법론의 한계 초과
- 구조화된 데이터 뿐 아니라 비구조화 데이터 처리의 어려움과 고성능 컴퓨팅 환경 요구
- 방법론 선택의 난제
- 다양한 분석 방법론 중 최적 선택의 어려움
- 과도하게 복잡하거나 단순한 모델 적용의 위험성
- 데이터 특성과 분석 목적에 맞는 방법 결정 필요
데이터 분석의 과정
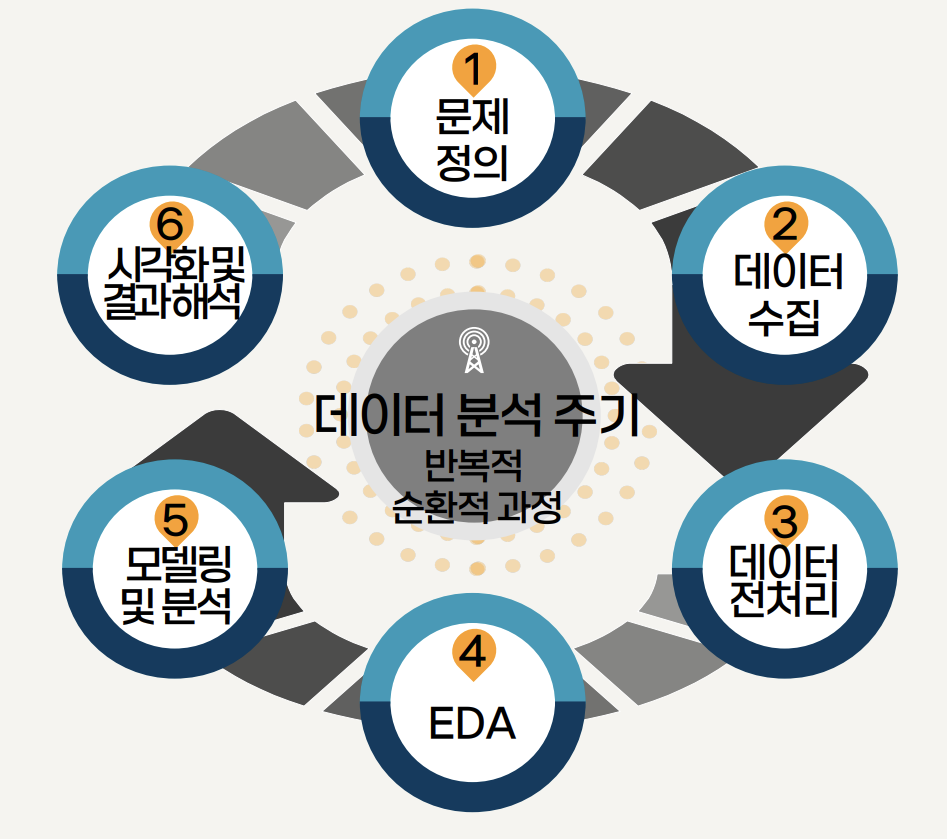
데이터 분석 과정
데이터 분석 방법론이 발전
- 1960년대: 규칙 기반 분석의 시작
- 1980년대: 통계적 방법론의 발전
- 2000년대 초: 기계 학습의 출현
- 2010년대 초: 딥 러닝의 혁신
- 2015년대: 자동화된 기계 학습
- 2020년대: 대규모 언어 모델의 발전
규칙 기반 분석
- 전문가의 경험과 직관에 기반한 분석 방식
- 특정 조건과 규칙을 명시적으로 프로그래밍
- ‘if-then’ 형태의 논리적 규칙 적용
- 분석가의 도메인 지식이 직접적으로 분석 과정에 반영
- 규칙 기반 분석의 장점
- 투명성과 해석 가능성이 높음
- 복잡한 통계나 수학적 지식 없이도 구현 가능
- 규칙 기반 분석의 단점
- 복잡하고 비선형적인 패턴 포착 어려움
- 새로운 상황이나 예외적 경우에 대한 일반화 능력 부족
규칙 기반 분석의 예
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
def loan_approval_rule(age, income, credit_score):
if age < 18:
return "거부: 미성년자"
elif income < 6000000:
return "거부: 소득 불충분"
elif credit_score < 600:
return "거부: 신용 점수 불충분"
elif income >= 100000000 and credit_score >= 950:
return "승인: 최우선 고객"
elif income >= 70000000 and credit_score >= 900:
return "승인: 우수 고객"
elif income >= 20000000 and credit_score >= 850:
return "승인: 일반 고객"
else:
return "추가 검토 필요"
통계적 모형을 활용한 분석
- 데이터에서 패턴과 관계를 발견하고 이를 수학적으로 모델링하는 접근 방식
- 기술 통계
- 중심 경향(평균, 중앙 값, 최빈 값), 분산 정도(표준편차, 분산, 범위), 분포 형태(정규성, 왜도, 첨도) 등
- 추론 통계
- 표본 데이터를 바탕으로 모집단에 대한 일반화된 결론을 도출하는 데 중점
- 가설 검정, 신뢰 구간 추정, 회귀 분석 등
- 데이터가 특정 분포(예: 정규 분포)를 따른다는 가정이 성립하지 않을 경우 모형의 정확성과 신뢰성이 저하
기계 학습을 활용한 분석
- 지도 학습
- 입력 값과 정답(레이블)을 함께 학습
- 분류(이메일 스팸 필터링, 이미지 인식 등), 회귀(주택 가격 예측, 판매량 예측 등)에 활용
- 비지도 학습
- 정답(레이블) 없이 데이터의 패턴과 구조를 발견하는 방법
- 군집화(이상 탐지 등), 차원 축소, 연관 규칙 학습(상품 추천 등)에 활용
- 강화 학습
- 환경과 상호 작용하는 에이전트가 보상을 최대화하는 행동 정책을 학습하는 방법
딥 러닝과 인공 지능 모형을 활용한 분석
- 인간의 뇌를 모방한 인공 신경망을 기반으로 하는 기계 학습의 한 분야
- 다층 구조의 인공 신경망
- 각 층은 전 층의 출력을 입력으로 받아 추상적인 특징 추출
- 계층적 표현 학습을 통해 복잡한 패턴 학습
- 저수준의 특징부터 고수준의 특징까지 자동으로 학습 가능
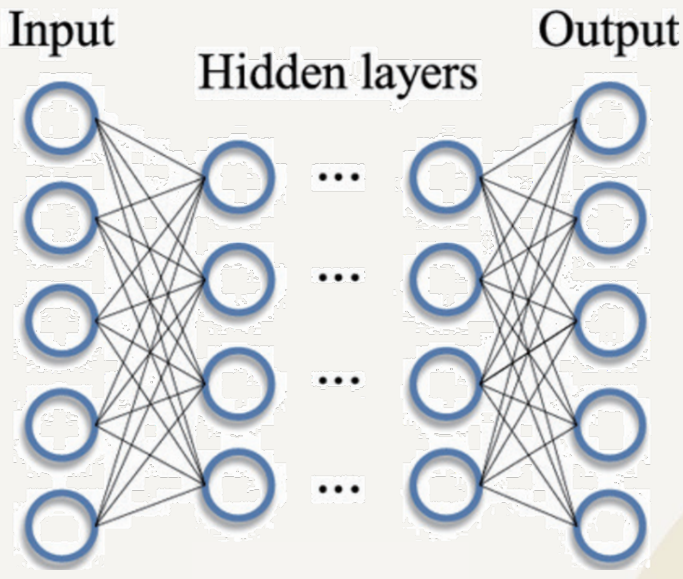
딥 러닝 모델
- 비정형 데이터 분석에 새로운 가능성을 제시
- 데이터 유형에 따라 다양한 구조로 발전
- CNN: 컴퓨터 비전 분야에 적합
- RNN, LSTM, GRU: 텍스트나 시계열 데이터
- 트랜스포머: 자연어 처리 분야
- 대규모 언어 모델(LLM)

탐색적 데이터 분석
탐색적 데이터 분석(EDA)의 개념과 중요성
- “데이터가 무엇을 말하는지 들어보라”는 철학에서 시작
- 데이터의 기본적인 특성과 구조를 이해하기 위한 분석 과정
- 데이터에 내재된 패턴, 변수 간 관계, 이상점, 트렌드 등을 발견하는 체계적인 접근법
- EDA의 중요성
- 데이터 품질 문제를 조기에 발견하고 변수 간의 관계와 패턴을 파악
- 분석 방향과 가설을 수립하는 데 기여
- EDA의 접근법
- 기술 통계량 분석과 데이터 시각화라는 두 가지 주요 접근법을 활용
자동화된 EDA 도구
- 자동화 EDA의 필요성
- 새로운 데이터셋은 데이터 탐색에 많은 시간과 노력을 요구
- 반복적이고 기계적인 작업들이 많아 효율성이 저하
- 자동화 EDA 도구의 기능
- 기본적인 통계 분석, 변수 간 상관 관계 파악, 데이터 시각화 등을 몇 줄의 코드로 수행
- 고차원적인 분석과 모델링에 집중할 수 있도록 보조
1
2
3
4
5
6
7
8
import seaborn as sns
from ydata_profiling import ProfileReport
df = sns.load_dataset('iris')
profile = ProfileReport(df, title = "붓꽃 데이터셋 분석 보고서")
profile.to_file("iris_profile.html")
profile
연습 문제
-
데이터 분석의 가장 주요한 목적은 무엇인가?
a. 의미 있는 패턴과 통찰 발견
-
통계적 분석 기법에 해당하는 것은 무엇인가?
a. 회귀 분석
-
탐색적 데이터 분석(EDA)의 주요 목적은 무엇인가?
a. 데이터의 특성과 구조 이해
정리 하기
- 데이터 분석은 데이터에서 의미 있는 패턴과 통찰을 발견하여 합리적인 의사 결정을 지원함
- 데이터 분석 과정은 문제 정의, 데이터 수집, 데이터 전처리, 탐색적 데이터 분석, 데이터 모델링, 데이터 시각화, 결과 해석의 단계로 구성됨
- 규칙 기반 분석은 투명성과 해석 가능성은 높지만 복잡한 패턴 포착에 한계가 있음
- 통계적 모형은 확률론과 수리 통계학에 기반하여 데이터의 분포, 변수 관계, 불확실성을 수학적으로 표현함
- 기계 학습은 데이터로부터 패턴을 자동으로 학습하고 예측함
- 딥 러닝은 다층 인공 신경망을 기반으로 복잡한 패턴을 학습하는 기법으로 비정형 데이터 처리에 강점이 있음
- EDA는 데이터의 특성과 구조를 이해하기 위한 분석 과정임
- 자동화된 EDA 도구를 활용하여 기본적인 데이터 특성을 효율적으로 파악할 수 있음