학습 개요
- DBMS는 대량의 데이터를 여러 사용자가 동시에 접근하고 공유할 수 있도록 지원하는 시스템으로, 장애 상황에서도 중단 없는 서비스를 제공해야 함
- 그러나 트랜잭션 수행 중의 논리적 오류, 디스크 손상과 같은 하드웨어적 결함, 또는 시스템 소프트웨어의 예외 상황 등 다양한 원인으로 인해 데이터의 일관성이 손상되거나 시스템이 정상적으로 동작하지 않을 수 있음
- 이러한 상황에서도 DBMS는 데이터베이스를 일관되고 안정된 상태로 복원할 수 있어야 하며, 이를 위해 회복 시스템(recovery system)을 갖추고 있음
- 회복 시스템의 개념과 필요성을 이해하고, 장애 발생 시 데이터베이스를 정상 상태로 복원하기 위해 사용되는 주요 기술들을 학습함
- 특히 트랜잭션의 원자성을 보장하기 위한 로그 기반 회복 기술, 주기적인 저장 시점을 기록하는 체크포인트 기법, 그리고 백업과 복구 전략에 대해 구체적으로 살펴봄
주요 용어
- 버퍼 블록
- 디스크로부터 읽어들여져 주 기억 장치에 임시적으로 있는 블럭
- 로그 레코드
- 데이터베이스가 수행하는 모든 수정 작업을 기록한 데이터
- WAL
- 데이터베이스 수정 전, 로그 레코드를 생성하여 기록하여 변경 기록에 대한 로그를 안정하게 저장하는 기법
- 체크 포인트
- 회복 작업에 소모되는 비용 감소를 위해 주기적으로 모든 수정 작업을 중단하고 메인 메모리 상의 수정 된 모든 버퍼 블럭을 디스크에 반영 시키는 기법
강의록
회복 시스템의 개념
회복의 역할
- 예상치 못한 HW 고장 및 SW 오류가 발생
- 사용자의 작업에 대한 안정적 디스크 반영 여부 보장이 불가능
- 오류 발생 이전의 일관된 상태로 데이터베이스를 복원 시키는 기법이 요구
- 고장 원인 검출, DBMS의 안전성 및 신뢰성을 보장
-
데이터베이스는 데이터 복원 절차 내재화
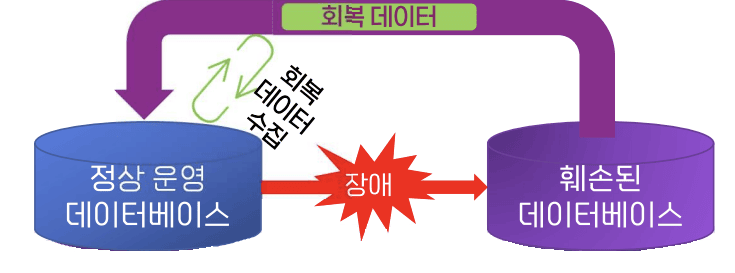
- 정상 운영 데이터베이스에서 장애 발생 시 훼손된 데이터베이스가 됨
- 회복 데이터를 수집하여 (회복 데이터) 훼손된 데이터베이스를 복원
시스템 실패(system failure)의 유형
- 트랜잭션 실패
- 논리적
- 잘못된 데이터 입력, 부재, 버퍼 오버플로, 자원 초과 이용
- 시스템적
- 운용 시스템의 교착 상태 발생
- 논리적
- 시스템 장애
- 시스템의 하드웨어 고장, 소프트웨어의 오류
- 주 기억 장치와 같은 휘발성 저장장치의 내용 손실
- 디스크 실패
- 비 휘발성 디스크 저장 장치의 손상 및 고장으로 인한 데이터 손실
- 디스크
- 영구 저장을 하는 가장 중요한 장치
회복 데이터의 구성
- 백업
- 데이터베이스의 일부 또는 전체를 주기적으로 별도의 저장 장치에 복제하는 방식
- 로그
- 데이터 변경 이전과 이후의 값을 별도의 파일에 누적 기록하는 방식
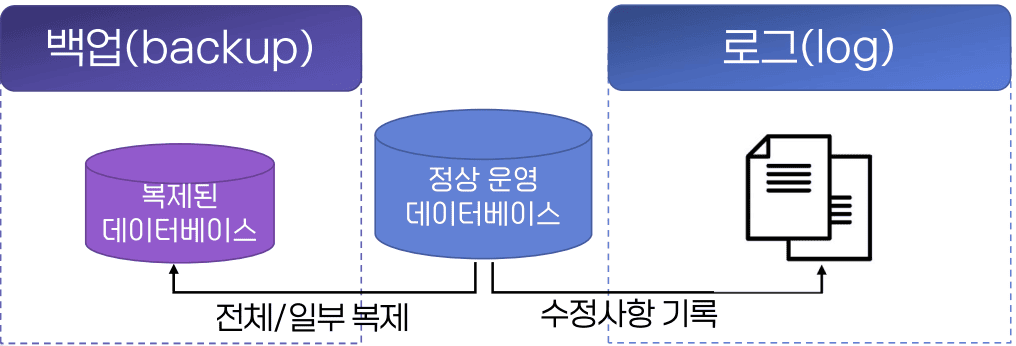
- 백업(backup)
- 정상 운영 데이터베이스 → 복제된 데이터베이스 (전체/일부 복제)
- 로그(log)
- 정상 운영 데이터베이스 → 수정 사항 기록
데이터 저장 구조
- 전체 데이터는 디스크와 같은 비 휘발성 저장장치에 저장되며, 일부의 데이터만 주 기억 장치에 상주
- 데이터베이스는 데이터를 블록(block) 단위로 전송하고 블록 단위로 기억 장소를 분할
- 트랜잭션은 디스크로부터 주 기억 장치로 데이터를 가져오며, 변경된 데이터는 다시 디스크에 반영
- 가져오기, 내보내기 연산은 블록 단위로 실행
- 물리적 블록
- 디스크 상의 블록
- 버퍼 블록
- 주 기억 장치에 임시적으로 상주하는 블록
- 물리적 블록
- 가져오기, 내보내기 연산은 블록 단위로 실행
데이터베이스 연산 처리 과정
- 메인 메모리와 디스크 사이의 연산
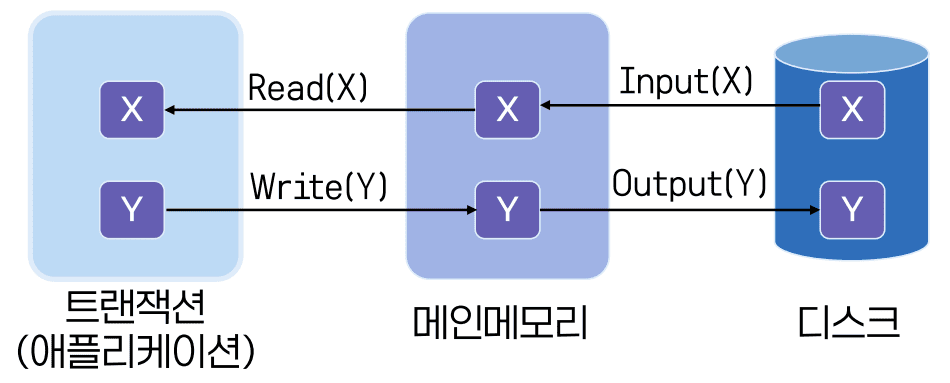
- Input(X)
- 물리적 블록 X를 메인 메모리에 적재
- Output(X)
- 버퍼 블록 X를 디스크에 저장
- Input(X)
Read와 Write 연산 처리 과정
- Read(X)의 처리 과정
- 버퍼 블록 X가 메인 메모리에 없을 경우 Input(X)를 수행
- 버퍼 블록 X의 값을 변수 x에 할당
- Write(X)의 처리 과정
- 버퍼 블록 X가 메인 메모리에 없을 경우 Input(X)를 수행
- 변수 x의 값을 버퍼 블록 X에 할당
로그 기반 회복
로그 기반 회복의 개념
- 데이터베이스가 수행한 모든 수정 작업을 기록한 여러 종류의 로그를 사용하여 회복하는 시스템
- 로그 레코드의 종류
- <Tᵢ,Xⱼ,V₁,V₂>
- Tᵢ가 데이터 항목 변경 연산을 수행하여 Xⱼ의 값을 V₁에서 V₂로 변경
- <Tᵢ,start>
- Tᵢ가 시작
- <Tᵢ,commit>
- Tᵢ가 커밋
- <Tᵢ,abort>
- Tᵢ가 취소
- <Tᵢ,Xⱼ,V₁,V₂>
데이터 항목 변경
- WAL (Write-Ahead Log)
- 트랜잭션은 데이터베이스 수정 전, 로그 레코드를 생성하여 기록
-
트랜잭션(애플리케이션)에서 Write(X) 요청이 오면, 로그 디스크에 <Tᵢ,Xⱼ,V₁,V₂> 로그를 먼저 기록하고, 그 다음 메인 메모리에서 X를 변경한 후, 운영 DB의 Output(X)로 X를 반영
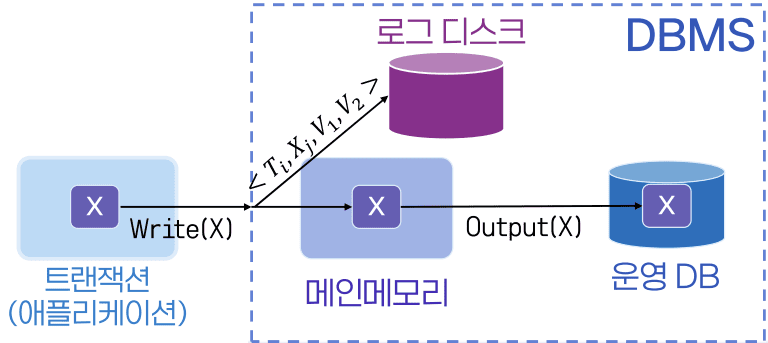
- 데이터 항목 변경
- 로그 디스크
- 변경 과정 저장용
- 운영 DB
- 영구적으로 디스크 저장
- 데이터는 안바뀌고, 로그만 바뀐 것도 오류
- 로그 레코드의 수정 기록을 보고 DB에 반영하면 됨
- 로그 디스크
회복을 위한 연산
- 회복 기법은 로그에 대해 두 연산을 사용
- Redo(Tᵢ)
- Tᵢ에 의하여 수정된 새로운 값으로 데이터베이스의 데이터 항목을 수정
- 디스크 상 반영 X
- 메모리에서만 반영 O
- Undo(Tᵢ)
- Tᵢ에 의해 수정된 모든 데이터 항목을 이전 값으로 복귀, 완료 후 <Tᵢ,abort> 기록
- 트랜잭션이 잘 수행(commit) 또는 잘못 되었다(abort) 요청이 없는 상태
- Redo(Tᵢ)
- 시스템 장애 발생 시
- 로그에 <Tᵢ,start>가 있지만 <Tᵢ,commit> 또는 <Tᵢ,abort>를 포함하는 경우 Tᵢ를 Redo
- 로그에 <Tᵢ,start>가 있지만 <Tᵢ,commit> 또는 <Tᵢ,abort>를 포함하지 않는 경우 Tᵢ를 Undo
데이터베이스 변경과 커밋
- 데이터베이스 변경 시 복구 알고리즘의 고려 사항
- 트랜잭션의 일부 변경 사항이 버퍼 블록에만 반영되고 물리 블록에 기록되지 않은 상태에서 트랜잭션이 커밋 되는 상황
- 트랜잭션이 동작 상태에서 데이터베이스를 수정했으나 수정 후에 발생한 실패로 취소가 필요한 상황
- 트랜잭션 커밋 상황
- <Tᵢ,commit> 로그 레코드가 안정된 저장 장치에 기록 완료 시 트랜잭션 커밋으로 간주
- <Tᵢ,commit> 로그 레코드가 기록되기 전에 장애가 발생하면 롤백
회복의 유형
- 회복은 트랜잭션에 의해 요청된 갱신 작업이 디스크에 반영되는 시점에 따라 구분
- 갱신 작업이 디스크에 반영 되는 시점
- DBMS가 적용할 수 있는 두가지 정책
- 즉시 갱신 회복
- 지연 갱신 회복
- DBMS가 적용할 수 있는 두가지 정책
- 갱신 작업이 디스크에 반영 되는 시점
- 지연 갱신 회복 (deferred update restore)
- 부분 커밋까지 디스크 반영을 지연 시키고 로그에만 기록
- 실패 시, 별도의 회복 작업 필요 없이 로그만 수정
- 트랜잭션에 의해 데이터 변경이 발생할 때마다 메인 메모리에서 디스크로 반영
- 최대한 메인 메모리에서만 수정하고 디스크에는 나중에 반영
- 디스크에 아직 반영 안 된 상태
- 로그 레코드에만 있음
- 회복 시 디스크의 값을 되돌릴 필요 X
- 즉시 갱신 회복 (immediate update restore)
- 갱신 요청을 곧바로 디스크에 반영
- 실패 시, 디스크에 반영된 갱신 내용을 로그를 바탕으로 회복
- 메인 메모리에서 수정을 진행하다가 특정 시점이 되었을 때 DB에 반영
- 디스크에 바로 반영이 됨
- 다시 이전 값으로 되돌리는 작업이 필요
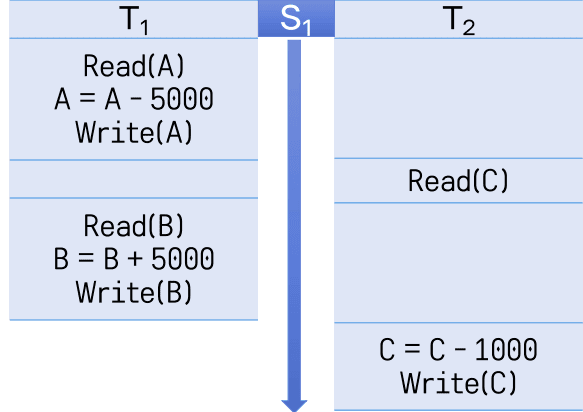
은행 시스템의 트랜잭션 예
- 초기값 A=30,000, B=10,000, C=50,000
-
T1은 A에서 5000을 빼고, B에 5000을 더하며, T2는 C에서 1000을 빼는 작업
로그와 데이터베이스 상태

시스템 장애 발생 상황

체크포인트의 필요
- 로그 기반 회복 시스템의 한계
- 로그의 크기는 시간이 지남에 따라 계속 증가하므로 대용량 로그의 탐색 비용이 매우 커짐
- Redo를 해야하는 트랜잭션 중 대부분은 이미 데이터베이스에 반영
- 반영된 트랜잭션의 재실행은 시스템 자원의 낭비
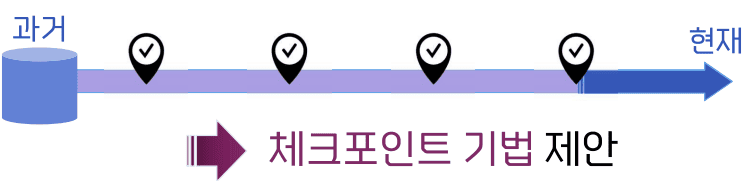
체크포인트 기법
- 현재 시점에 메인 메모리의 버퍼 블록에 존재하는 모든 로그 레코드를 안정 저장장치로 기록
- 수정 된 모든 버퍼 블록을 디스크에 반영
- 로그 레코드 <checkpoint ListT>를 안정된 저장 장치에 기록
- ListT는 체크포인트 시점에 실행 중인 트랜잭션 목록
- checkpoint ListT
- 지금 실행 중인 것은 나중에 오류 생겼을 때 볼 것
체크포인트를 이용한 회복
- 체크포인트 기법을 이용한 회복 과정
- 로그의 마지막부터 역방향으로 탐색하여 <checkpoint ListT> 레코드를 찾음
- ListT에 존재하는 <checkpoint ListT> 이후에 실행된 트랜잭션에 대해서만 Redo와 Undo 연산 수행
- 로그에 <Tᵢ,commit> 또는 <Tᵢ,abort>가 없는 ListT안의 모든 트랜잭션을 Undo
- 트랜잭션의 작업이 최종 완료 되지 않음
- 이전 값으로 다시 덮어씀
- 로그에 <Tᵢ,commit> 또는 <Tᵢ,abort>가 있는 ListT안의 모든 트랜잭션을 Redo
- 커밋된 트랜잭션에 한해,장애 발생 시 로그를 참조하여 변경 사항을 디스크에 재실행
- 로그에 <Tᵢ,commit> 또는 <Tᵢ,abort>가 없는 ListT안의 모든 트랜잭션을 Undo
회복 알고리즘
트랜잭션 Tᵢ의 롤백 알고리즘
- 특정 트랜잭션 Tᵢ가 자체적인 오류, 명시적인 철회(Abort) 요청 등으로 인해 정상적으로 완료되지 못했을 때, 해당 트랜잭션이 데이터베이스에 적용한 모든 변경 사항을 취소(Undo)하는 과정
- 1단계
- 로그를 역방향으로 탐색
- 트랜잭션 Tᵢ와 관련 된 로그 레코드 찾음
- 로그를 역방향으로 탐색
- 2단계
- Tᵢ의 로그 레코드 <Tᵢ,Xⱼ,V₁,V₂>에 대하여
- 트랜잭션 Tᵢ가 데이터 항목 Xⱼ의 값을 V₁에서 V₂로 변경했다는 의미
- 데이터 항목 Xⱼ에 V₁ 기록
- 이전 값으로 되돌림
- 로그 레코드 <Tᵢ,Xⱼ,V₁>을 로그에 기록
- Undo 작업 수행한 로그를 추가 기록
- Tᵢ의 로그 레코드 <Tᵢ,Xⱼ,V₁,V₂>에 대하여
- 3단계
- <Tᵢ,start>를 찾은 이후
- 역방향 탐색을 중단
- 로그 레코드 <Tᵢ,abort>를 로그에 기록
- <Tᵢ,start>를 찾은 이후
시스템 장애 후 회복 알고리즘
- 시스템 장애 이후, 재 시작 시 Redo와 Undo 단계를 수행
- 장애 직전까지 커밋(Commit)된 트랜잭션의 변경 사항은 모두 디스크에 반영(Redo)하고, 커밋 되지 않은 트랜잭션의 변경 사항은 모두 취소(Undo)하는 것이 목표
- Redo 단계
- 최근의 체크 포인트에서부터 순 방향 로그 탐색
- 롤백 대상할 트랜잭션의 Undo 리스트인 ListofUndo를 ListT로 초기화
- 체크포인트 시점에 진행 중이었던 트랜잭션(ListT)들은 장애 시점까지 커밋 되었는 지 확인이 필요하므로 일단 Undo 대상 후보로 간주
- <Tᵢ,Xⱼ,V₁,V₂>, <Tᵢ,Xⱼ,V₁> 형태의 모든 레코드를 재 실행
- 로그를 읽으면서 나오는 모든 데이터 변경 작업(일반 업데이트 레코드 및 보상 로그 레코드)을 그대로 재실행
- 장애 직전 메모리 상태를 그대로 재현
- <Tᵢ,start> 발견 시, Tᵢ를 ListofUndo에 추가
- 새로운 트랜잭션이 시작되면, 이 트랜잭션도 커밋되지 않고 종료되었을 수 있으므로 ListofUndo에 추가
- <Tᵢ,abort>, <Tᵢ,commit> 발견 시 Tᵢ를 Undo 리스트에서 제거
- 트랜잭션 Tᵢ가 커밋되었거나 이미 철회(abort)된 것이 확인되면, 더 이상 Undo할 필요가 없으므로
시스템 장애 후 회복 알고리즘 (Undo 단계)
- Undo 단계 (역방향 로그 탐색)
- ListofUndo의 트랜잭션의 로그 레코드를 찾으면 트랜잭션 롤백 알고리즘 1단계 수행
- ListofUndo의 트랜잭션 Tᵢ에 대해 <Tᵢ,start>를 만나면 로그에 <Tᵢ,abort>를 기록하고 ListofUndo에서 제거
- ListofUndo에 트랜잭션이 존재하지 않는 상태가 되면 Undo 단계를 종료
로그를 통한 회복 작업 과정
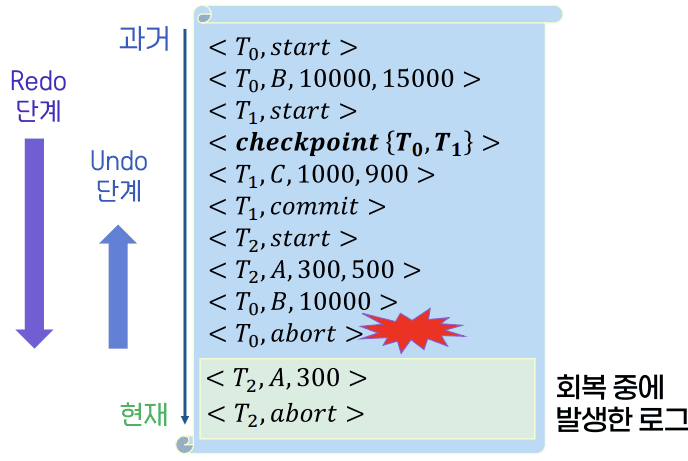
- Redo 단계 (체크포인트부터 순방향 탐색)
- 회복 관리자가 시스템을 재시작
<checkpoint {T₀, T₁}>발견ListofUndo = {T₀, T₁}로 초기화함
<T₁, C, 1000, 900>발견- Redo
- 데이터 C의 값을 900으로 변경함
- Redo
<T₁, commit>발견- T₁은 커밋 된 트랜잭션임
ListofUndo에서 T₁을 제거함ListofUndo = {T₀}
<T₂, start>발견ListofUndo에 T₂를 추가함ListofUndo = {T₀, T₂}
<T₂, A, 300, 500>발견- Redo
- 데이터 A의 값을 500으로 변경함
- Redo
<T₀, B, 10000>발견- Redo
- 데이터 B의 값을 10000으로 변경함
- 만약 T₀가 장애 발생 전에 이미 롤백 중이어서 이 레코드가 보상 로그 레코드였다면, 이 Redo는 그 롤백 작업을 재실행하여 B를 10000으로 만드는 것을 보장함
- Redo
<T₀, abort>발견- T₀는 철회된 트랜잭션임
ListofUndo에서 T₀를 제거함ListofUndo = {T₂}
- 로그의 끝에 도달 (장애 발생 지점)
- Redo 단계가 종료 됨
- 현재
ListofUndo = {T₂}- 즉, T₂는 장애 발생 시점까지 완료되지 않은 패자 트랜잭션임
- Undo 단계 (로그 끝에서 역방향 탐색)
ListofUndo = {T₂}인 상태로 Undo 단계를 시작함- 로그를 역방향으로 탐색하며 T2와 관련된 작업을 찾음
<T₀, abort>- T₀는
ListofUndo에 없으므로 무시
- T₀는
<T₀, B, 10000>- T₀는
ListofUndo에 없으므로 무시
- T₀는
<T₂, A, 300, 500>- T₂의 로그 레코드 발견
- 트랜잭션 롤백 알고리즘에 따라 Xᵢ(A)의 값을 V₁(300)으로 되돌림
- A = 300
- 보상 로그 레코드
<T₂, A, 300>을 로그에 기록함
<T₂, start>- T₂의 시작 레코드 발견
- T₂의 모든 변경이 취소되었으므로, 로그에
<T₂, abort>를 기록함 ListofUndo에서 T₂를 제거함ListofUndo = {}
ListofUndo가 비었으므로 Undo 단계 및 전체 회복 과정이 종료 됨
연습 문제
-
다음과 같은 스토리지 구조와 상태에서 트랜잭션에 의해 Write(X)를 실행하기 위한 첫 번째 단계로 올바른 것은? (단, 데이터 항목 x는 블록 X에 존재한다고 가정한다)
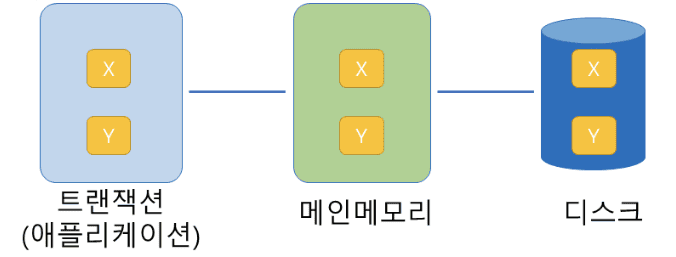
a. Input(X)를 수행한다.
- Write(A)를 수행하기 위해서 DBMS는 데이터 항목 A가 존재하는 블록이 현재 메모리 상에 존재하는지 확인한 후, 존재하지 않을 경우 Input(X)를 수행하여 메모리 상으로 읽어들어들임
- 이 후 X내의 A에 xi값을 할당하고 마지막으로 Output(X)를 수행함
-
Write 연산을 수행할 때 마다 데이터베이스가 변경되기 전에 로그 레코드를 우선 로그에 추가하는 방식을 무엇이라고 하는가?
a. Write Ahead Log
- 로그는 데이터베이스 회복을 위한 데이터로 어떠한 연산이 수행된 이후에 로그가 기록되지 않은 상태에서 데이터베이스 오류가 발생할 경우, 회복할 수가 없기 때문에 로그 레코드를 먼저 기록한 후, Write 연산을 수행함
- 이를 Write Ahead Log, WAL이라고 함
-
다음 중 체크포인트에 의해 발생하는 작업이라고 할 수 없는 것은?
a. 트랜잭션의 명령을 분석하여 Undo할 트랜잭션과 Redo할 트랜잭션을 구분함
- 체크포인트는 로그를 이용한 회복 작업에 필요한 비용 감소를 위해 주기적으로 수정된 버퍼를 디스크에 반영하고 로그 레코드
를 기록하는 것을 말함 - 체크 포인트에 의해 발생하는 작업
- 현재 메인 메모리에 존재하는 모든 로그 레코들르 안정 저장 장치에 기록함
- 수정 된 모든 버퍼 블록을 디스크에 반영함
- 로그 레코드
를 안정 저장 장치에 기록함
- 체크포인트는 로그를 이용한 회복 작업에 필요한 비용 감소를 위해 주기적으로 수정된 버퍼를 디스크에 반영하고 로그 레코드
정리 하기
- 데이터 회복이란 데이터베이스 운영 도중에 발생하는 예기치 못한 실패나 고장이 발생한 경우, 데이터베이스를 실패 및 고장 발생 이전의 일관적인 상태로 되돌리는 작업을 의미함
- 실패 유형에는 논리적 오류나 버퍼 오버플로 등의 요인에 의한 트랜잭션 실패, 하드웨어 고장 등으로 인한 시스템 장애, 디스크 손상으로 인한 디스크 실패가 있음
- 디스크와 주기억 장치 사이에 블럭 단위로 데이터가 이동 되며, 디스크 상의 블록은 물리적 블럭, 주기억 장치 상의 블럭은 버퍼 블록이라고 함
- 데이터베이스 응용에서의 데이터 조작은 버퍼 블럭에서 이루어지며, 트랜잭션 완료나 버퍼의 여유 공간이 없을 때 버퍼 블럭이 디스크에 기록 됨
- 데이터베이스 회복을 위해 가장 많이 사용 되는 로그 기반 회복 기법은 데이터베이스 시스템이 기록한 모든 수정 작업에 대한 기록을 유사 시 데이터베이스를 이전 상태로 복구하는 데에 사용하는 기법임
- 데이터베이스 회복 시 각각의 트랜잭션은 Redo나 Undo 됨
- 문제 없이 진행되어야 했을 트랜잭션의 경우 Redo 되며, 완료되지 못한 상황에서 예기치 않게 종료 되어 데이터베이스의 일관성을 해칠 위험이 있는 트랜잭션의 경우 Undo 됨
- 장기간 데이터베이스 운용으로 시스템 장애 발생 시 재 실행해야 할 로그의 양이 방대해지기 때문에 체크 포인트를 실행하여 최근의 실행 된 체크 포인트 이후의 로그만으로도 데이터베이스를 회복할 수 있는 방법을 제공함
- 체크 포인트를 생성하는 작업은 메모리에 존재하는 모든 로그 레코드를 안정 저장 장치로 기록한 후, 수정 된 모든 버퍼 블럭을 디스크에 반영함
- 이후 현재 실행 중인 트랜잭션의 리스트를 표시한 레코드를 안정 저장 장치에 기록함
- 회복 과정은 오류가 발생하기 전까지 트랜잭션의 실행 상태에 따라 Redo 또는 Undo 작업으로 분류 됨
- 정상적으로 완료 된 트랜잭션에 대해서는 Redo를 실행하며, 불완전하게 실행 된 트랜잭션은 로그를 역순으로 읽어 트랜잭션 실행 전까지 되돌림
- 체크 포인트를 사용하는 시스템에 대해서는 마지막 체크 포인트를 확인하고 그 이후의 로그에 대해서만 정상적으로 반영 되었는지 확인하여 Redo 또는 Undo 하면 무결성 데이터베이스를 유지할 수 있음
체크 포인트
-
다음의 검사점(checkpoint)이 있는 로그에서 시스템 고장이 발생하는 경우 재수행(redo)을 해야하는 트랜잭션만을 모두 고른 것은?
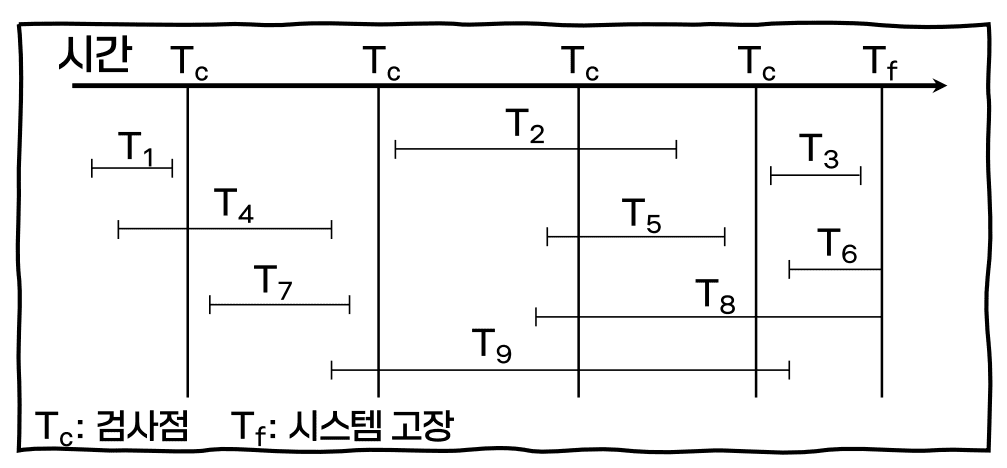
a. T₃, T₉
- 마지막으로 체크 포인트가 일어난 이후, 실패가 일어나기 이전에 커밋 된 트랜잭션에 대해서는 진행을 다시 해야 함
-
즉시 갱신 전략을 이용하는 회복 시스템에서 다음과 같은 로그 기록을 사용하여 복구 과정을 수행한 내용 중 옳지 않은 것은?

a. 트랜잭션 T₃는 undo 를 수행하여 C값으로 30을 저장한다.
- 커밋이 된 작업이기 때문에 이 작업을 다시 수행 해야 하는 redo 작업을 해야 하고 45가 되었는지 확인해야 함
- 즉시 갱신 전략을 이용하는 회복 시스템에서 다음과 같은 로그 기록을 사용하여 복구 과정을 수행한 내용 중 옳은 것
- 트랜잭션 T₁은 복구 작업을 수행할 필요가 없음
- 트랜잭션 T₂는 undo를 수행하여 B값으로 20을 저장함
- 트랜잭션 T₅는 undo를 수행하여 D값으로 20을 저장함