학습 목표
- 파일의 역할에 대해 설명할 수 있음
- 파일 함수를 통해 데이터를 읽고 쓰고 추가할 수 있음
- 딕셔너리를 사용할 수 있음
주요 용어
- 파일 이름
- 파일 경로를 내포하는 파일의 고유 식별자
- 파일 포인터
- 파일 내부에서 작업 위치를 나타내는 포인터
- 딕셔너리
- 키와 값의 쌍을 저장하는 시퀀스
강의록
파일의 이해
파일의 역할
- 컴퓨터에 의해 처리될 또는 처리된 데이터와 정보가 임시적으로 저장된 상태
- 일련의 연속된 바이트
- 프로그램(파이썬 소스 코드)에 읽혀 가공 · 처리

- 자동화할 도구
- 처리 및 가공
파일의 구성
-
연속된 바이트와 파일의 시작, 파일 포인터, 파일의 끝(EoF)으로 표현

파일의 종류
- 데이터가 저장되는 방식에 따라 구분
-
텍스트 파일

-
바이너리 파일

- 실제 바이너리의 숫자로 저장
- 적은 데이터 용량
-
파일 함수
-
파일의 시작, 파일 포인터, 파일의 끝을 활용하여 데이터 읽기, 쓰기를 위한 함수 및 메소드를 내장
멤버 설명 open(): file obj파일과 연결되어 있는 파일 객체 생성 read()특정 개수의 문자를 반환 readline()한 라인의 문자열을 반환 readlines(): list전체 라인의 문자열을 리스트로 반환 write(s: str):파일에 문자열을 작성 close()파일 닫기 및 파일 객체 삭제 - 객체 지향
- 대규모의 프로그램을 유용하게 사용할 수 있는 새로운 패러다임
- 객체
- 생성, 사용, 삭제의 과정을 거침
- 객체의 Life cycle 생애 주기
- 객체가 프로그램 내부에서 사용되는 과정에 대한 고민
- Garbage Collector
- 파이썬 인터프리터는 참조 변수로 쓰이지 않는 객체들을 주기적으로 점검하고 정리함
- 파일
- 생성, 사용, 삭제의 과정을 거침
파일 객체 생성
-
구문 형식
1
파일객체_참조변수 = open(파일이름, 모드)
- 물리적인 파일과 연결된 파일 객체를 생성하고 참조 변수에 할당
모드 설명 'r'읽기 용도 'w'새로운 파일을 쓰기 용도 'a'파일의 끝에 데이터를 덧붙이기 용도 -
open함수를 사용하는 것 빼고는 객체 사용법과 거의 동일
파일 이름
- 파일의 고유 식별자 역할 및 저장 장치 내부에서 파일의 위치를 표현하는 파일 경로를 내포
- 해당 파일에 접근하기 위한 모든 정보가 다 들어있음
- 파일의 현재 위치 정보도 가지고 있음
- 파이썬 프로그램이 텍스트 파일과 같은 폴더에 있다면 앞의 경로 생략 가능

- 해당 파일에 접근하기 위한 모든 정보가 다 들어있음
파일 읽기
- 특정 범위의 데이터를 파일에서 읽고 문자열로 반환
- 파일 포인터의 이동을 동반

1 2 3 4
h_fp = open("Hamlet_by_Shakespeare.txt", "r") # 경로가 없는 걸로 보아 같은 폴더 내에 있다는 뜻, 읽기 모드 사용 title = h_fp.read(6) # 입력 받은 바이트 수 만큼 파일 포인터를 읽으면서 데이터를 반환함 author = h_fp.readline() # 다음에 있는 개행 포인터가 보일 때까지 쭉 읽어들이는 함수 h_fp.close()
\n- new line character
- 한 줄을 밑으로 내려라
close()를 하지 않았을 경우- 잘못 된 연산이 이루어지거나 파일이 깨질 수도 있음
close()를 해야 flushing이 이루어짐- flushing
- 메모리에 있는 값이 디스크에 저장 되는 것
파일 쓰기
- 문자열을 파일 포인터가 위치한 지점에 기록
w모드로 존재하는 파일 오픈 시 데이터 삭제
1 2 3 4
p_fp = open("python.txt", "w") p_fp.write("KNOU\n") p_fp.write("python programming\n") p_fp.close( )

w모드의 특징- 무조건 이름을 새로 생성하고 파일 포인터를 맨 앞에 위치 시킴
- 기존 파일의 내용이 모두 사라질 수 있음
- 실제 경로에 이미 존재하는 파일인지 꼭 확인
데이터 추가
- 파일의 끝에 데이터를 덧붙이는 작업
- 파일 오픈 후 파일 포인터를 EoF로 이동
- open 하자마자 맨 뒤로 이동
- 존재하지 않는 파일은 write와 동일

1 2 3
a_fp = open("python.txt", "a") a_fp.write("\nby CS\n") a_fp.close()
- 파일 오픈 후 파일 포인터를 EoF로 이동
파일 읽고 쓰고 수정하는 프로그램
- ‘Khan.txt’ 파일을 읽고 처리하는 프로그램을 작성하시오.
- 모든 내용을 출력하시오.
- 마지막에 ‘-칭기스 칸-‘을 삽입하시오.
- Lifecycle에 맞추어 파일 생성부터 시작
1 2 3 4 5
khan_fp = open("Khan.txt", "r") print(khan_fp.read(10)) # 10글자를 읽고 출력 print(khan_fp.readline()) # 개행 문자가 있는 곳까지 읽고 출력 khan_fp.close()
-
파일 생성 구문 형식
1
파일 객체_참조 변수 = open(파일_이름, 모드)
-
텍스트 한줄 씩 읽고 출력하기
1 2 3 4 5 6 7 8 9 10 11
khan_fp = open("Khan.txt", "r") # \n으로 한줄 띄우고 print로 한줄 띄워지면서 새로운 줄이 생김 for motto in khan_fp.readlines(): # 텍스트 파일에 있는 모든 라인을 읽음(한줄 씩을 리스트로 읽어내는 명령) print(motto) # 문자열에 있는 개행 문자 삭제 for motto in khan_fp.readlines(): # 텍스트 파일에 있는 모든 라인을 읽음(한줄 씩을 리스트로 읽어내는 명령) print(motto.strip()) # 특정 문자를 제거 khan_fp.close()
-
텍스트 파일 맨 뒤에 새로운 텍스트 삽입
1 2 3 4 5 6
khan_fp = open("Khan.txt", "a") khan_fp.write("\n") khan_fp.write(format("-칭기스 칸-", ">50s")) # 파일 포인터가 이미 맨 뒤에 위치해 있으므로, write 함수를 사용 # 문자열을 50폭, 오른쪽으로 정렬해서 추가 khan_fp.close()
파일의 활용
데이터 분석 프로그램
-
“Hamlet_by_Shakespeare.txt” 파일에 포함된 단어가 출현한 횟수를 출력하는 프로그램을 작성하시오.

- 일렬로 나열 된 연속 된 데이터
- 리스트의 상위 개념 시퀀스
- 일렬로 나열 된 연속 된 데이터
시퀀스의 개념
- 순서 화 된 값의 집합체를 저장할 수 있는 데이터 타입
- 단일 식별자로 연속된 저장 공간 접근 수단 제공
- 개별 원소의 값을 수정, 추가, 삭제 가능
- 원소(element)의 나열을 저장할 수 있는 타입
- 리스트, 세트, 투플, 딕셔너리 등

딕셔너리의 이해
-
키와 값의 쌍(pair)을 저장하는 시퀀스
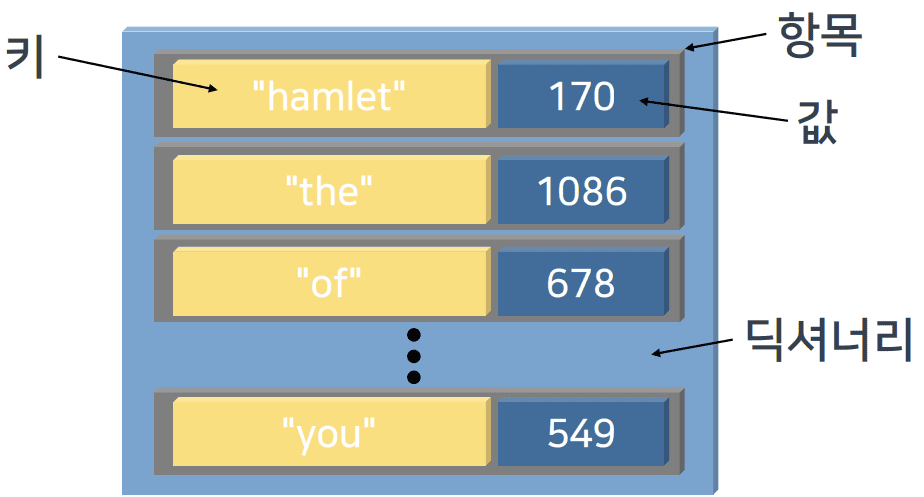
- 단어를 값을 가지고 어떠한 새로운 값들을 찾아갈 수 있음
- 딕셔너리, 시퀀스도 생성, 수정, 삭제 등의 Lifecycle이 존재함
딕셔너리의 생성
-
구문 형식
1
딕셔너리_이름 = {키1:값1, 키2:값2, …, 키n:값n}
- 세트, 리스트, 딕셔너리는 키 불가능
- 키와 값을 : 으로 연결 후 ,로 나열
-
빈 딕셔너리 생성 구문 형식
1 2
딕셔너리_이름 = {} 딕셔너리_이름 = dict()
항목의 추가 및 삭제
-
추가 구문 형식
1
딕셔너리_이름[키] = 값
-
삭제 구문 형식
1
del 딕셔너리_이름[키]
딕셔너리 멤버
| 멤버 | 설명 |
|---|---|
keys(): tuple |
포함된 모든 키를 반환 |
values(): tuple |
포함된 모든 값을 반환 |
items(): tuple |
(키, 값)의 형태의 투플로 모든 항목을 반환 |
clear(): None |
모든 항목을 삭제 |
get(key): value |
키에 해당하는 값을 반환 |
pop(key): value |
키에 해당하는 값을 반환하고 항목을 삭제 |
popitem(): tuple |
무작위로 한 (키, 값)을 반환하고 선택된 항목을 삭제 |
딕셔너리 순회
- 순회(traversal)
- 각각의 항목을 순서대로 한 번씩만 방문하는 과정
-
순회 형식
1 2 3
for key in dictionary : print(key + ":" + str(dictionary[key])) key_사용_블록
데이터 분석 프로그램
-
“Hamlet_by_Shakespeare.txt” 파일에 포함된 단어가 출현한 횟수를 출력하는 프로그램을 작성하시오.

-
텍스트 파일을 열어 데이터 분석(딕셔너리 사용)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
h_fp = open("Hamlet_by_Shakespeare.txt", "r") word_dict = dict() # 빈 딕셔너리 생성 # 각각의 라인을 읽어 내어 word 별로 저장 for line in h_fp.readlines(): # 텍스트를 줄 단위로 읽어냄 # 한 줄에 있는 여러 단어들을 하나 하나씩 끊어 주어야 함 for word in line.strip().split(): # 불 필요한 개행 문자 제거(strip) -> 결과물을 하나씩 분할(split) word = word.strip(" .,;?[]\"\':=!").lower() # 제거할 문자들을 전부 입력 후 소문자로 변환 if word_dict.get(word) is not None: # 정돈 된 word를 word_dict의 key로 가져온 것이 있다면 count = word_dict[word] # 기존 단어의 출현 횟수(value)를 count로 가져오는 작업 else: count = 0 word_dict[word] = count + 1
- 한 단어씩 끊어낸 후
- 불필요한 기호, 공백 등을 제거
- 인용 부호를 나타낼 때에는 “가 아닌 "라고 적어주어야 함
- 대 · 소문자를 모두 구별하는 딕셔너리, 모든 문자를 소문자 또는 대문자로 통일
-
딕셔너리 순회
1 2 3 4
for key in word_dict: print("[" + key + "]", str(word_dict[key]) + "회") # key 값(단어들)과 카운트한 횟수(word_dict[key]) 출력하는 작업 h_fp.close() # 파일 사용하고 난 후에는 꼭 close() 처리해 줄 것
-
데이터 분석 프로그램 개선
-
‘Hamlet_by_Shakespeare.txt’ 파일에 출현 횟수가 100 이상되는 단어와 출력 횟수를 정렬하여 출력하는 프로그램을 작성하시오.

-
딕셔너리 정렬한 후 출력하기
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
h_fp = open("Hamlet_by_Shakespeare.txt", "r") word_dict = dict() # 빈 딕셔너리 생성 # 각각의 라인을 읽어 내어 word 별로 저장 for line in h_fp.readlines(): # 텍스트를 줄 단위로 읽어냄 # 한 줄에 있는 여러 단어들을 하나 하나씩 끊어 주어야 함 for word in line.strip().split(): # 불 필요한 개행 문자 제거(strip) -> 결과물을 하나씩 분할(split) word = word.strip(" .,;?[]\"\':=!").lower() # 제거할 문자들을 전부 입력 후 소문자로 변환 if word_dict.get(word) is not None: # 정돈 된 word를 word_dict의 key로 가져온 것이 있다면 count = word_dict[word] # 기존 단어의 출현 횟수(value)를 count로 가져오는 작업 else: count = 0 word_dict[word] = count + 1 # key와 value를 바꾸어 줄 새로운 딕셔너리 생성 word_r_dict = {v:k for (k, v) in word_dict.items()} # word_dict에서 리스트로 가져온 것들의 key와 value를 뒤바꾸어 새로운 word_r_dict에 넣기 word_dict = {k:v for (v, k) in sorted(word_r_dict.items(), reverse=True)} # word_r_dict에서 가져온 것들을 정렬 후 다시 딕셔너리로 구성 **for key in word_dict: if word_dict[key] >= 100: # 100회 이상 등장하는 단어만 출력 print("[" + key + "]", str(word_dict[key]) + "회") # key 값(단어들)과 카운트한 횟수(word_dict[key]) 출력하는 작업 h_fp.close() # 파일 사용하고 난 후에는 꼭 close() 처리해 줄 것
sorted()- 정렬을 쉽게 해주는 내장 함수
- key 값으로만 정렬이 가능 → key와 value를 교환
reverse=True- 내림차 순으로 정렬하는 sorted 함수의 옵션
-
연습 문제
-
데이터를 구성하는 개별 문자를 인코딩 체계를 통해 바이트로 변경하여 연속적으로 저장한 파일의 종류는?
a. 텍스트 파일
-
시퀀스에서 각각의 항목을 순서대로 한 번씩만 방문하는 과정은?
a. 순회
-
파일 python.txt에 텍스트 데이터를 추가하려고 할 때 빈 칸에 들어가야 할 것은?
1 2 3
a_fp = open("python.txt", _______) a_fp.write("\nby CS\n") a_fp.close()
a.
"a"
학습 정리
- 파일은 컴퓨터에 의해 처리될 또는 처리된 데이터와 정보가 임시적으로 연속된 바이트의 형태로 저장된 상태임
- 파일은 연속된 바이트와 파일의 시작, 파일 포인터, 파일의 끝(EoF)으로 구성 됨
- 파일은 데이터가 저장되는 방식에 따라 텍스트 파일과 바이너리 파일로 구분 됨
- 파이썬은 인터프리터에서 파일의 시작, 파일 포인터, 파일의 끝을 활용하여 데이터 읽기, 쓰기를 위한 함수를 제공 함
- 파일은 파일 객체 생성, 읽기/쓰기/추가하기 작업, 파일 객체 삭제 과정을 통해 처리됨
- 파일의 이름은 파일의 고유 식별자 역할 및 저장 장치 내부에서 파일의 위치를 표현하는 파일 경로를 내포함
- 딕셔너리는 키와 값의 쌍(pair)을 저장하는 시퀀스임