MaxCompute 개요
- Alibaba Cloud의 초대규모 데이터 웨어하우징 서비스
- 구 ODPS(Open Data Processing Service)
- 페타바이트(PB)급 데이터의 오프라인 배치 처리에 특화
- 일반 RDBMS(MySQL 등)와는 근본적으로 다른 아키텍처
아키텍처 및 핵심 특징
설계 목적
- 대용량 데이터 저장 및 배치 처리
- ETL(Extract, Transform, Load) 파이프라인
- 대규모 리포팅 및 분석
- 데이터 마이닝 및 기계학습 전처리
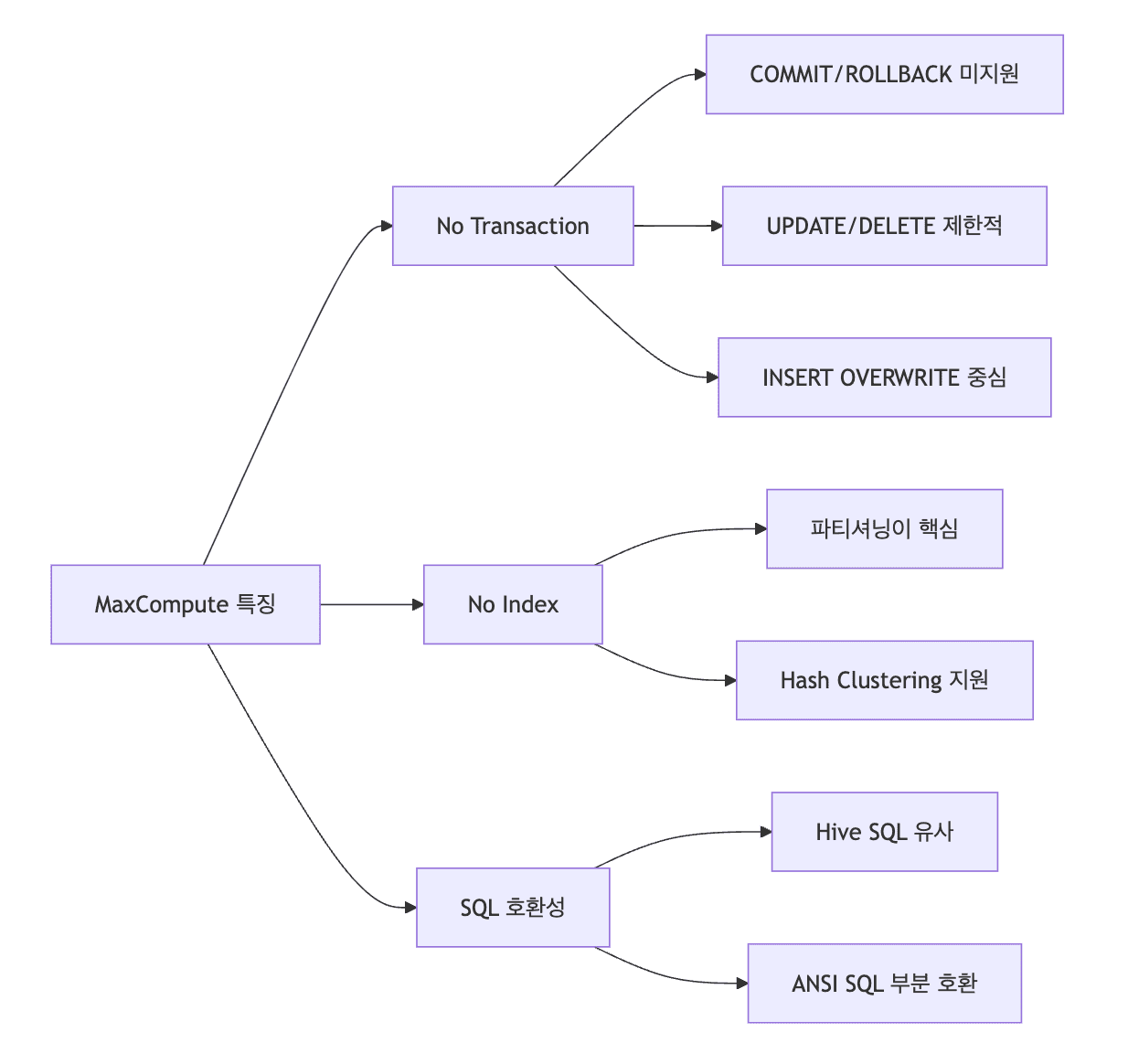
주요 특징
-
No Transaction
COMMIT,ROLLBACK미지원UPDATE,DELETE매우 제한적(운영 환경에서 거의 비사용)- 데이터 수정은
INSERT OVERWRITE로 파티션 단위 덮어쓰기 - 파티션 단위 관리가 기본 운영 방식
-
No Index
- 전통적인 B-Tree 인덱스 없음
- Hash Clustering 등 대안 기능 제공
- 파티셔닝(Partitioning)이 성능 최적화의 핵심
-
SQL 호환성
- Hive SQL과 매우 유사한 문법
- ANSI SQL 표준 부분 지원
- 일부 제약 사항 존재
DDL - 테이블 및 파티션 관리
파티션 테이블 생성
- 파티션이 없는 대규모 테이블 조회 시 비용과 시간 급증
- 날짜, 지역 등 비즈니스 기준으로 파티션 분할 필수
1
2
3
4
5
6
7
8
9
10
CREATE TABLE orders (
order_id BIGINT,
customer_name STRING,
amount DOUBLE
)
PARTITIONED BY (
dt STRING, -- 날짜 파티션
region STRING -- 지역 파티션
)
LIFECYCLE 365; -- 데이터 수명주기 365일 (자동 삭제)
-
파티션 컬럼
- 실제 데이터 컬럼이 아닌 메타데이터
- 폴더 구조처럼 데이터를 물리적으로 분리
- 쿼리 시 스캔 범위 제한하여 성능 향상
-
LIFECYCLE
- 지정 일수 경과 후 자동 삭제
- 스토리지 비용 관리 목적
파티션 추가 및 데이터 로드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
-- 1. 파티션 수동 추가 (데이터 삽입 전 필요할 수 있음)
ALTER TABLE orders
ADD IF NOT EXISTS PARTITION (dt='20240101', region='Seoul');
-- 2. 데이터 덮어쓰기 (가장 많이 사용하는 패턴)
INSERT OVERWRITE TABLE orders
PARTITION (dt='20240101', region='Seoul')
SELECT
order_id,
customer_name,
amount
FROM staging_orders
WHERE order_date = '2024-01-01'
AND city = 'Seoul';
INSERT OVERWRITE- 기존 파티션 데이터 완전 삭제 후 재작성
- 트랜잭션 개념 없이 원자적 교체
- UPDATE의 대안으로 사용
파티션 운영 패턴
| 작업 | 명령어 | 사용 시기 |
|---|---|---|
| 파티션 추가 | ALTER TABLE ... ADD PARTITION |
새 파티션 생성 시 |
| 파티션 삭제 | ALTER TABLE ... DROP PARTITION |
오래된 데이터 정리 |
| 파티션 조회 | SHOW PARTITIONS table_name |
파티션 목록 확인 |
| 데이터 삽입 | INSERT OVERWRITE ... PARTITION |
일배치 데이터 갱신 |
DML 및 쿼리 최적화
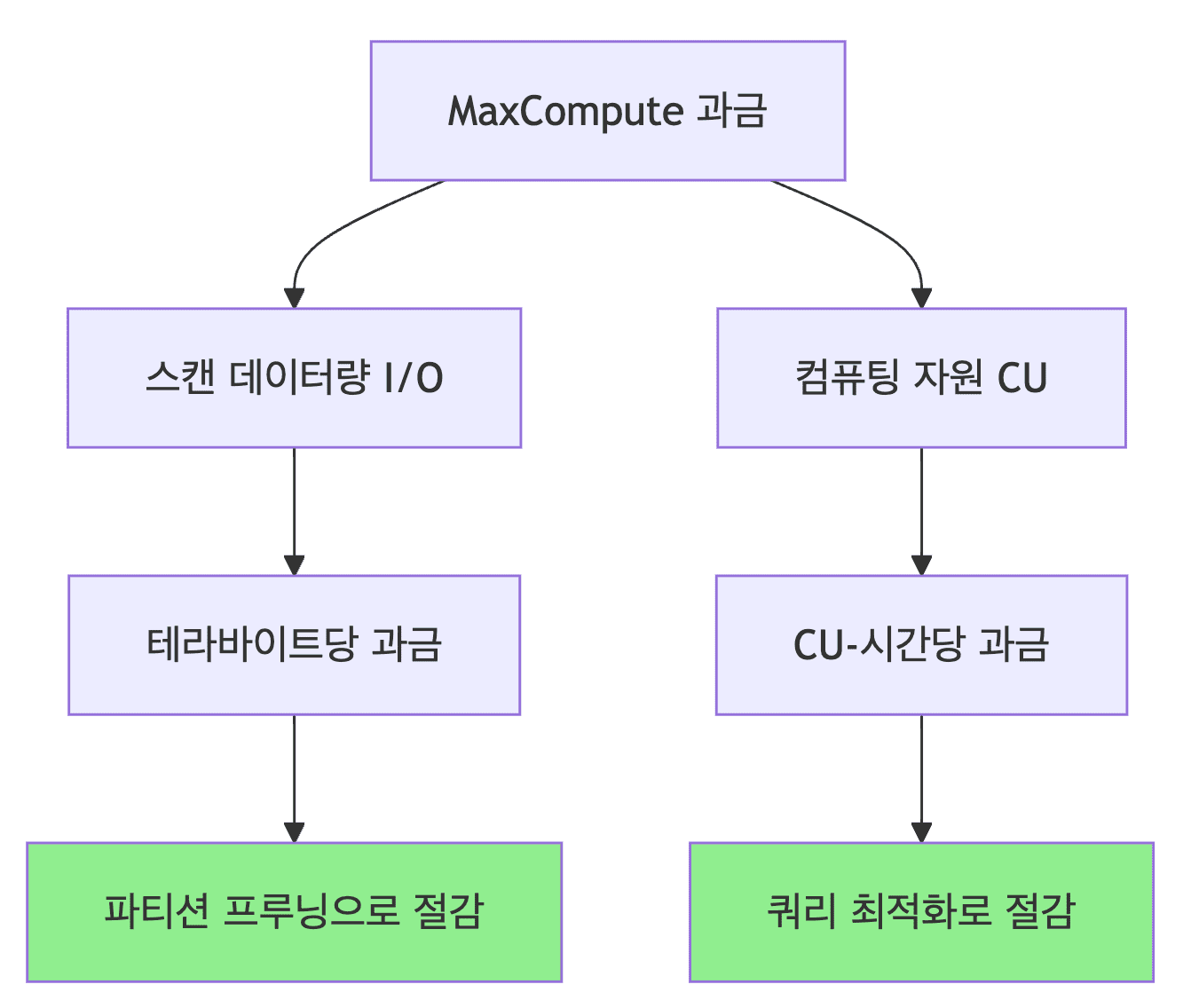
과금 모델 이해
-
스캔한 데이터 양(I/O) 기준 과금
- 파티션 프루닝으로 스캔 범위 최소화
-
컴퓨팅 자원(CU) 사용량 기준 과금
- 쿼리 최적화로 실행 시간 단축
파티션 프루닝 (Partition Pruning)
- 필수 최적화 기법
WHERE절에 파티션 컬럼 명시로 스캔 범위 제한
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
-- Bad: 전체 파티션 스캔 (느리고 비쌈)
SELECT COUNT(*)
FROM orders
WHERE amount > 1000;
-- Good: 특정 파티션만 스캔 (빠르고 저렴)
SELECT COUNT(*)
FROM orders
WHERE dt = '20240101'
AND region = 'Seoul'
AND amount > 1000;
-- Good: 파티션 범위 조회
SELECT COUNT(*)
FROM orders
WHERE dt >= '20240101'
AND dt < '20240108'
AND amount > 1000;
-
파티션 조건 없는 쿼리
- 전체 파티션 스캔
- 비용 폭증 위험 (수십 TB 스캔 가능)
-
파티션 조건 포함 쿼리
- 해당 파티션만 스캔
- 비용 및 시간 대폭 감소
SELECT 컬럼 최소화
- MaxCompute는 컬럼 기반 저장소(Columnar Storage)
- 필요한 컬럼만 선택하여 I/O 최소화
1
2
3
4
5
6
7
8
9
-- Bad: 불필요한 컬럼 모두 스캔
SELECT *
FROM orders
WHERE dt = '20240101';
-- Good: 필요한 컬럼만 선택
SELECT order_id, amount
FROM orders
WHERE dt = '20240101';
| 쿼리 패턴 | 스캔 데이터량 | 비용 |
|---|---|---|
SELECT * (100개 컬럼) |
전체 컬럼 | 높음 |
SELECT col1, col2 (2개 컬럼) |
2개 컬럼만 | 낮음 |
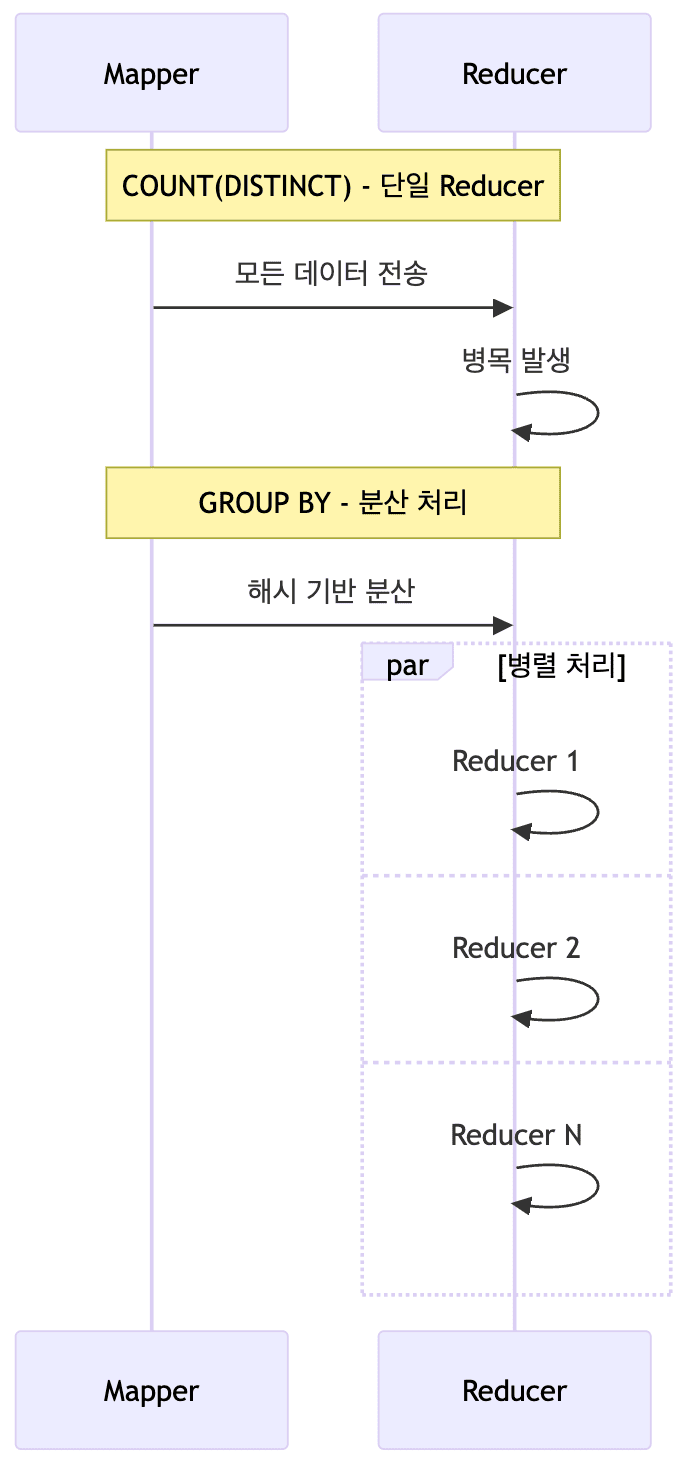
DISTINCT 대신 GROUP BY 사용
-
COUNT(DISTINCT col)의 문제점- 단일 리듀서(Reducer)에 데이터 집중
- 대용량 데이터 처리 시 병목 현상
-
GROUP BY의 장점- 분산 처리로 부하 분산
- 성능 향상
1
2
3
4
5
6
7
8
9
10
11
12
13
-- Bad: 데이터 몰림 현상 가능
SELECT COUNT(DISTINCT user_id)
FROM logs
WHERE dt = '20240101';
-- Good: 분산 처리
SELECT COUNT(*)
FROM (
SELECT user_id
FROM logs
WHERE dt = '20240101'
GROUP BY user_id
) t;
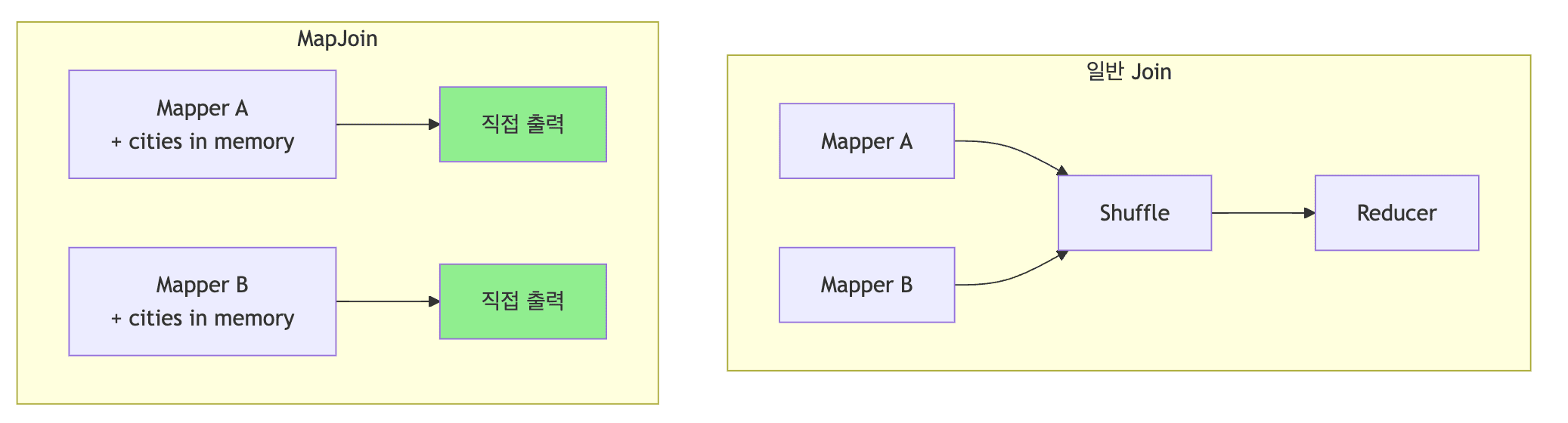
MapJoin 활용
- 작은 테이블과 큰 테이블 조인 시 최적화
- 작은 테이블을 메모리에 로드하여 셔플링 제거
1
2
3
4
5
6
7
SELECT /*+ MAPJOIN(b) */
a.order_id,
b.city_name
FROM orders a
JOIN cities b
ON a.city_id = b.id
WHERE a.dt = '20240101';
-
동작 원리
cities테이블(작은 테이블)을 각 Mapper 메모리에 복제- Shuffle 단계 없이 Map 단계에서 조인 완료
- 네트워크 I/O 대폭 감소
-
사용 조건
- 조인 대상 중 하나가 충분히 작아야 함(보통 수백 MB 이하)
- 주의: 메모리 제한 초과 시 OOM 발생 또는 일반 Join(Shuffle)으로 전환되어 심각한 성능 저하 발생
- 메모리 부족 시 오히려 성능 저하
쿼리 최적화 체크리스트
| 항목 | Bad Practice | 권장 사항 |
|---|---|---|
| 파티션 필터 | WHERE 절에 파티션 없음 | WHERE dt = ‘20240101’ |
| 컬럼 선택 | SELECT * | SELECT col1, col2 |
| 집계 | COUNT(DISTINCT col) | GROUP BY 후 COUNT(*) |
| 조인 | 큰 테이블끼리 조인 | 작은 테이블에 MAPJOIN 힌트 |
| LIMIT | LIMIT 없이 대량 조회 | LIMIT으로 결과 제한 |
고급 기능
UDF (사용자 정의 함수)
- SQL로 해결하기 어려운 복잡한 로직 구현
- JSON 파싱
- 암호화/복호화
- 정규식 고급 처리
- 사용자 정의 집계 함수
UDF 개발 및 등록 프로세스
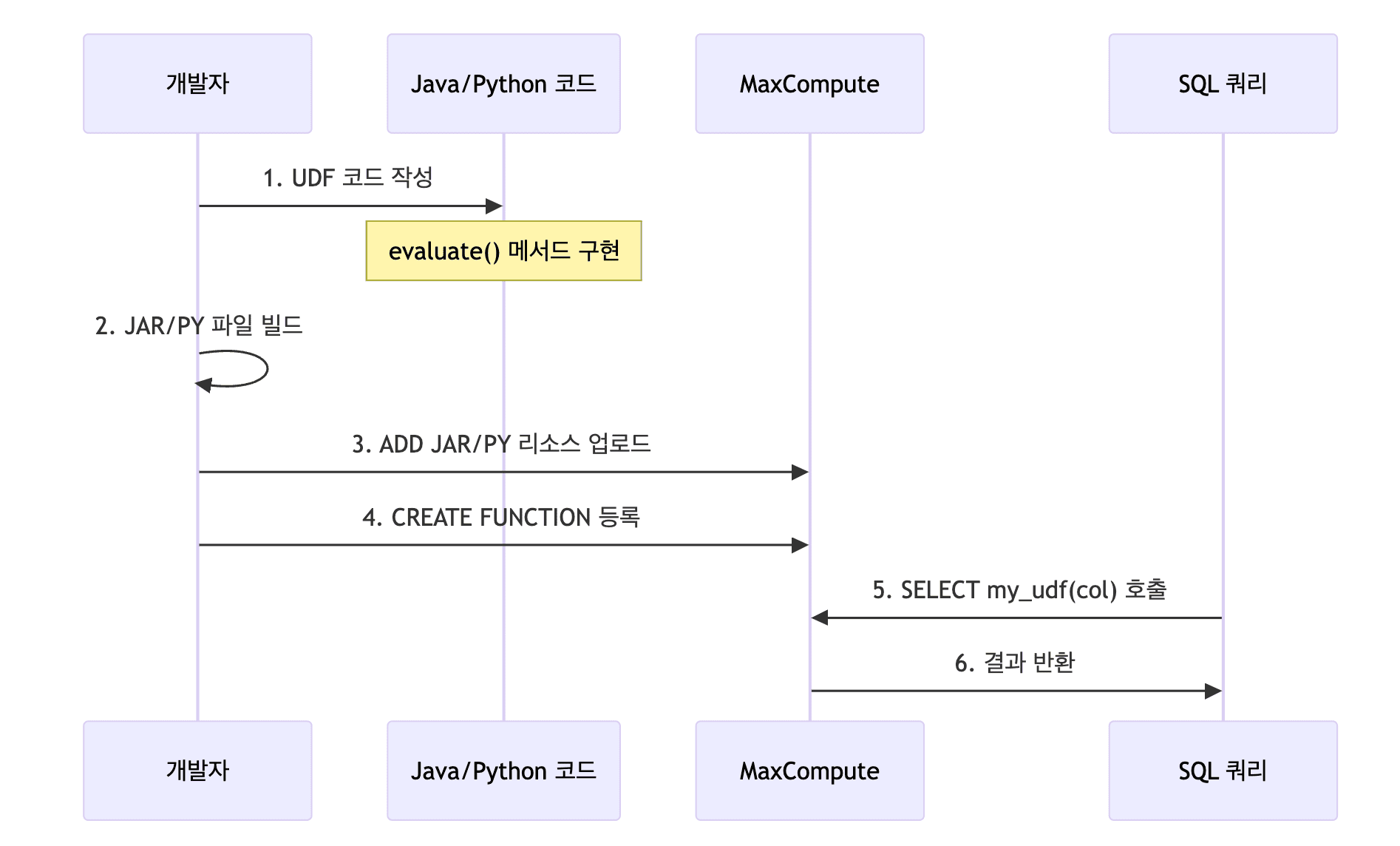
Java UDF 예시
1
2
3
4
5
6
7
8
9
10
package com.example;
import com.aliyun.odps.udf.UDF;
public final class Lower extends UDF {
public String evaluate(String s) {
if (s == null) return null;
return s.toLowerCase();
}
}
UDF 등록 및 사용
1
2
3
4
5
6
7
8
9
10
11
12
-- 1. 리소스 업로드
ADD JAR my_udf.jar;
-- 2. 함수 등록
CREATE FUNCTION my_lower
AS 'com.example.Lower' -- 반드시 패키지명을 포함한 Full Class Name 사용
USING 'my_udf.jar';
-- 3. SQL에서 사용
SELECT my_lower(customer_name)
FROM orders
WHERE dt = '20240101';
Script Mode (스크립트 모드)
- 복잡한 로직을 프로시저처럼 작성
- 변수 선언 및 재사용 가능
- 여러 쿼리의 결과를 중간 변수에 저장
Script Mode 활성화
- SQL 클라이언트(DataWorks 등)에서 ‘Script Mode’ 옵션 활성화 필요
- 또는 쿼리 맨 앞에 파라미터 설정:
set odps.sql.submit.mode=script; - 참고: 단순 Multi-statement(세미콜론으로 구분된 여러 쿼리)와 달리, Script Mode는 컴파일러 단계에서 최적화 수행
Script Mode 예시
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
-- Script Mode 활성화 필요
@data :=
SELECT *
FROM orders
WHERE dt = '20240101';
@filtered :=
SELECT order_id, amount
FROM @data
WHERE amount > 100;
@aggregated :=
SELECT
region,
COUNT(*) as order_count,
SUM(amount) as total_amount
FROM @data
GROUP BY region;
-- 최종 결과 저장
INSERT OVERWRITE TABLE high_value_orders
PARTITION (dt='20240101')
SELECT * FROM @filtered;
INSERT OVERWRITE TABLE regional_summary
PARTITION (dt='20240101')
SELECT * FROM @aggregated;
- 장점
- 중복 쿼리 제거
- 가독성 향상
- 복잡한 ETL 로직 구현 용이
MaxCompute 운영 권장 사항
테이블 설계
| 원칙 | 설명 | 예시 |
|---|---|---|
| 파티션 필수 | 모든 대용량 테이블에 파티션 적용 | PARTITIONED BY (dt STRING) |
| 적절한 파티션 키 | 쿼리 패턴에 맞는 파티션 선택 | 날짜별 집계 → dt 파티션 |
| 파티션 수 제한 | 과도한 파티션은 메타데이터 부하 증가 | 시간 파티션 지양 (날짜로 통합) |
| LIFECYCLE 설정 | 불필요한 데이터 자동 삭제 | LIFECYCLE 365 |
쿼리 작성
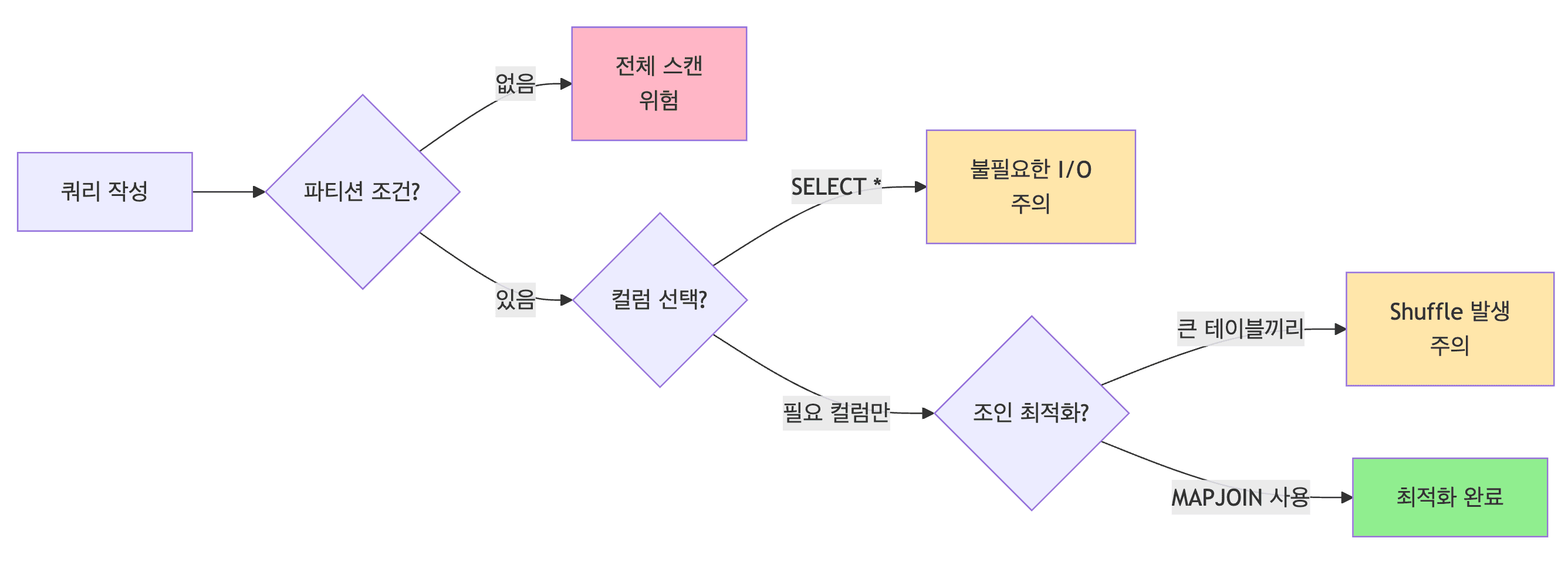
- 필수 체크 사항
- 파티션 조건 포함 여부
- 최소한의 컬럼만 선택
- 적절한 조인 힌트 사용
LIMIT활용하여 결과 제한
비용 관리
-
개발 단계
- 소량 파티션으로 테스트
LIMIT필수 사용- 프로덕션 실행 전 비용 예측 도구 활용
-
운영 단계
- 불필요한 파티션 정기 삭제
- 중복 쿼리 통합
- 쿼리 실행 이력 모니터링
일반적인 실수와 해결
| 실수 | 문제점 | 해결 방법 |
|---|---|---|
| 파티션 조건 누락 | 전체 스캔으로 비용 폭증 | WHERE절에 dt 필수 포함 |
| SELECT * | 불필요한 컬럼까지 스캔 | 필요 컬럼만 명시 |
| LIMIT 미사용 | 수백만 건 결과 반환 | 개발 시 LIMIT 100 등 사용 |
| 과도한 DISTINCT | 단일 Reducer 병목 | GROUP BY로 대체 |
| 큰 테이블 조인 | 네트워크 Shuffle 과다 | 작은 테이블에 MAPJOIN 힌트 |
실전 예제
일별 배치 ETL 패턴
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
-- 1. Staging 테이블에서 데이터 정제
@cleaned_data :=
SELECT
user_id,
product_id,
order_amount,
order_date
FROM staging_orders
WHERE ds = '${bizdate}'
AND order_status = 'confirmed'
AND order_amount > 0;
-- 2. 사용자별 집계
@user_summary :=
SELECT
user_id,
COUNT(*) as order_count,
SUM(order_amount) as total_amount,
AVG(order_amount) as avg_amount
FROM @cleaned_data
GROUP BY user_id;
-- 3. 결과를 운영 테이블에 저장
INSERT OVERWRITE TABLE user_daily_summary
PARTITION (dt='${bizdate}')
SELECT * FROM @user_summary;
-- 4. 이상치 감지 (옵션)
INSERT OVERWRITE TABLE anomaly_alerts
PARTITION (dt='${bizdate}')
SELECT
user_id,
total_amount,
'high_value' as alert_type
FROM @user_summary
WHERE total_amount > 10000;
복잡한 조인 쿼리 최적화
1
2
3
4
5
6
7
8
9
10
11
12
13
-- 작은 테이블(차원 테이블)에 MAPJOIN 적용
SELECT /*+ MAPJOIN(dim_user, dim_product) */
f.order_id,
u.user_name,
p.product_name,
f.amount
FROM fact_orders f
JOIN dim_user u
ON f.user_id = u.user_id
JOIN dim_product p
ON f.product_id = p.product_id
WHERE f.dt = '20240101'
AND f.amount > 100;
요약
MaxCompute 핵심 원칙
-
파티션이 모든 것
- 테이블 생성 시 파티션 키 설계 필수
- 쿼리 시 WHERE 절에 파티션 조건 필수
- 파티션 없는 대용량 테이블은 재앙
-
INSERT OVERWRITE 사고방식
- UPDATE/DELETE 사용 금지
- 파티션 전체를 갈아끼우는 방식으로 운영
- 멱등성(Idempotency) 보장
-
MapJoin 활용
- 작은 테이블 조인 시 성능 극대화
- Shuffle 제거로 실행 시간 단축
-
비용 경각심
SELECT *한 번에 수만~수십만 원 과금 가능LIMIT과 파티션 조건을 습관화- 개발 환경에서 충분한 테스트 후 프로덕션 실행
학습 로드맵
