RAID 개요
RAID란
- Redundant Array of Independent Disks의 약자
- 여러 개의 디스크를 조합하여 성능과 안정성을 동시에 확보하는 기술
- 2개 이상의 디스크를 병렬로 처리하여 성능 및 안정성 향상
- 디스크 오류나 데이터 손실 등 장애에 대비하기 위한 복수 디스크 구성 방식
RAID의 핵심 목적
- 성능 향상
- 데이터를 여러 디스크에 분산하여 병렬 I/O
- 읽기/쓰기 속도 증가
- 안정성 향상
- 데이터 중복 저장 또는 패리티 사용
- 디스크 장애 시 데이터 복구 가능
- 가용성 향상
- 디스크 장애 발생 시에도 서비스 지속
- 무중단 운영 가능
기본 문제와 해결책
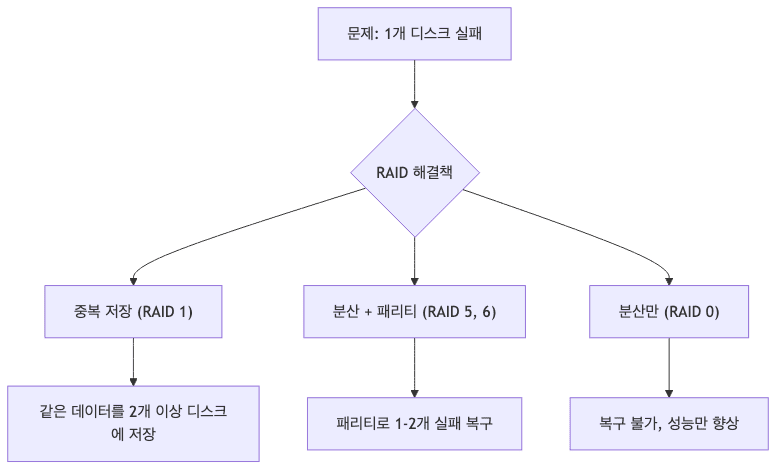
RAID 레벨 비교
주요 RAID 레벨 개요
| RAID | 최소 디스크 | 용량 효율 | 내결함성 | 성능 | 주요 용도 |
|---|---|---|---|---|---|
| RAID 0 | 2개 | 100% | 없음 | 매우 빠름 | 캐시, 임시 데이터 |
| RAID 1 | 2개 | 50% | 1개 실패 | 중간 | 시스템 드라이브 |
| RAID 5 | 3개 | n-1 (67% for 3) | 1개 실패 | 중간 | 일반 서버 (가장 일반적) |
| RAID 6 | 4개 | n-2 (50% for 4) | 2개 실패 | 느림 | 대용량 저장소 |
| RAID 10 | 4개 | 50% | 1개/쌍 실패 | 빠름 | 고성능 DB |
용량 계산 예시
- RAID 0
- 100GB + 100GB = 200GB (100%)
- RAID 1
- 100GB + 100GB = 100GB (50%)
- RAID 5
- 100GB + 100GB + 100GB = 200GB (67%)
- n개 디스크 = (n-1) × 용량
- RAID 6
- 100GB + 100GB + 100GB + 100GB = 200GB (50%)
- n개 디스크 = (n-2) × 용량
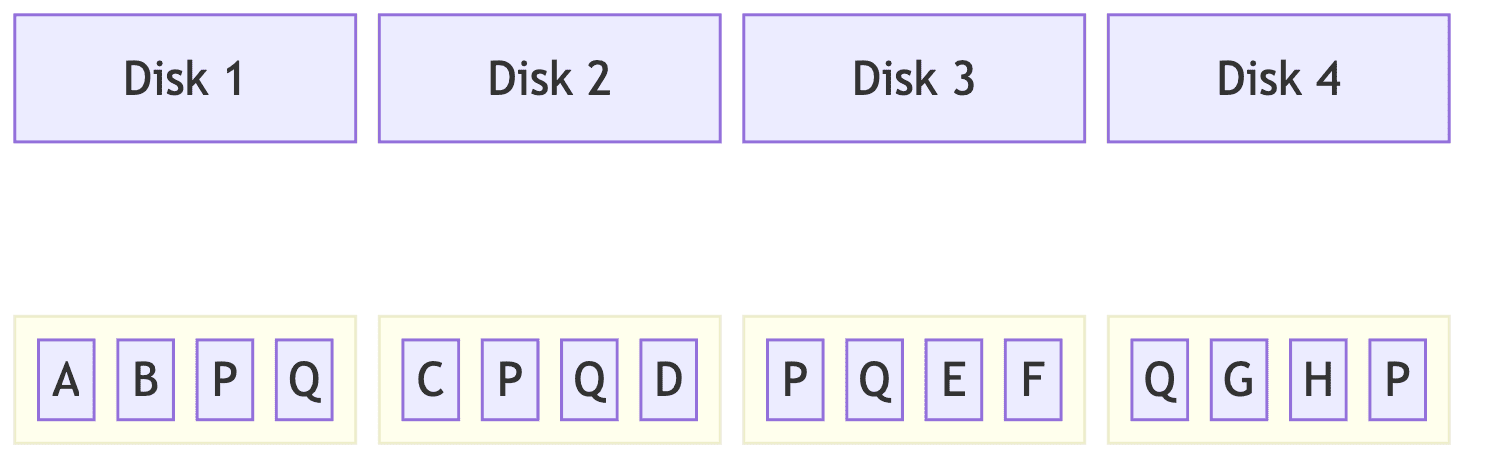
RAID 0 (Striping)
개념
- 데이터를 여러 디스크에 분산 저장하여 성능 향상
- 패리티(오류 검출 기능) 없는 순수 분산 처리
- 가장 빠르지만 가장 위험
데이터 저장 방식
1
2
3
4
5
6
7
데이터: ABCDEF
Disk 1: A_C_E_
Disk 2: _B_D_F
읽기: Disk 1과 Disk 2 동시 읽기 → 2배 속도
쓰기: Disk 1과 Disk 2 동시 쓰기 → 2배 속도
장단점
- 장점
- 처리 속도 매우 빠름
- 디스크 용량 100% 활용
- 구현 단순
- 단점
- 한 디스크 실패 시 전체 데이터 손실
- 복구 불가능
- 안정성 매우 낮음
- 권장 용도
- 임시 데이터 저장소
- 캐시 디렉토리
- 비디오 편집 스크래치 디스크
- 언제든 재생성 가능한 데이터
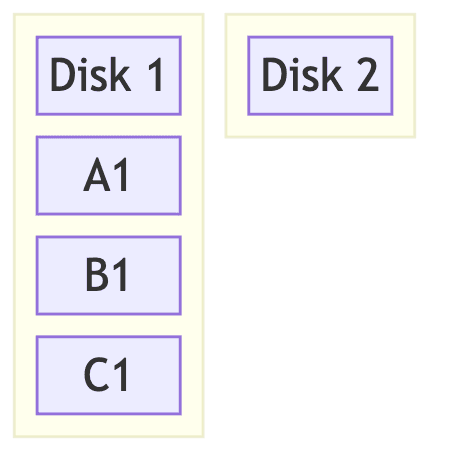
RAID 1 (Mirroring)
개념
- 데이터를 모든 디스크에 완전 복제
- 동일한 데이터를 여러 디스크에 중복 저장
- 가장 안전하지만 용량 효율 낮음
데이터 저장 방식
1
2
3
4
5
6
7
데이터: ABCDEF
Disk 1: ABCDEF (원본)
Disk 2: ABCDEF (거울상)
Disk 1 실패 → Disk 2에서 100% 복구 가능
Disk 2 실패 → Disk 1에서 100% 복구 가능
장단점
- 장점
- 디스크 장애 시 즉시 복구 가능
- 가용성 및 안정성 매우 높음
- 읽기 성능 향상 가능 (양쪽에서 읽기)
- 단점
- 용량 50%만 사용 가능 (2개 디스크 = 1개 용량)
- 비용 대비 용량 효율 낮음
- 권장 용도
- 시스템 드라이브 (OS 파티션)
- 중요 데이터베이스
- 복구 시간이 중요한 서비스
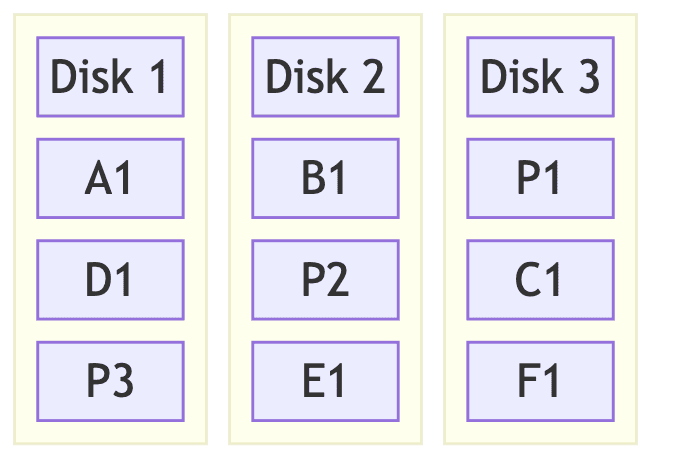
RAID 5 (Striping + Parity)
개념
- 데이터 분산 저장 + 패리티를 각 디스크에 분산
- 가장 일반적으로 사용되는 RAID 레벨
- 성능과 안정성의 균형
데이터 저장 방식
1
2
3
4
5
6
7
데이터 패리티
Disk 1: A D G P1
Disk 2: B E P2 H
Disk 3: C P3 F I
패리티 분산: 병목 현상 방지
패리티 계산: XOR 연산 (A ⊕ B ⊕ C = P)
패리티 복구 메커니즘
1
2
3
4
5
6
7
8
9
정상 상태:
A = 1010
B = 1100
C = 0101
P = A ⊕ B ⊕ C = 0011
Disk 2 (B) 실패 시:
B = A ⊕ P ⊕ C
B = 1010 ⊕ 0011 ⊕ 0101 = 1100 (복구!)
XOR 패리티 상세 예시
- XOR (Exclusive OR) 논리
- A ⊕ B ⊕ C = P (패리티)
- 만약 B 디스크 실패 시
- A ⊕ P ⊕ C = B (복구)
- 실제 계산 예시
- Data Block 1 (A)
- 1010
- Data Block 2 (B)
- 1100
- Data Block 3 (C)
- 0101
- Parity
- A ⊕ B ⊕ C = 0011
- Data Block 1 (A)
- B 디스크 실패 시 복구
- A ⊕ P ⊕ C = 1010 ⊕ 0011 ⊕ 0101 = 1100 (원래 B 복구)
장단점
- 장점
- 1개 디스크 실패 복구 가능
- 용량 효율 좋음 (3개 디스크 = 2개 용량)
- 읽기 성능 우수
- RAID 3, 4 대비 병목 현상 감소
- 단점
- 쓰기 성능 저하 (Write Penalty)
- 패리티 계산 오버헤드
- 1개 실패 후 추가 실패 시 전체 손실
- 리빌드 중 부하 높음
- 권장 용도
- 일반 파일 서버
- 웹 서버 스토리지
- 백업 서버
- 읽기 중심 애플리케이션
RAID 6 (Dual Parity)
개념
- RAID 5 + 추가 패리티
- 2개 디스크 동시 실패까지 복구 가능
- 대용량 디스크 환경에 필수
데이터 저장 방식
1
2
3
4
5
6
7
8
9
Disk 1: A E P1 P2
Disk 2: B P1 F I
Disk 3: C P2 G J
Disk 4: P1 D H K
P1, P2 = 2개의 독립적인 패리티
Disk 1 + Disk 2 동시 실패
→ Disk 3, 4의 패리티로 복구 가능
장단점
- 장점
- 2개 디스크 동시 실패 복구 가능
- 대용량 디스크에서 안전성 높음
- 리빌드 중 추가 실패에도 안전
- 단점
- 용량 효율 낮음 (n-2개 용량)
- 쓰기 성능 RAID 5보다 낮음
- 패리티 계산 복잡
- 최소 4개 디스크 필요
- 권장 용도
- 10TB 이상 대용량 디스크
- 장기 아카이브 스토리지
- 리빌드 시간이 긴 환경
- 높은 안정성 요구 시스템
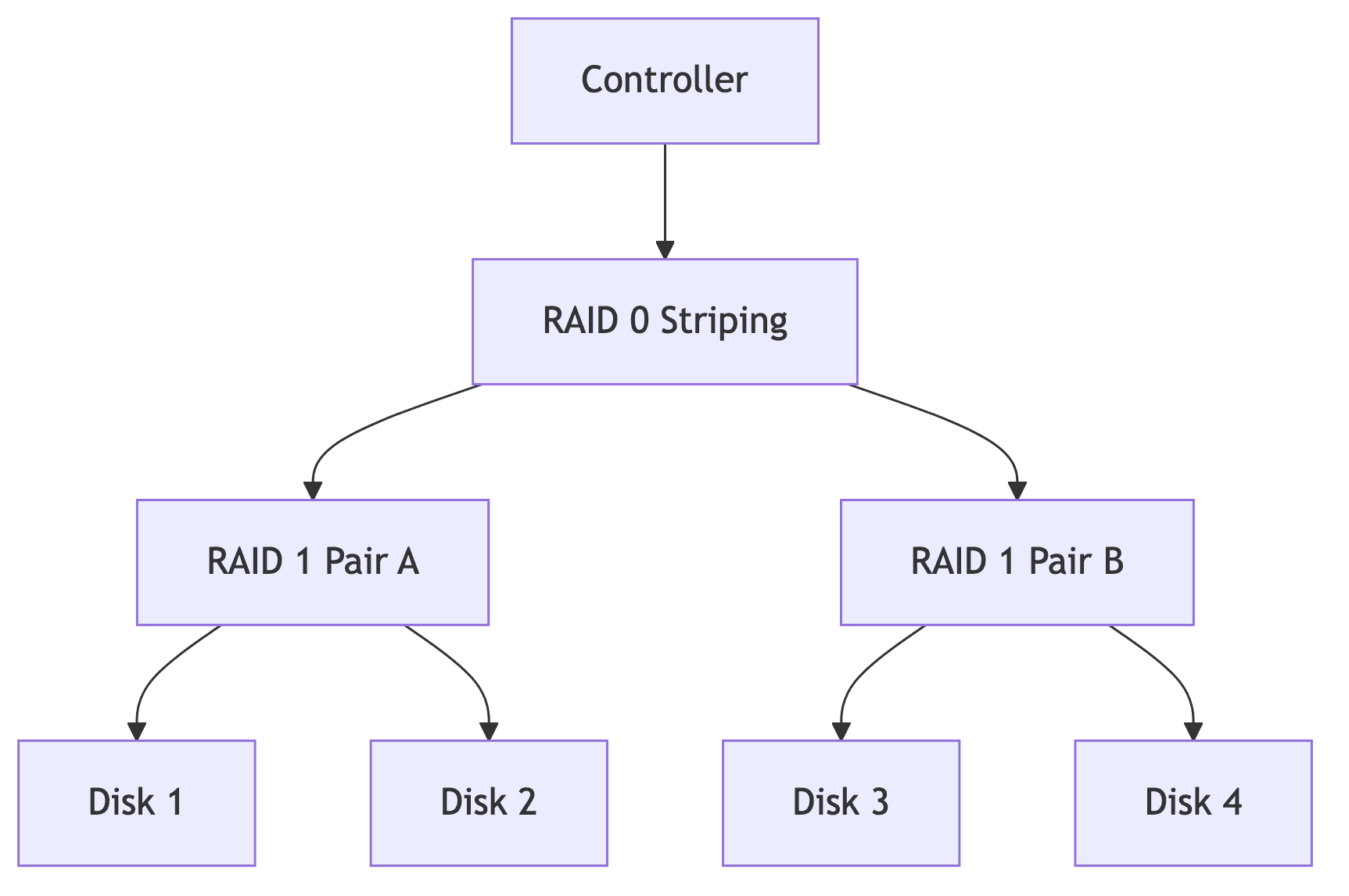
RAID 10 (1+0)
개념
- RAID 1 (미러링) 쌍들을 RAID 0 (스트라이핑)으로 연결
- 성능과 안정성 동시 확보
- 고성능 데이터베이스에 최적
구성 방식
장단점
- 장점
- RAID 5보다 쓰기 성능 우수
- 각 쌍에서 1개씩 실패 복구 가능
- 리빌드 빠름 (미러만 복사)
- 단점
- 용량 50%만 사용 (4개 디스크 = 2개 용량)
- 비용 높음
- 권장 용도
- 고성능 데이터베이스 (MySQL, PostgreSQL)
- OLTP 시스템
- 쓰기 성능이 중요한 애플리케이션
RAID 2, 3, 4 (레거시)
RAID 2
- 데이터 분산 + 해밍 코드(Hamming Code) 사용
- ECC(Error Correction Code)를 별도 드라이브에 저장
- 최소 3개 디스크 필요

- 단점
- 효율성 매우 낮음
- 현대에는 사용하지 않음
RAID 3
- RAID 0 + 패리티 전용 디스크
- Byte 단위로 데이터 저장
- 패리티 정보를 별도 디스크에 저장
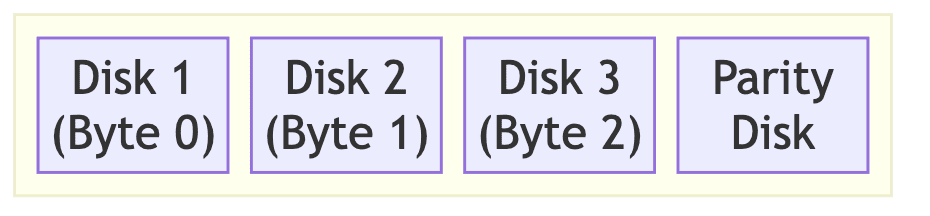
- 단점
- 패리티 디스크 병목 현상
- 패리티 디스크 손실 시 복구 어려움
RAID 4
- RAID 0 + 패리티 전용 디스크
- Block 단위로 데이터 저장
- RAID 3의 Block 버전

- 단점
- 패리티 디스크 병목 현상
- RAID 5로 대체됨
RAID 0+1 vs 1+0 비교
RAID 0+1 (01)
- RAID 0으로 구성 후 → RAID 1로 미러링
- 4개 디스크 = 2개 용량
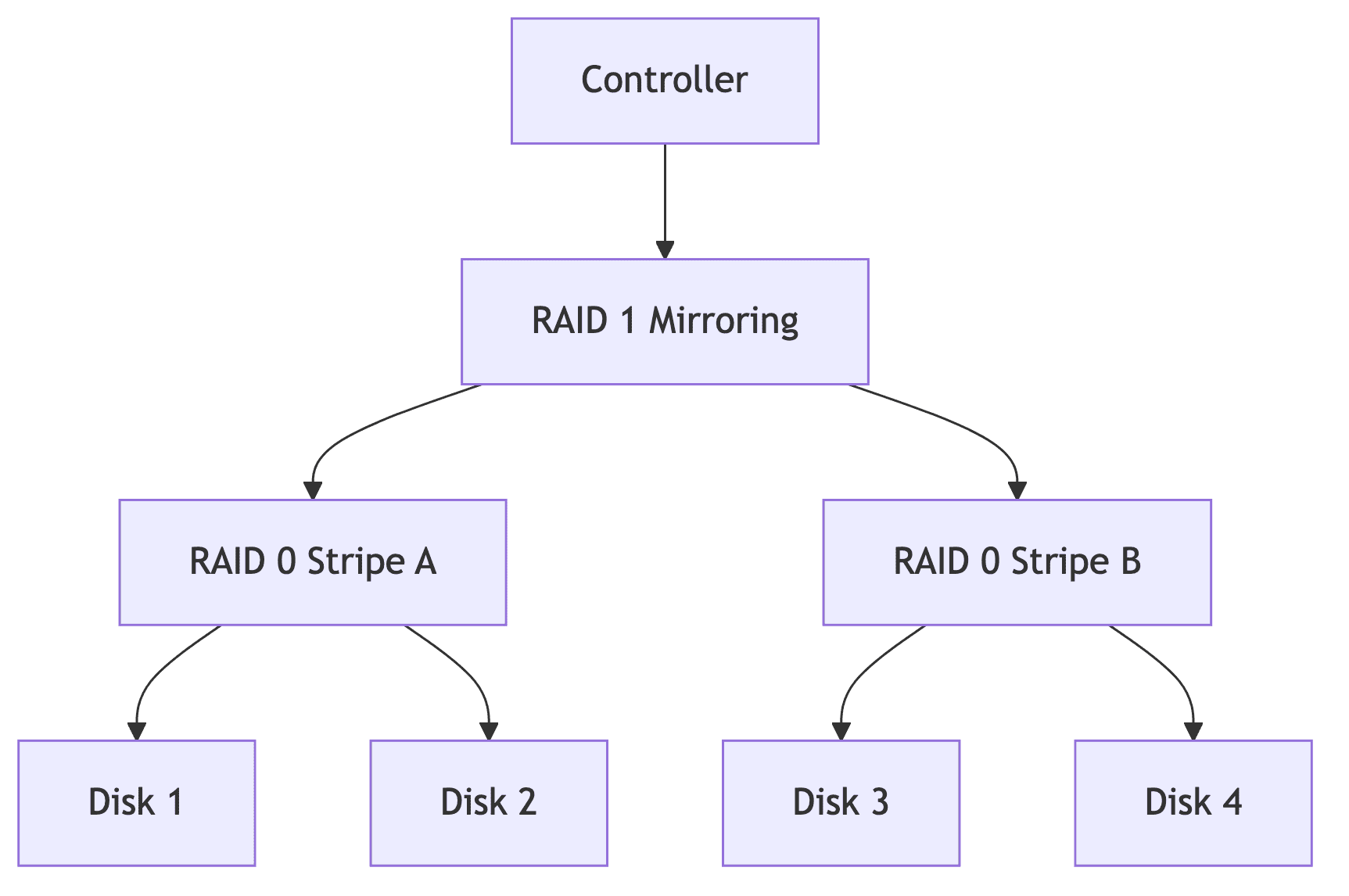
- 문제점
- 1개 디스크 실패 시 전체 스트라이프 세트 무효화
- 6개 디스크 구성 시 비효율적
RAID 1+0 (10)
- RAID 1로 미러링 후 → RAID 0으로 스트라이핑
- 4개 디스크 = 2개 용량
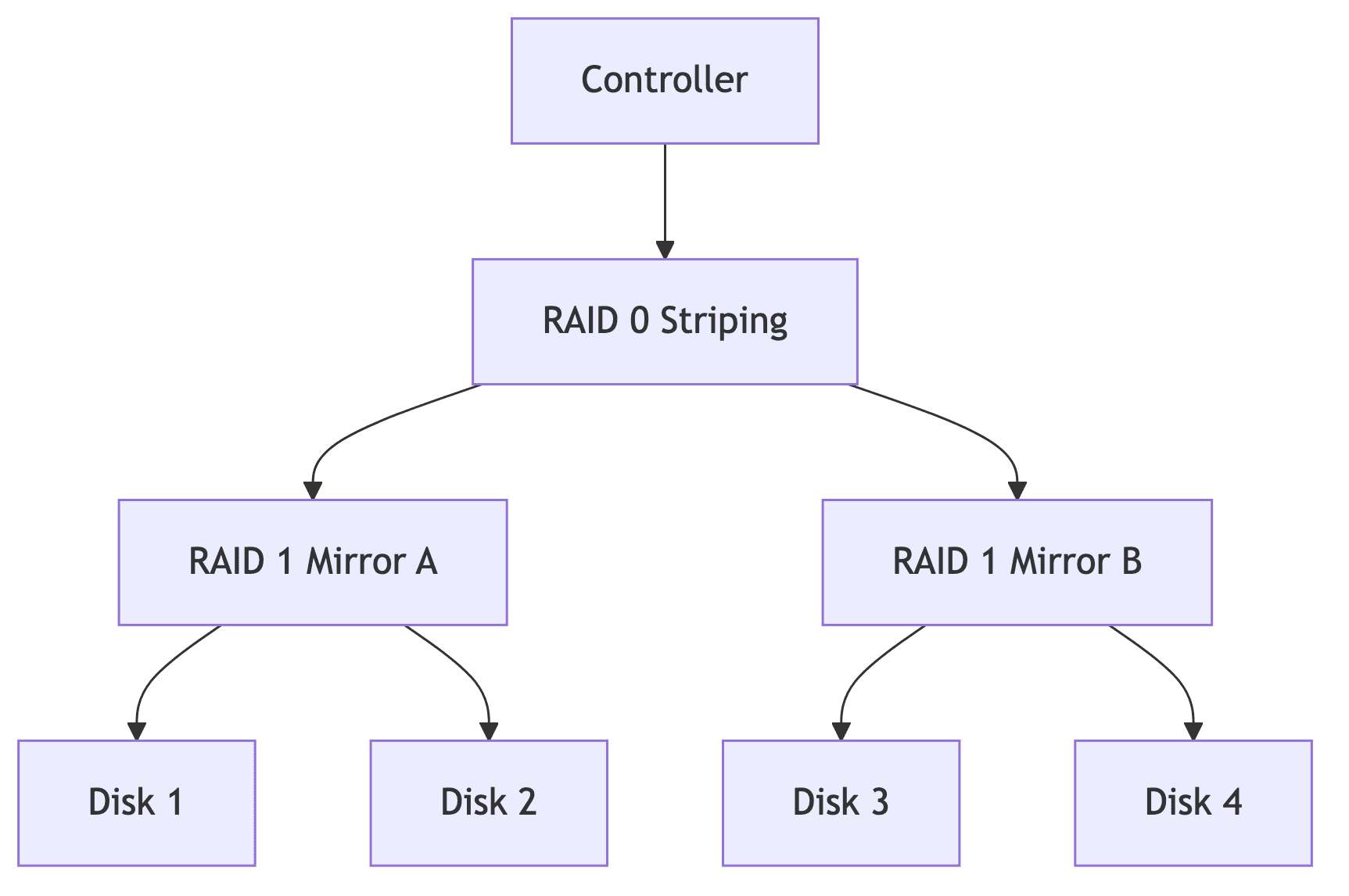
- 장점
- 각 미러 쌍에서 1개씩 실패 가능
- RAID 0+1보다 안전
- 결론
- RAID 10이 RAID 0+1보다 우수
- 운영 환경에서는 RAID 10 사용
mdadm 명령어
mdadm 개요
- Multi Device ADMin의 약자
- Linux에서 소프트웨어 RAID 관리 도구
- RAID 생성, 모니터링, 복구 등 모든 작업 수행
RAID 생성
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# RAID 0 생성 (Striping)
sudo mdadm --create --verbose /dev/md0 --level=0 --raid-devices=2 /dev/sda /dev/sdb
# RAID 1 생성 (Mirroring)
sudo mdadm --create --verbose /dev/md0 --level=1 --raid-devices=2 /dev/sda /dev/sdb
# RAID 5 생성 (3개 이상)
sudo mdadm --create --verbose /dev/md0 --level=5 --raid-devices=3 /dev/sda /dev/sdb /dev/sdc
# RAID 6 생성 (4개 이상)
sudo mdadm --create --verbose /dev/md0 --level=6 --raid-devices=4 /dev/sda /dev/sdb /dev/sdc /dev/sdd
# RAID 10 생성
sudo mdadm --create --verbose /dev/md0 --level=10 --raid-devices=4 /dev/sda /dev/sdb /dev/sdc /dev/sdd
# 옵션 단축형
# RAID 5 생성 (3개 활성 + 1개 Hot Spare)
# 파티션 사용 권장 (예: /dev/sd[a-d]1)
sudo mdadm -C /dev/md0 -l 5 -n 3 -x 1 /dev/sd[a-d]1
# 옵션 설명:
# -n 3: 활성 디스크 3개
# -x 1: 예비(Spare) 디스크 1개 (장애 시 자동 투입)
RAID 상태 확인
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 상세 상태 확인
sudo mdadm --detail /dev/md0
sudo mdadm -D /dev/md0 # 단축형
# 빠른 상태 확인
cat /proc/mdstat
# 모든 RAID 배열 스캔
sudo mdadm --detail --scan
sudo mdadm -D -s
# 실시간 모니터링
watch -n 1 'cat /proc/mdstat'
# 백그라운드 모니터링
sudo mdadm --monitor --scan --daemonize
디스크 관리
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 디스크 추가
sudo mdadm --add /dev/md0 /dev/sdd
sudo mdadm /dev/md0 -a /dev/sdd # 단축형
# 디스크 실패 마킹
sudo mdadm --fail /dev/md0 /dev/sdd
sudo mdadm /dev/md0 -f /dev/sdd # 단축형
# 디스크 제거
sudo mdadm --remove /dev/md0 /dev/sdd
sudo mdadm /dev/md0 -r /dev/sdd # 단축형
# 새 디스크로 교체 (Hot Swap)
sudo mdadm /dev/md0 -f /dev/sdd # 실패 마킹
sudo mdadm /dev/md0 -r /dev/sdd # 제거
sudo mdadm /dev/md0 -a /dev/sde # 새 디스크 추가
RAID 확장 및 축소
1
2
3
4
5
6
7
8
9
# RAID 레벨 변경 (RAID 1 → RAID 5)
sudo mdadm --grow /dev/md0 --level=5 --raid-devices=3
# 디스크 추가 후 확장
sudo mdadm --add /dev/md0 /dev/sdd
sudo mdadm --grow /dev/md0 --raid-devices=4
# 확장 진행 상황 모니터링
watch -n 1 'cat /proc/mdstat'
RAID 중지 및 삭제
1
2
3
4
5
6
7
8
9
10
11
12
13
# 마운트 해제
sudo umount /raid
# RAID 중지
sudo mdadm --stop /dev/md0
sudo mdadm -S /dev/md0 # 단축형
# RAID 재시작
sudo mdadm --run /dev/md0
# RAID 완전 삭제
sudo mdadm --stop /dev/md0
sudo mdadm --zero-superblock /dev/sda /dev/sdb /dev/sdc
RAID 설정 영구화
/etc/mdadm.conf 설정
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# RAID 설정 저장
sudo mdadm --detail --scan > /etc/mdadm.conf
sudo mdadm -D -s > /etc/mdadm.conf # 단축형
# 특정 RAID만 추가
sudo mdadm -D -s /dev/md0 >> /etc/mdadm.conf
# 설정 확인
cat /etc/mdadm.conf
# 중요: 설정 변경 후 반드시 initramfs 갱신 (부팅 실패 방지)
# RHEL/CentOS
sudo dracut --force
# Ubuntu/Debian
sudo update-initramfs -u
자동 마운트 설정
1
2
3
4
5
6
7
8
9
10
11
12
13
# UUID 확인
sudo blkid /dev/md0
# /etc/fstab 편집
sudo vi /etc/fstab
# 추가 내용
# 추가 내용 (dump=0, fsck=2 권장)
UUID=xxx-yyy-zzz /raid ext4 defaults 0 2
# 테스트
sudo mount -a
df -h
Degraded RAID 복구
Degraded 상태란
- 1개 이상 디스크 실패했으나 데이터는 여전히 접근 가능한 상태
- RAID 5는 1개, RAID 6은 2개까지 실패 허용
- 즉시 조치 필요 (추가 실패 시 전체 손실)
Degraded 상태 확인
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# /proc/mdstat 확인
cat /proc/mdstat
# 출력 예시
md0 : active raid5 sda1[0] sdb1[1] sdc1[2]
1953920 blocks super 1.2 level 5, 64k chunk, algorithm 2 [3/2] [U_U]
↑ [3/2] = 3개 필요, 2개만 작동 중
↑ [U_U] = Up, Down, Up (2번째 디스크 실패)
# mdadm 상세 확인
sudo mdadm --detail /dev/md0
# State: clean, degraded (← 문제 있음)
# State: clean (← 정상)
복구 프로세스
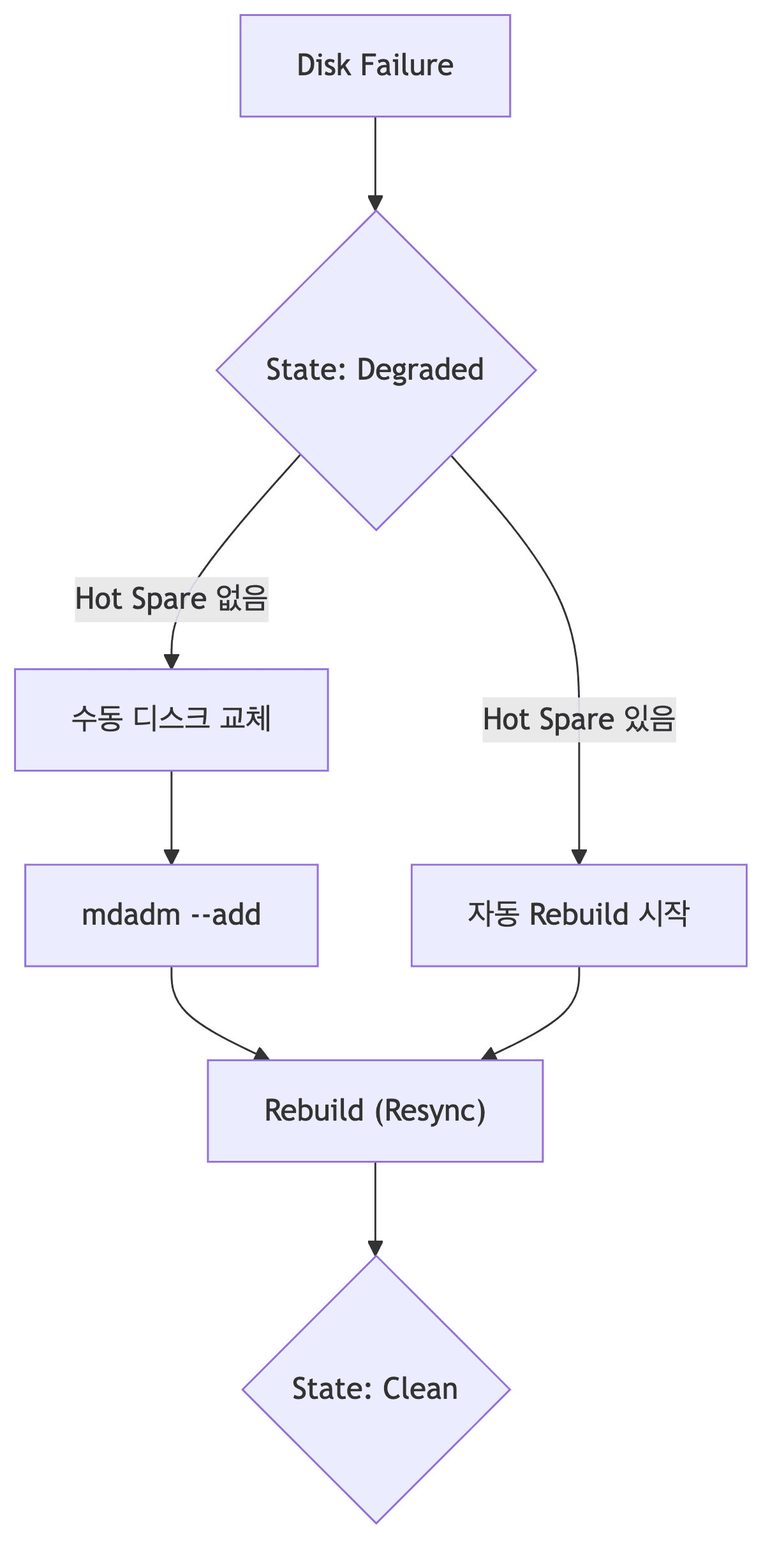
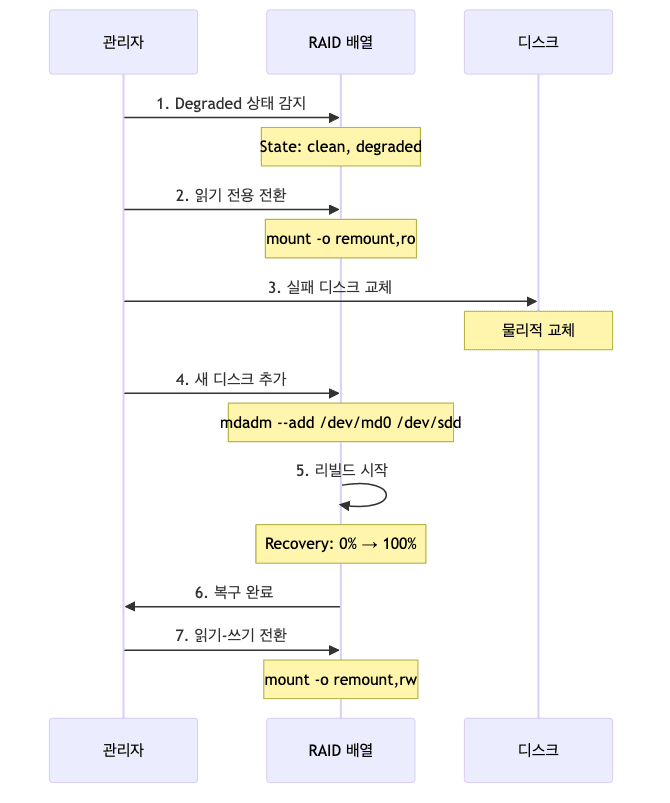
상세 복구 절차
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 1. 즉시: 모든 쓰기 작업 중지
sudo mount -o remount,ro /raid
# 2. 상태 확인
cat /proc/mdstat
sudo mdadm --detail /dev/md0
# 3. 실패 디스크 확인 및 제거
# (이미 실패 마킹된 경우 자동 제거됨)
# 4. 새 디스크로 교체 (물리적으로)
# 5. 새 디스크를 배열에 추가
sudo mdadm --add /dev/md0 /dev/sdd
# 6. 리빌드 진행 상황 모니터링
watch -n 1 'cat /proc/mdstat'
# md0 : active raid5 sda1[0] sdb1[1] sdc1[2] sdd1[3]
# [=>...................] recovery = 5.2% (10240/195392)
# 7. 리빌드 완료 대기 (시간 소요!)
# 100GB당 약 1-2시간 소요 (디스크 속도에 따라 다름)
# 8. 복구 완료 확인
sudo mdadm --detail /dev/md0
# State : clean (정상)
# 9. 읽기-쓰기 재개
sudo mount -o remount,rw /raid
# 10. 정상 작동 확인
df -h
복구 주의사항
- 리빌드 중 주의
- 시스템 부하 높음
- 디스크 I/O 집중
- 추가 디스크 실패 시 전체 손실 위험
- RAID 6 권장
- 대용량 디스크 (10TB+)
- 리빌드 중 2차 실패 대비
- S.M.A.R.T 모니터링
- 정기적인 디스크 상태 점검
- 예측 가능한 실패 사전 탐지
Write Penalty (쓰기 오버헤드)
개념
- RAID 5/6에서 데이터 변경 시 발생하는 추가 I/O
- 패리티 계산 및 업데이트 필요
RAID 5 Write Penalty
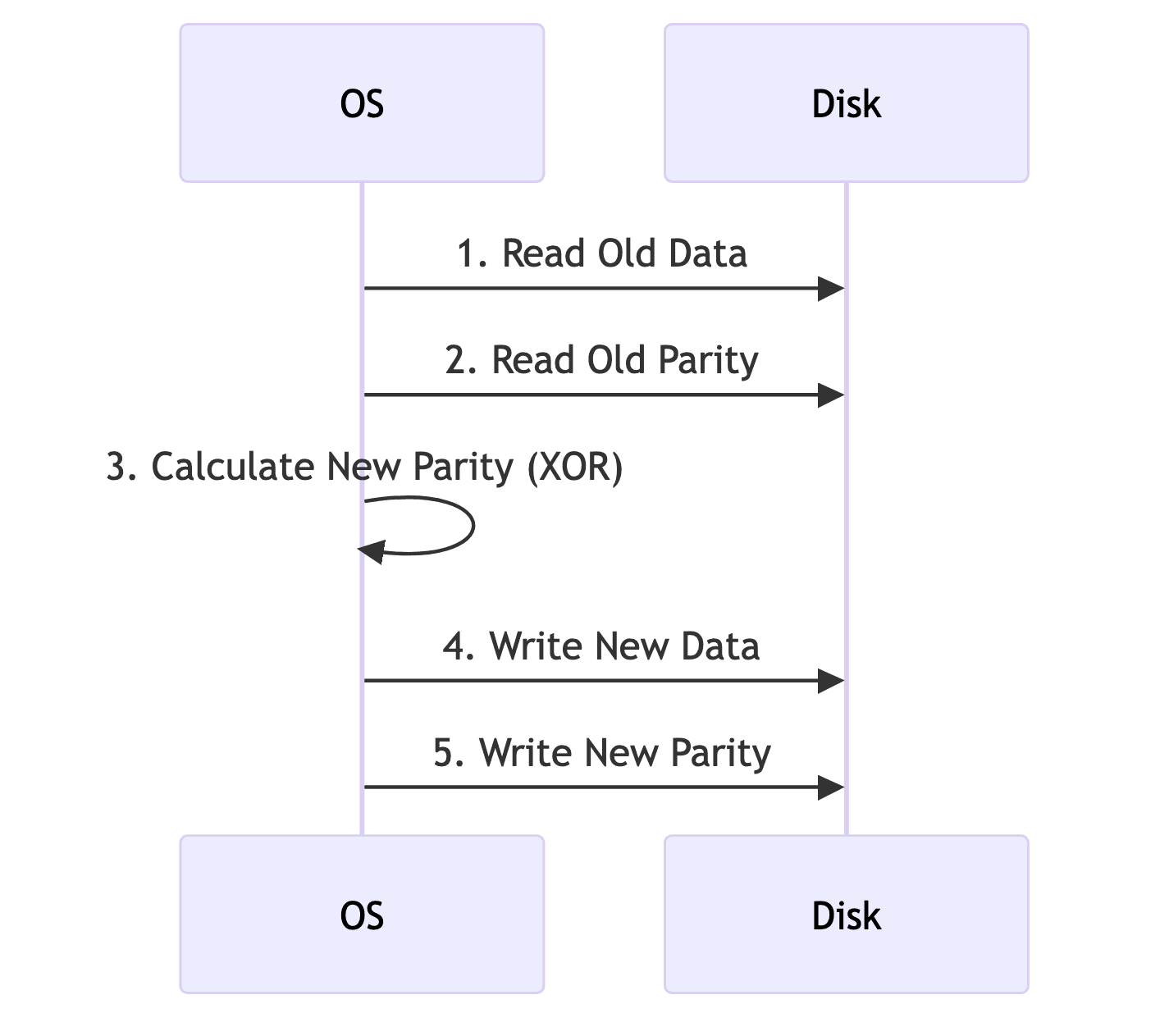
쓰기 단계 상세
- RAID 5 데이터 변경 시 4단계 프로세스
- 1단계
- 이전 데이터 읽기
- 2단계
- 이전 패리티 읽기
- 3단계
- 새 패리티 계산
- 4단계
- 새 데이터 + 새 패리티 쓰기
- 1단계
- 총 4개의 I/O 작업 필요
- 비교
- RAID 0
- 1개 I/O만 필요
- RAID 1
- 2개 I/O (양쪽 디스크에 동시 쓰기)
- RAID 0
I/O 비교
| RAID | 읽기 I/O | 쓰기 I/O | 총 I/O |
|---|---|---|---|
| RAID 0 | 0 | 1 | 1 |
| RAID 1 | 0 | 2 (양쪽 동시) | 2 |
| RAID 5 | 2 | 2 | 4 |
| RAID 6 | 3 | 3 | 6 |
- 결론
- RAID 5는 쓰기 시 4배 I/O
- 쓰기 성능이 중요하면 RAID 10 고려
Software RAID vs Hardware RAID
비교표
| 항목 | Software RAID (mdadm) | Hardware RAID |
|---|---|---|
| 관리 | OS/mdadm으로 관리 | 전용 RAID 컨트롤러 |
| 성능 | CPU 사용, 상대적으로 느림 | 전용 프로세서, 빠름 |
| 비용 | 저렴 (무료) | 높음 (컨트롤러 구매) |
| 유연성 | 매우 높음 (다양한 디스크 혼합) | 제한적 (호환 디스크만) |
| 이식성 | 다른 서버 이동 쉬움 | 매우 어려움 (동일 컨트롤러 필요) |
| 복구 | 쉬움 (mdadm으로 재구성) | 어려움 (특정 컨트롤러 의존) |
| 배터리 백업 | 없음 | 있음 (BBU) |
| 캐시 | OS 캐시 사용 | 전용 캐시 RAM |
선택 기준
- Software RAID 선택 시
- 예산 제한
- 유연한 구성 필요
- 클라우드 환경
- 소규모 서버
- Hardware RAID 선택 시
- 최고 성능 필요
- 24/7 미션 크리티컬
- 대규모 엔터프라이즈
- 배터리 백업 필수
RAID 실습 예제
전체 설정 과정
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
# 1. 디스크 추가 (VMware 예시)
# VM Settings → Hardware → Add → Hard Disk → 1GB × 5개
# 2. 디스크 확인
sudo fdisk -l
# 3. mdadm 설치 (CentOS/RHEL)
sudo yum install -y mdadm
# 또는 (Ubuntu/Debian)
sudo apt-get install -y mdadm
# 4. RAID 1 생성 (sdb, sdc 사용)
sudo mdadm --create /dev/md1 --level=1 --raid-devices=2 /dev/sdb /dev/sdc
# 5. RAID 5 생성 (sdd, sde, sdf 사용)
sudo mdadm --create /dev/md5 --level=5 --raid-devices=3 /dev/sdd /dev/sde /dev/sdf
# 6. RAID 상태 확인
sudo mdadm --detail /dev/md1
sudo mdadm --detail /dev/md5
cat /proc/mdstat
# 7. 설정 저장
sudo mdadm --detail --scan > /etc/mdadm.conf
cat /etc/mdadm.conf
# 8. 파일 시스템 생성
sudo mkfs.ext4 /dev/md1
sudo mkfs.ext4 /dev/md5
# 9. 마운트 포인트 생성
sudo mkdir -p /raid1 /raid5
# 10. UUID 확인
sudo blkid | grep md1
sudo blkid | grep md5
# 11. /etc/fstab 편집
sudo vi /etc/fstab
# UUID=xxx /raid1 ext4 defaults 1 2
# UUID=yyy /raid5 ext4 defaults 1 2
# 12. 마운트 및 확인
sudo mount -a
df -h
# 13. 재부팅 후 확인
sudo init 6
df -h
cat /proc/mdstat
권장 구성 가이드
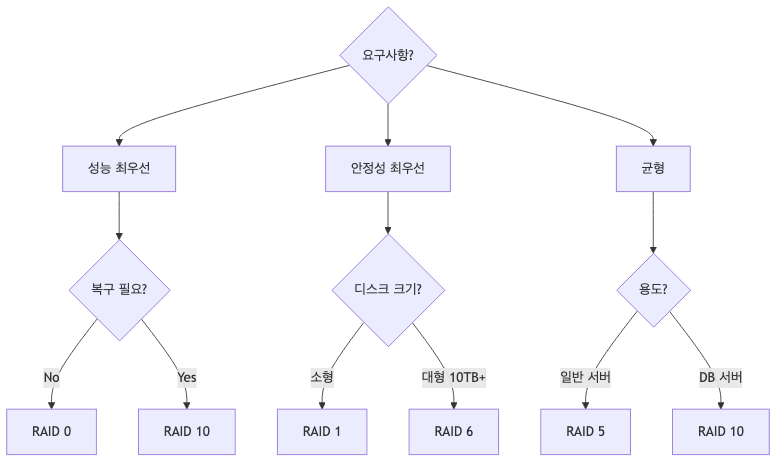
RAID 레벨 선택 기준
- 성능 최우선
- RAID 0 (복구 불가 감수)
- RAID 10 (비용 감수)
- 안정성 최우선
- RAID 1 (소형)
- RAID 6 (대형)
- 균형 잡힌 선택 (추천)
- 일반 서버
- RAID 5
- 10TB 이상
- RAID 6
- 고성능 DB
- RAID 10
- 일반 서버
정기 점검
1
2
3
4
5
6
7
8
9
10
# 주간 S.M.A.R.T 점검
sudo smartctl -a /dev/sda
sudo smartctl -H /dev/sda # 건강 상태만
# 월간 RAID 상태 점검
sudo mdadm --detail /dev/md0
cat /proc/mdstat
# 이메일 알림 설정
sudo mdadm --monitor --scan --mail=admin@example.com --delay=1800
백업 전략
- RAID는 백업이 아님
- 하드웨어 장애만 보호
- 실수 삭제, 랜섬웨어, 논리 오류는 못 막음
- 3-2-1 백업 규칙
- 3개 복사본
- 2개 다른 미디어
- 1개 오프사이트
- RAID + 백업 조합
- RAID로 가용성 확보
- 정기 백업으로 재해 복구
트러블슈팅
일반적인 문제
| 문제 | 원인 | 해결 방법 | ||||
| —— | —— | ———– | Degraded 상태 | 디스크 1개 실패 | 즉시 디스크 교체 및 리빌드 | |
| 리빌드 느림 | 시스템 부하 높음 | sync_speed_min/max 조정 |
||||
| RAID 부팅 안 됨 | mdadm.conf 누락 | initramfs 재생성 | ||||
| 디스크 추가 안 됨 | Superblock 잔여 | --zero-superblock 실행 |
||||
| 성능 저하 | Write Penalty | RAID 레벨 변경 고려 |
리빌드 속도 조정
1
2
3
4
5
6
7
8
9
# 최소 속도 설정 (KB/sec)
echo 50000 > /proc/sys/dev/raid/speed_limit_min
# 최대 속도 설정
echo 200000 > /proc/sys/dev/raid/speed_limit_max
# 영구 설정
echo "dev.raid.speed_limit_min = 50000" >> /etc/sysctl.conf
echo "dev.raid.speed_limit_max = 200000" >> /etc/sysctl.conf
요약 및 빠른 참조
RAID 선택 플로우
핵심 명령어
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 생성
mdadm -C /dev/md0 -l 5 -n 3 /dev/sd[a-c]
# 확인
cat /proc/mdstat
mdadm -D /dev/md0
# 디스크 관리
mdadm /dev/md0 -a /dev/sdd # 추가
mdadm /dev/md0 -f /dev/sdd # 실패
mdadm /dev/md0 -r /dev/sdd # 제거
# 설정 저장
mdadm -D -s > /etc/mdadm.conf
# 중지/시작
mdadm -S /dev/md0 # 중지
mdadm --run /dev/md0 # 시작
핵심 기억 사항
- RAID는 백업이 아님
- 하드웨어 장애만 보호
- 별도 백업 필수
- 대용량은 RAID 6
- 10TB 이상 디스크
- 리빌드 중 2차 실패 대비
- Degraded 즉시 조치
- 추가 실패 시 전체 손실
- 읽기 전용 전환 후 복구
- 정기 점검 필수
- S.M.A.R.T 모니터링
- RAID 상태 확인
DevOps 엔지니어 체크리스트
- RAID 레벨 선택
- 일반 서버
- RAID 5 추천
- 대용량 디스크 (10TB+)
- RAID 6 필수
- 고성능 DB
- RAID 10 고려
- 일반 서버
- 모니터링 설정
- S.M.A.R.T 주간 점검
- RAID 상태 월간 확인
- 이메일 알림 구성
- 백업 전략
- RAID + 별도 백업 필수
- 3-2-1 규칙 준수
- 성능 고려사항
- Write Penalty 이해
- 쓰기 중심 워크로드는 RAID 10
- 읽기 중심 워크로드는 RAID 5/6