voidbubbleSort(int[]array){intn=array.length;for(inti=0;i<n-1;i++){booleanswapped=false;for(intj=0;j<n-1-i;j++){if(array[j]>array[j+1]){// 교환inttemp=array[j];array[j]=array[j+1];array[j+1]=temp;swapped=true;}}// 교환이 없으면 이미 정렬된 상태if(!swapped)break;}}
배열의 두 번째 요소부터 시작하여, 각 요소를 이미 정렬된 부분 배열의 올바른 위치에 삽입함
카드 게임에서 카드를 정렬하는 방식과 유사함
현재 요소를 이미 정렬된 부분과 비교하며 적절한 위치를 찾음
시간 복잡도
평균: $O(n^2)$
최악: $O(n^2)$
최선: $O(n)$
공간 복잡도
$O(1)$
안정성
안정적임
작은 데이터셋에 효율적이며, 거의 정렬된 상태의 데이터에서 매우 빠름
온라인 정렬(streaming data)에 적합함
class="highlight">
1
2
3
4
5
6
7
8
9
10
11
12
13
voidinsertionSort(int[]array){for(inti=1;i<array.length;i++){intkey=array[i];intj=i-1;// key보다 큰 요소들을 한 칸씩 뒤로 이동while(j>=0&&array[j]>key){array[j+1]=array[j];j--;}array[j+1]=key;}}
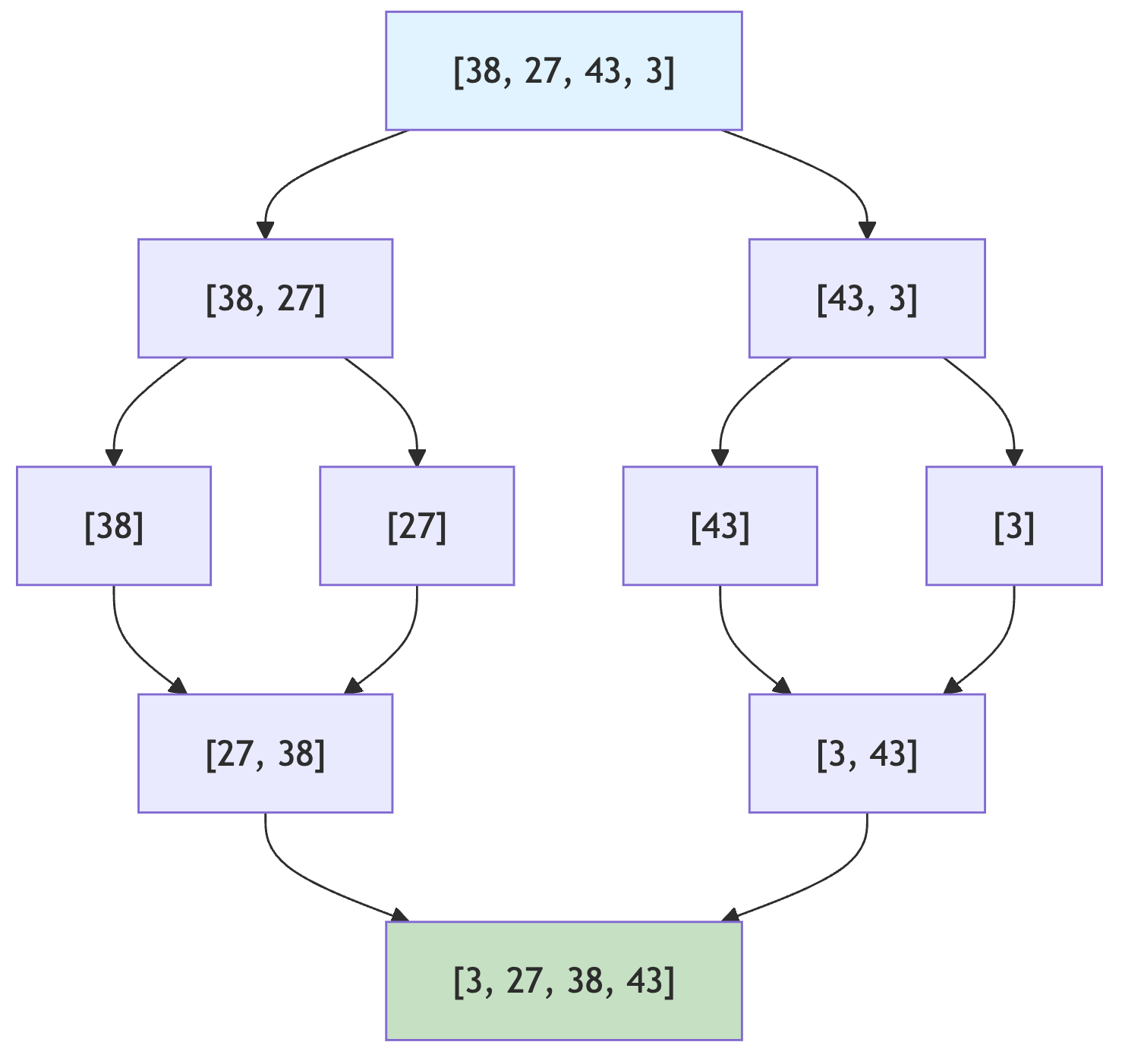
voidmergeSort(int[]array){if(array.length<=1)return;intmid=array.length/2;int[]left=newint[mid];int[]right=newint[array.length-mid];System.arraycopy(array,0,left,0,mid);System.arraycopy(array,mid,right,0,array.length-mid);mergeSort(left);mergeSort(right);merge(array,left,right);}voidmerge(int[]array,int[]left,int[]right){inti=0,j=0,k=0;// 두 배열을 비교하며 병합while(i<left.length&&j<right.length){array[k++]=left[i]<=right[j]?left[i++]:right[j++];}// 남은 요소 복사while(i<left.length)array[k++]=left[i++];while(j<right.length)array[k++]=right[j++];}
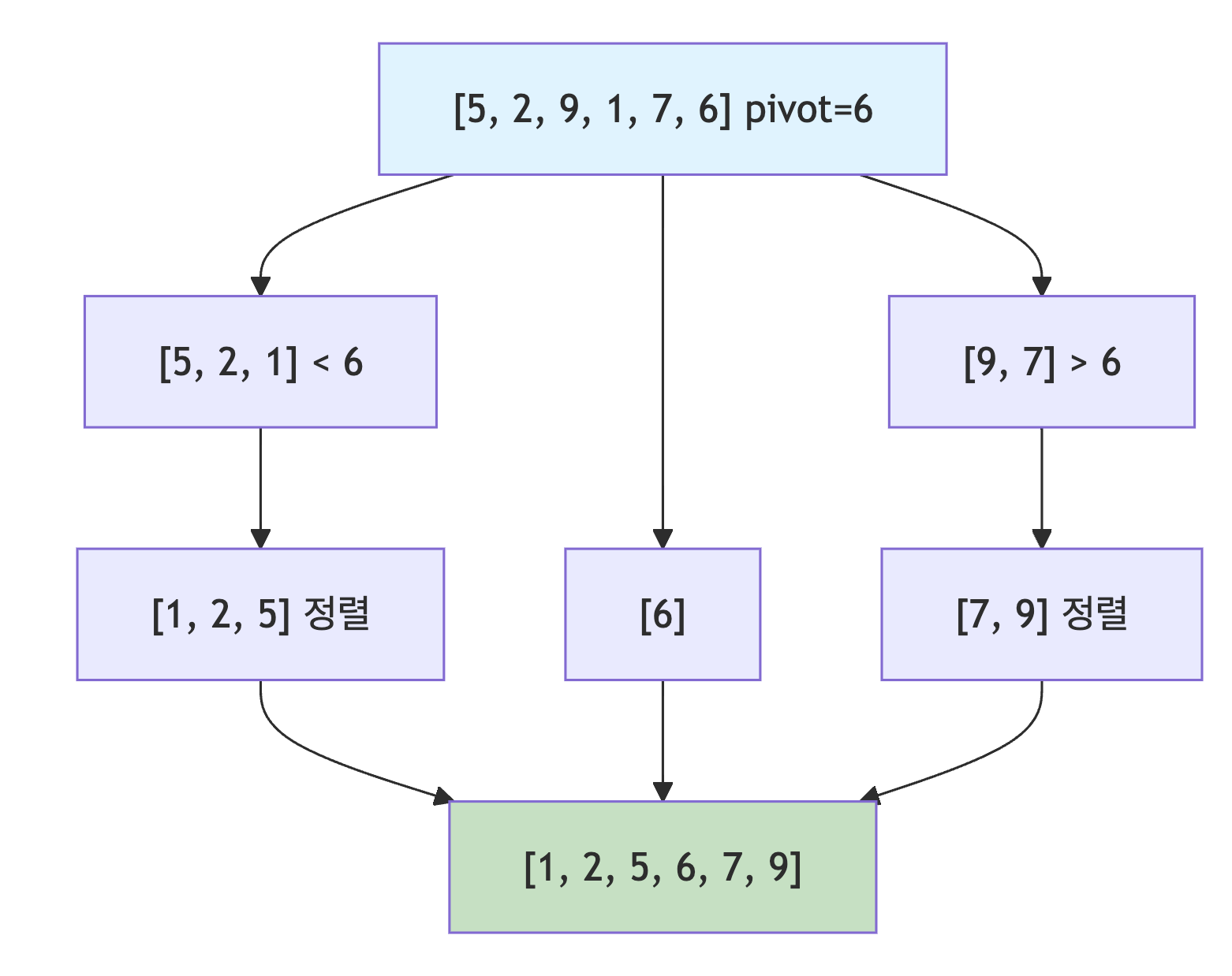
퀵 정렬
분할 정복 기법을 사용함
피벗(pivot)이라는 기준값을 선택하여 배열을 분할한 후, 각 부분을 재귀적으로 정렬함
피벗보다 작은 요소는 왼쪽, 큰 요소는 오른쪽으로 이동함
시간 복잡도
평균: $O(n \log n)$
최악: $O(n^2)$
최악의 경우는 이미 정렬된 배열이나 역순 배열에서 피벗을 잘못 선택했을 때 발생함
단순히 마지막 요소를 피벗으로 잡을 경우, 정렬된 데이터에서 성능이 급격히 저하됨
실무에서는 난수 분할(Randomized Partition)이나 중앙값(Median-of-Three) 방식을 사용하여 해결함
voidquickSort(int[]array,intleft,intright){if(left<right){intpivot=partition(array,left,right);quickSort(array,left,pivot-1);quickSort(array,pivot+1,right);}}intpartition(int[]array,intleft,intright){intpivot=array[right];// 마지막 요소를 피벗으로 선택inti=left-1;for(intj=left;j<right;j++){if(array[j]<pivot){i++;// 교환inttemp=array[i];array[i]=array[j];array[j]=temp;}}// 피벗을 중간 위치로 이동inttemp=array[i+1];array[i+1]=array[right];array[right]=temp;returni+1;}
voidheapSort(int[]array){intn=array.length;// 최대 힙 구성for(inti=n/2-1;i>=0;i--){heapify(array,n,i);}// 힙에서 요소를 하나씩 추출하여 정렬for(inti=n-1;i>0;i--){// 루트(최댓값)를 끝으로 이동inttemp=array[0];array[0]=array[i];array[i]=temp;// 나머지 요소로 힙 재구성heapify(array,i,0);}}voidheapify(int[]array,intn,inti){intlargest=i;intleft=2*i+1;intright=2*i+2;// 왼쪽 자식이 더 크면if(left<n&&array[left]>array[largest]){largest=left;}// 오른쪽 자식이 더 크면if(right<n&&array[right]>array[largest]){largest=right;}// 가장 큰 값이 루트가 아니면 교환if(largest!=i){inttemp=array[i];array[i]=array[largest];array[largest]=temp;// 재귀적으로 힙 재구성heapify(array,n,largest);}}
voidradixSort(int[]array){if(array.length==0)return;// 최댓값 찾기intmax=array[0];for(intnum:array){if(num>max)max=num;}// 각 자리수마다 정렬for(intexp=1;max/exp>0;exp*=10){countingSortByDigit(array,exp);}}voidcountingSortByDigit(int[]array,intexp){intn=array.length;int[]output=newint[n];int[]count=newint[10];// 현재 자리수의 숫자 카운팅for(inti=0;i<n;i++){count[(array[i]/exp)%10]++;}// 누적 카운트for(inti=1;i<10;i++){count[i]+=count[i-1];}// 정렬된 결과 생성for(inti=n-1;i>=0;i--){intdigit=(array[i]/exp)%10;output[count[digit]-1]=array[i];count[digit]--;}// 원본 배열에 복사System.arraycopy(output,0,array,0,n);}
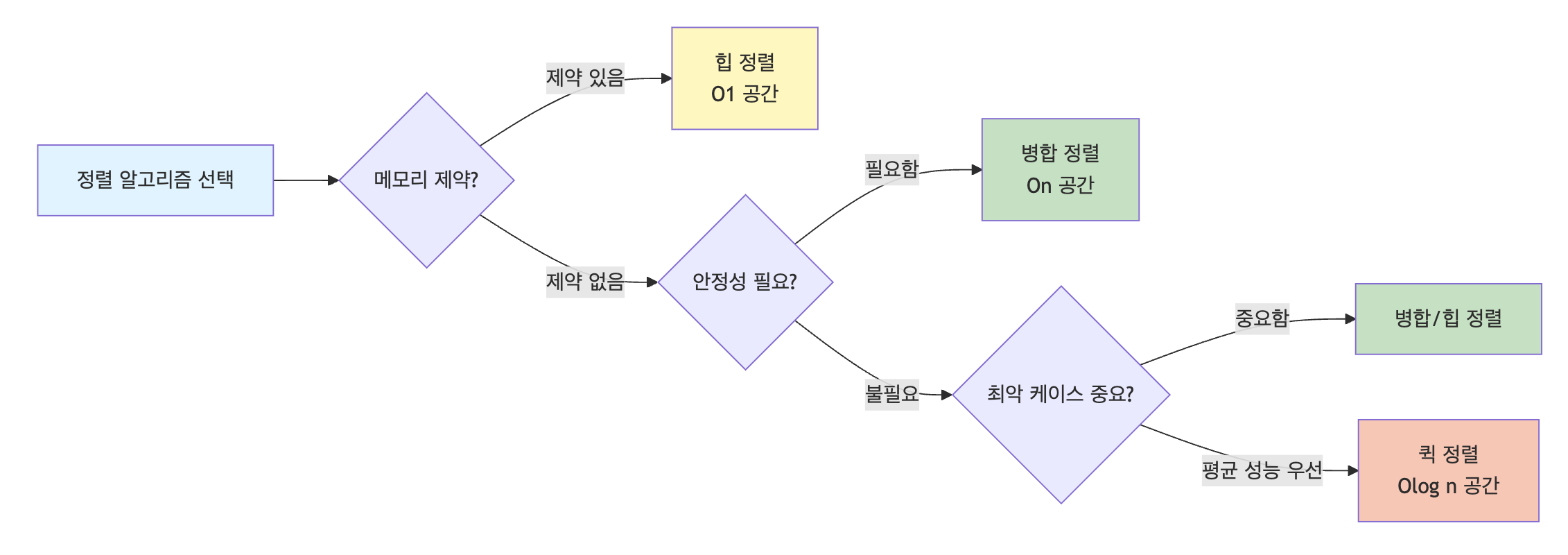
상황별 정렬 알고리즘 선택 가이드
데이터 크기에 따른 선택
작은 데이터셋 (n < 50)
삽입 정렬이 효율적임
중간 크기 데이터셋
퀵 정렬이 일반적으로 가장 빠름
대규모 데이터셋
병합 정렬이나 힙 정렬로 안정적인 성능 보장
데이터 특성에 따른 선택
거의 정렬된 데이터
삽입 정렬이나 버블 정렬의 최적화 버전이 좋음
역순으로 정렬된 데이터
퀵 정렬은 피하고 병합 정렬 사용
중복이 많은 데이터
3-way 퀵 정렬이나 계수 정렬 고려
요구사항에 따른 선택
일반적인 경우
퀵 정렬 - 대부분의 프로그래밍 언어의 표준 라이브러리가 퀵 정렬 기반임
최악의 경우 보장 필요
병합 정렬이나 힙 정렬
안정한 정렬 필요
병합 정렬이나 삽입 정렬
메모리 제약이 심할 때
힙 정렬 (제자리 정렬)
정수 범위가 제한적
계수 정렬이나 기수 정렬
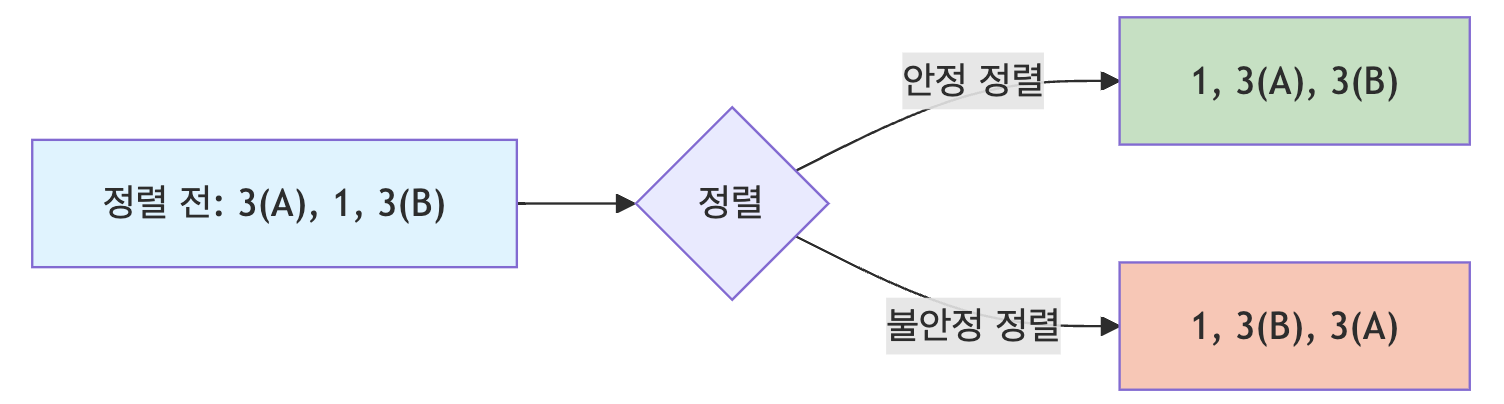
안정성의 의미
안정성이란 동일한 값을 가진 요소들이 정렬 후에도 정렬 전의 상대적 순서를 유지하는 특성임
예를 들어, 여러 학생의 성적을 이름으로 정렬할 때 같은 성적을 받은 학생들은 원래 순서대로 유지되어야 한다면 안정한 정렬이 필요함
`
안정성이 중요한 경우
여러 기준으로 순차적으로 정렬할 때
데이터의 원래 순서가 의미를 가질 때
정렬 전 인덱스 정보를 보존해야 할 때
안정한 정렬과 불안정한 정렬
안정한 정렬
버블 정렬, 삽입 정렬, 병합 정렬, 계수 정렬, 기수 정렬
불안정한 정렬
선택 정렬, 퀵 정렬, 힙 정렬
정리
정렬 알고리즘은 데이터를 일정한 순서로 배치하는 핵심 알고리즘임
비교 정렬은 $O(n \log n)$, 비교하지 않는 정렬은 특정 조건에서 $O(n)$까지 가능함
각 알고리즘은 시간 복잡도, 공간 복잡도, 안정성 면에서 서로 다른 특성을 가짐
작은 데이터는 삽입 정렬, 일반적인 경우는 퀵 정렬, 최악 보장이 필요하면 병합/힙 정렬을 사용함
정수 범위가 제한적이면 계수 정렬이나 기수 정렬로 $O(n)$ 성능을 얻을 수 있음
정렬 알고리즘의 선택은 시간 복잡도뿐만 아니라 데이터 특성, 메모리 상황, 안정성 요구사항을 종합적으로 고려해야 함
 `
`