스프링 데이터 JPA 분석
- 김영한님의 실전! 스프링 데이터 JPA 강의를 기반으로 스프링 데이터 JPA 구현체인
SimpleJpaRepository의 구동 원리, 트랜잭션 전파, 그리고 엔티티 신규 저장 판별 전략(Persistable)을 정리함
스프링 데이터 JPA 구현체 분석
-
스프링 데이터 JPA가 제공하는 공용 인터페이스 계층 구조가 종단에서 의존하는 구체클래스는
SimpleJpaRepository임1
org.springframework.data.jpa.repository.support.SimpleJpaRepository
-
SimpleJpaRepository주요 속성 및 클래스 레벨 설정1 2 3 4 5 6 7 8 9 10 11 12 13 14
@Repository @Transactional(readOnly = true) public class SimpleJpaRepository<T, ID> { @Transactional public <S extends T> S save(S entity) { if (entityInformation.isNew(entity)) { em.persist(entity); return entity; } else { return em.merge(entity); } } }
@Repository의 기능적 역할- 스프링 컴포넌트 스캔 대상이 될 뿐만 아니라, 하부 JPA 예외를 스프링이 지정한 계층적 예외 체계로 변환해 주는 역할을 수행하여 이식성 높은 코드를 구성할 수 있음
-
@Transactional트랜잭션 전파 및 클래스 레벨 분리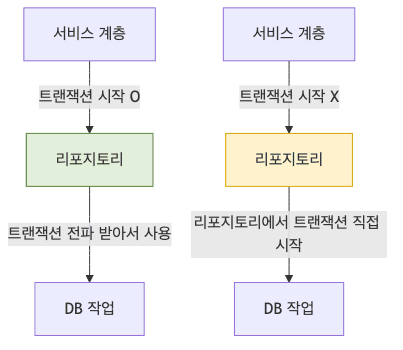
- JPA에서 데이터의 모든 등록, 수정, 삭제 사이클은 거시적인 한 트랜잭션 안에서 이루어져야 함
- 서비스 계층에서 명시적으로 트랜잭션을 진입했다면 스프링 데이터 JPA 리포지토리는 해당 기존 트랜잭션을 전파받아서 참여하지만, 만약 상위에서 트랜잭션이 존재하지 않는다고 해도 리포지토리 계층 차원에서 스스로 트랜잭션을 생성하여 작업을 완수함
- 리포지토리 클래스 전반에 걸쳐
@Transactional(readOnly = true)가 베이스로 지정되어 있으므로, 데이터 개입이 없는 단순 조회 등에서는 JPA 플러시 처리를 생략하므로 약간의 성능 최적화를 얻을 수 있고 오직 쓰기 작업을 진행하는 일부 메서드에만 별도로@Transactional이 다시 활성화되어 작동함
save() 메서드 동작 원리
-
save()메서드는 단순히 저장만 수행하는 것이 아니라 전달된 엔티티가 새로운 엔티티로 판단될 경우와 이미 영속 상태를 거쳤던 엔티티인 경우에 따라 다른 처리를 함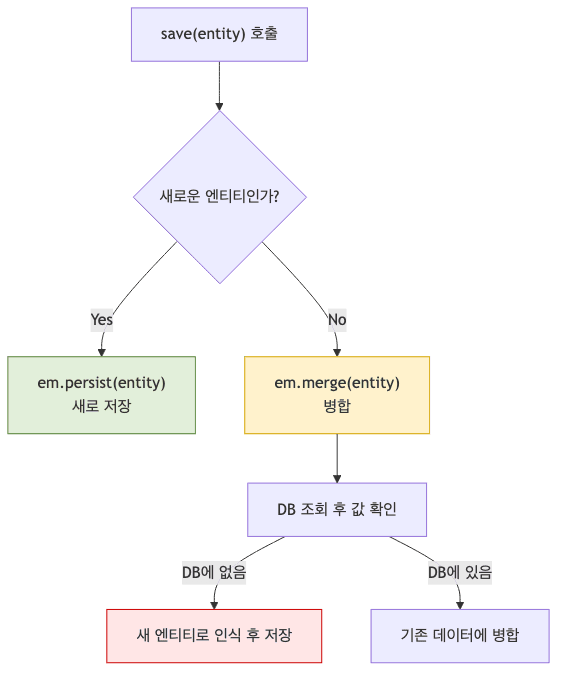
-
핵심 요점
- 전달된 엔티티가 신규일 경우 바로
em.persist(...)를 시도함 - 신규가 아니라고 판별될 경우 병합 처리를 위해
em.merge(...)를 시도하며, 병합 전 반드시 DB 조회를 수반함 - 따라서 신규 엔티티의 판명 조건이 충족되지 않은 상태에서
save()가 호출되면 필요 없는SELECT오버헤드가 발생하게 됨
- 전달된 엔티티가 신규일 경우 바로
새로운 엔티티를 구별하는 방법
-
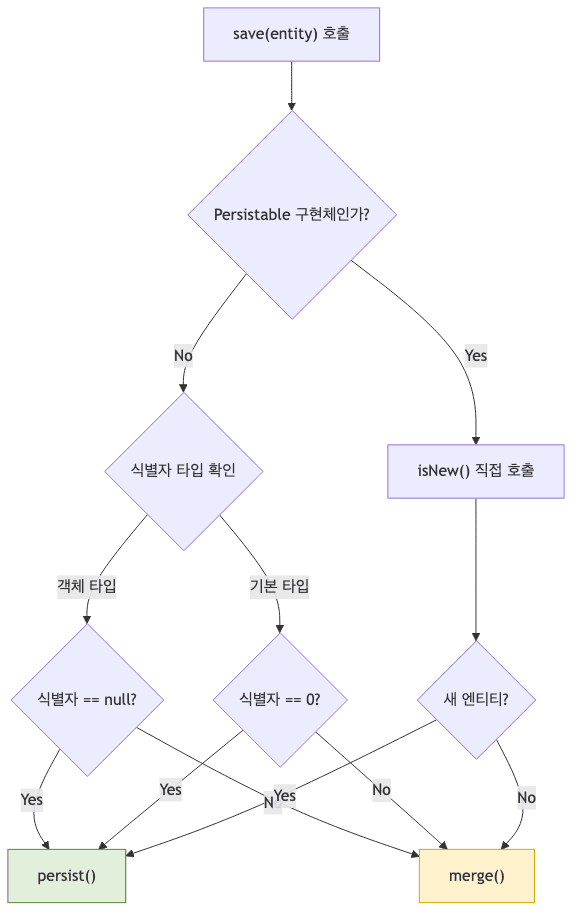
스프링 데이터 JPA는 엔티티의 식별자 값 상태를 기반으로 신규 엔티티 등록과 기존 데이터 병합을 구분함
- 기본 판별 전략
- 객체 타입 (예:
Long,String,UUID등 객체 래퍼 포함)- 해당 식별자 값이
null일 때 새 엔티티로 판별함
- 해당 식별자 값이
- 자바 기본 타입 (예:
long,int등 원시 타입)- 해당 식별자의 값이
0일 때 새 엔티티로 판별함
- 해당 식별자의 값이
- 객체 타입 (예:
-
@GeneratedValue사용 (이상적인 동작)
- 시퀀스나 아이덴티티 방식 등
@GeneratedValue를 위탁할 경우, 코드상save()시점의 인스턴스는 여전히 식별자 값이null상태이므로isNew()판별은 정상적으로 참(true)을 반환하며 곧바로persist()분기로 이동함
- 시퀀스나 아이덴티티 방식 등
-
@Id수동 지정 사용
- 문자열이나 조합키 등을 활용하여 직접 식별자를 미리 할당해둔 상태로
save()에 보내게 되면 식별자는null도0도 아니므로isNew()가 거짓(false)을 도출함 - 결국 이미 존재하는 엔티티로 강제 분류되어
merge()가 발생하고, 무작정 DB의 데이터 존재 유무를 검사하기 위해 사전 단일 조회 쿼리인SELECT가 불필요하게 낭비됨
- 문자열이나 조합키 등을 활용하여 직접 식별자를 미리 할당해둔 상태로
- 커스텀 신규 식별 방식
- 식별자 조작 방식의 문제를 해소하기 위해 엔티티 클래스에서 외부
Persistable인터페이스를 장착하고 자체 검증 로직을 구현함
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
@Entity @EntityListeners(AuditingEntityListener.class) @NoArgsConstructor(access = AccessLevel.PROTECTED) public class Item implements Persistable<String> { @Id private String id; @CreatedDate private LocalDateTime createdDate; public Item(String id) { this.id = id; } @Override public String getId() { return id; // 식별자는 생성자에서 주입 } @Override public boolean isNew() { // 등록 이력 정보가 없는 경우 새 인스턴스로 판단하도록 함 return createdDate == null; } }
-
Persistable인터페이스를 구현하고 JPA Auditing의 등록일시(@CreatedDate) 값을 검사하여 현재 인스턴스가 실질적으로 새로운 엔티티에 속하는지 명확하게 판단하는 것이 권장됨
- 식별자 조작 방식의 문제를 해소하기 위해 엔티티 클래스에서 외부
요약 정리
- 스프링 데이터 JPA의
SimpleJpaRepository는 모든 인터페이스 기반 동작을 실제로 처리하는 기본 단위로 트랜잭션이 클래스 레벨의 읽기 전용(readOnly=true)으로 최적화되어 있고 변경 메서드에만 쓰기 권한이 부여됨 - 구현체 내부의
save()메서드는 식별자 데이터 유무에 따라 판단한 신규 엔티티의 조건이 참이면persist()를, 거짓이면 조회 쿼리를 선행하는merge()를 호출하도록 동작함 - 식별자를
em.persist()이전에 임의 할당(@Id단독 사용)하는 구조에서는 강제로 데이터베이스 한 번 더 조회하는 현상이 발생하므로, 이때는Persistable인터페이스를 재구현하여 Auditing의@CreatedDate를 통한 신규 여부 로직을 명확하게 이입시켜 주어야 조회 낭비를 차단할 수 있음