데이터 접근 기술 활용 방안 - 실전 가이드
- 김영한님의 스프링 DB 2편 강의를 바탕으로, 실무에서 다양한 데이터 접근 기술을 어떻게 조합하고 어떤 구조로 설계하는 것이 효율적인지 정리함
트레이드 오프와 선택
어댑터 패턴과 직접 사용 비교

-
어댑터 패턴 사용 시 (구조적 안정성 중시)
- 서비스 계층이 특정 기술(Spring Data JPA 등)에 종속되지 않고 순수한 인터페이스에만 의존함
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
// ItemService @Service @RequiredArgsConstructor public class ItemService { private final ItemRepository itemRepository; // 인터페이스 의존 public Item save(Item item) { return itemRepository.save(item); } } // JpaItemRepositoryV2 (어댑터) @Repository @RequiredArgsConstructor public class JpaItemRepositoryV2 implements ItemRepository { private final SpringDataJpaItemRepository repository; // Spring Data JPA @Override public Item save(Item item) { return repository.save(item); } }
- 장점
- 기술 교체가 용이하고 테스트가 쉬움 (DI/OCP 준수)
- 단점
- 어댑터 클래스를 하나하나 만들어야 해서 코드가 복잡해지고 관리할 파일이 늘어남
-
직접 사용 시 (단순함과 생산성 중시)
- 서비스 계층이
Spring Data JPA나Querydsl리포지토리를 직접 의존함
1 2 3 4 5 6 7 8 9 10 11
// ItemService @Service @RequiredArgsConstructor public class ItemService { private final ItemRepositoryV2 itemRepositoryV2; private final ItemQueryRepositoryV2 itemQueryRepositoryV2; // 직접 의존 public Item save(Item item) { return repository.save(item); } }
- 장점
- 구조가 직관적이고 개발 속도가 빠르며 코드량이 줄어듦
- 단점
- 기술 변경 시 서비스 코드도 수정해야 함 (DI/OCP 일부 위배)
- 서비스 계층이
선택 가이드
- 프로젝트 규모가 작거나 기술 변경 가능성이 낮다면 직접 사용하는 방식이 훨씬 생산적일 수 있음
- 반면 대규모 프로젝트나 장기적인 유지보수, 기술 교체가 예상된다면 어댑터 패턴을 고려하는 것이 좋음
실용적인 구조 설계
Querydsl과 Spring Data JPA의 분리
- Spring Data JPA는 기본 CRUD에 매우 강하지만, 복잡한 동적 쿼리에는 약함
- Querydsl은 동적 쿼리에 강하지만, 기본 CRUD용으로는 번거로움
- 이 둘을 하나의 리포지토리(Custom 인터페이스 구현)에 억지로 넣기보다는, 아예 서로 다른 리포지토리로 분리하여 사용하는 전략이 실용적임
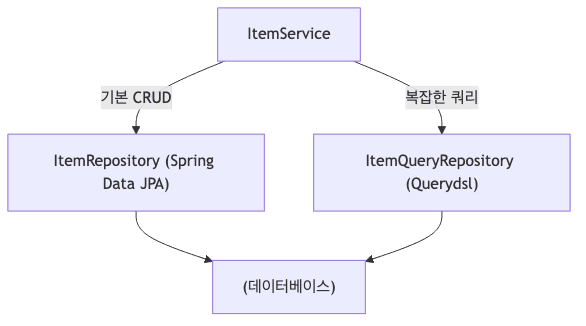
권장 아키텍처 (V2)
1
2
3
ItemService
├─ ItemRepository (Spring Data JPA) -> 기본 CRUD 담당
└─ ItemQueryRepository (Querydsl) -> 복잡한 조회, 동적 쿼리 담당
- ItemRepository (Spring Data JPA)
save(),findById(),delete()등 단순한 기능 처리
- ItemQueryRepository (Querydsl)
@Repository를 붙여서 별도의 빈으로 등록- 복잡한 통계 쿼리나 검색 조건이 많은 조회 쿼리 전담
- 서비스 계층(
ItemService)에서는 필요한 리포지토리를 주입받아 사용함- “단순한 건 Spring Data JPA, 복잡한 건 Querydsl”로 명확히 역할 분담 가능
핵심 코드 구현
- ItemRepositoryV2 (스프링 데이터 JPA)
- 기본 CRUD와 단순 조회 담당
1 2 3
public interface ItemRepositoryV2 extends JpaRepository<Item, Long> { // 단순 조회는 Spring Data JPA가 담당 }
- ItemQueryRepositoryV2 (Querydsl)
- 복잡한 조회와 동적 쿼리 담당
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35
@Repository public class ItemQueryRepositoryV2 { private final JPAQueryFactory query; public ItemQueryRepositoryV2(EntityManager em) { this.query = new JPAQueryFactory(em); } public List<Item> findAll(ItemSearchCond cond) { return query .select(item) .from(item) .where( likeItemName(cond.getItemName()), maxPrice(cond.getMaxPrice()) ) .fetch(); } // 동적 쿼리 조건 (재사용 가능) private BooleanExpression likeItemName(String itemName) { if (StringUtils.hasText(itemName)) { return item.itemName.like("%" + itemName + "%"); } return null; } private BooleanExpression maxPrice(Integer maxPrice) { if (maxPrice != null) { return item.price.loe(maxPrice); } return null; } }
- ItemServiceV2 (서비스 계층)
- 두 리포지토리를 조합하여 사용
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
@Service @RequiredArgsConstructor @Transactional public class ItemServiceV2 implements ItemService { private final ItemRepositoryV2 itemRepositoryV2; // Spring Data JPA private final ItemQueryRepositoryV2 itemQueryRepositoryV2; // Querydsl @Override public void update(Long itemId, ItemUpdateDto updateParam) { Item findItem = findById(itemId).orElseThrow(); // setter 대신 의미있는 메서드 사용 권장 findItem.setItemName(updateParam.getItemName()); findItem.setPrice(updateParam.getPrice()); findItem.setQuantity(updateParam.getQuantity()); } @Override public List<Item> findItems(ItemSearchCond cond) { return itemQueryRepositoryV2.findAll(cond); // 복잡한 쿼리 위임 } // save, findById 등 단순 로직은 itemRepositoryV2 위임 }
- V2Config (설정)
ItemRepositoryV2는 스프링 데이터 JPA가 자동으로 빈 등록함
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
@Configuration @RequiredArgsConstructor public class V2Config { private final EntityManager em; private final ItemRepositoryV2 itemRepositoryV2; // Spring Data JPA 자동 주입 @Bean public ItemService itemService() { return new ItemServiceV2(itemRepositoryV2, itemQueryRepository()); } @Bean public ItemQueryRepositoryV2 itemQueryRepository() { return new ItemQueryRepositoryV2(em); } @Bean public ItemRepository itemRepository() { return new JpaItemRepositoryV3(em); } }
다양한 기술 조합
기술별 특징과 역할
- Spring Data JPA
- 역할
- 핵심 비즈니스 로직, 기본 CRUD (생산성 최우선)
- 특징
- 반복 코드를 없애주고 객체지향적인 개발 가능
- 역할
- Querydsl
- 역할
- 복잡한 조회 쿼리, 동적 쿼리
- 특징
- JPA의 한계를 보완해주는 필수 파트너
- 역할
- JdbcTemplate / MyBatis
- 역할
- 매우 복잡한 통계 쿼리, 대용량 배치 처리가 필요한 경우, SQL 힌트 사용 등 성능 최적화
- 특징
- SQL을 직접 다룰 수 있어 세밀한 제어가 가능함
- 역할
- 기본적으로 JPA + Spring Data JPA + Querydsl 조합을 메인으로 사용
- 이 조합으로 해결이 안 되는 특수한 성능 이슈나 복잡한 SQL이 필요할 때만 JdbcTemplate나 MyBatis를 부분적으로 도입하여 하이브리드 방식으로 사용
트랜잭션 매니저
JpaTransactionManager의 활용
- 스프링의
JpaTransactionManager는 JPA뿐만 아니라 DataSourceTransactionManager가 하는 역할도 대부분 수행할 수 있음 -
따라서
JpaTransactionManager하나만 등록해두면 JPA, JdbcTemplate, MyBatis 모두 하나의 트랜잭션으로 묶어서 통합 관리가 가능함1 2 3 4 5 6 7 8
@Configuration public class AppConfig { @Bean public PlatformTransactionManager transactionManager(EntityManagerFactory emf) { // JPA, JdbcTemplate, MyBatis 통합 트랜잭션 관리 return new JpaTransactionManager(emf); } }
주의할 점
- JPA와 다른 기술 함께 사용 시 플러시(Flush) 시점 주의
- JPA는 트랜잭션 커밋 시점(또는 쿼리 실행 직전)에 영속성 컨텍스트의 내용을 DB에 반영(Flush)함
- 하지만 JdbcTemplate이나 MyBatis는 SQL을 즉시 실행함
- 따라서 JPA로 데이터를 수정한 후, 같은 트랜잭션 내에서 JdbcTemplate으로 조회하면 수정된 내용이 보이지 않을 수 있음
- 해결책
- JPA로 변경한 내용을 다른 기술에서 즉시 참조해야 한다면,
em.flush()를 호출하여 강제로 DB에 반영한 뒤에 JdbcTemplate 등을 실행해야 함
1 2 3 4 5 6 7 8 9 10 11 12
@Transactional public void updateAndQuery(Long itemId) { // JPA로 데이터 변경 (영속성 컨텍스트) Item item = jpaRepository.findById(itemId).orElseThrow(); item.setPrice(20000); // 명시적 플러시 (DB 반영) em.flush(); // JdbcTemplate/MyBatis로 조회 (DB 직접 조회) Integer price = jdbcRepository.findPriceById(itemId); }
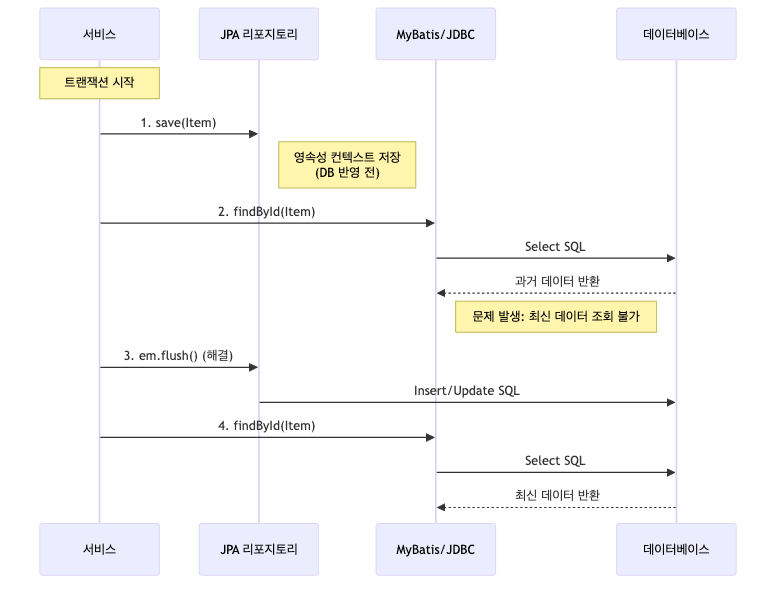
- JPA로 변경한 내용을 다른 기술에서 즉시 참조해야 한다면,
연습 문제
-
스프링 데이터 JPA 사용 시 인터페이스와 어댑터 계층을 두는 방식과 스프링 데이터 JPA를 서비스에서 직접 사용하는 방식의 주요 트레이드오프는 무엇일까요?
a. 구조적 유연성(DI/OCP) vs 구조적 단순성/빠른 개발
- 어댑터 계층은 DI/OCP 원칙을 지켜 구조 유연성을 높이지만 코드가 복잡해짐
- 직접 사용은 구조가 단순하고 개발이 빠르지만, 구현 기술 변경 시 서비스 코드 수정이 필요할 수 있음
-
강의에서 언급된 바에 따르면, 프로젝트 규모는 구조 설계 시 어떤 결정에 주로 영향을 미치나요?
a. 작은 프로젝트는 광범위한 추상화보다 단순성을 우선시하는 경우가 많다.
- 작은 프로젝트나 프로토타입에서는 과도한 추상화 비용이 오히려 낭비일 수 있음
- 빠른 개발과 단순한 구조가 더 실용적인 접근법이 될 수 있음
-
스프링 데이터 JPA와 Querydsl을 조합하여 사용하는 실용적인 구조의 주요 장점은 무엇일까요?
a. 단순 CRUD는 Spring Data JPA로, 복잡 쿼리는 Querydsl로 분리 처리한다.
- 역할을 명확히 분리하여 각 기술의 장점을 극대화함
- 복잡한 커스텀 구현을 하나의 인터페이스에 몰아넣는 복잡함을 피할 수 있음
-
같은 트랜잭션 내에서 JPA와 JDBC Template/MyBatis를 함께 사용할 때 발생할 수 있는 잠재적인 데이터 일관성 문제와 해결 방법은 무엇인가요?
a. JPA 변경 사항이 JDBC에서 안 보임; JPA의
flush()를 사용한다.- JPA의 지연 쓰기(Lazy Write) 특성 때문에 발생함
- JPA 로직 실행 후 명시적으로
flush()를 호출하여 DB와 동기화하면 해결됨
-
강의에서 개발 생산성을 중시하며 다양한 로직이 포함된 일반적인 애플리케이션 개발에 주로 추천하는 데이터 접근 기술 조합은 무엇인가요?
a. JPA와 Spring Data, Querydsl 조합
- 생산성, 유지보수성, 성능 최적화 등을 모두 고려할 때 가장 균형 잡힌 최선의 조합임
요약 정리
- 실용적인 구조 선택이 중요하며 무조건적인 추상화보다는 프로젝트 상황에 맞춰 복잡도와 유연성 사이에서 균형을 찾아야 함
- Querydsl 전용 리포지토리를 별도로 분리하여 기본 CRUD는 Spring Data JPA로, 복잡한 조회는 Querydsl로 처리하는 것이 유지보수에 유리함
- 기술 조합은 기본적으로 JPA 계열(JPA + Spring Data JPA + Querydsl)을 메인으로 사용하고, 복잡한 쿼리나 성능 최적화가 필요할 때만 JdbcTemplate이나 MyBatis를 보조로 사용하는 것이 좋음
JpaTransactionManager하나로 대부분의 데이터 접근 기술 트랜잭션을 통합 관리할 수 있지만, JPA의 지연 쓰기 특성상 플러시 시점에 주의해야 함