- 스택(Stack)과 큐(Queue)는 배열에서 발전된 형태의 선형 자료구조임
- 구조는 유사하지만 데이터를 처리하는 방식에서 근본적인 차이가 있음
- 단순 자료 저장을 넘어 실제 서비스 환경의 성능 최적화와 동시성 제어의 기초가 됨
주요 특징 비교
| 구분 | 스택 (Stack) | 큐 (Queue) |
|---|---|---|
| 구조 원칙 | 후입선출 (LIFO) | 선입선출 (FIFO) |
| 주요 연산 | push, pop, peek |
add/offer, poll, peek |
| 시간 복잡도 | 삽입/삭제 $O(1)$, 검색 $O(N)$ | 삽입/삭제 $O(1)$, 검색 $O(N)$ |
| 주요 용도 | DFS, 괄호 검사, 뒤로 가기 | BFS, 메시지 큐, 대기열 관리 |
문제 식별 방법
스택 (Stack)
- 가장 마지막에 들어온 데이터를 기준으로 후속 처리가 이루어지는 후입선출 상황임
- 괄호 쌍이나 문법 태그처럼 데이터 간의 대칭적인 유효성 검사가 필요한 경우임
- 실행 취소(Undo)나 재귀 구조의 명시적 관리가 요구되는 설계 환경임
- 배열 내에서 자신보다 크거나 작은 첫 번째 원소를 찾는 최적화(Monotonic Stack)가 필요한 상황임
큐 (Queue)
- 데이터가 들어온 순서 그대로 선순위 처리가 보장되어야 하는 선입선출 상황임
- 너비 우선 탐색(BFS)처럼 인접 노드를 먼저 순차적으로 방문해야 할 때임
- 데이터의 생성 속도와 소비 속도 차이를 조절하기 위한 버퍼 인터페이스가 필요한 경우임
- 프로세스 스케줄링이나 대기열 관리 등 순차적 자원 할당이 이루어지는 환경임
스택 (Stack)
- 삽입과 삭제 연산이 후입선출(LIFO, Last-In First-Out) 방식으로 이루어지는 구조임
- 데이터의 삽입과 삭제가 한쪽 끝에서만 일어나는 특징이 있음
1
2
3
4
5
6
7
8
9
Stack<Integer> stack = new Stack<>();
stack.push(1);
stack.push(2);
stack.push(3);
System.out.println("Top Element: " + stack.peek()); // 3
System.out.println("Pop Element: " + stack.pop()); // 3
System.out.println("Is Empty: " + stack.isEmpty()); // false
스택 용어 정리
- 위치
top- 삽입과 삭제가 일어나는 위치를 지칭함
- 연산
pushtop위치에 새로운 데이터를 삽입함
poptop위치에 있는 데이터를 삭제하고 확인함
peektop위치에 있는 데이터를 삭제하지 않고 단순 확인만 수행함

스택의 활용처와 패턴
- 주요 알고리즘 적용
- 깊이 우선 탐색(DFS, Depth First Search)의 기초 도구임
- 재귀 함수 알고리즘 원리와 일맥상통하여 백트래킹 종류의 문제 해결에 효과적임
- 모노토닉 스택 (Monotonic Stack)
- 스택 내부 원소들이 항상 오름차순 또는 내림차순을 유지하도록 관리하는 기법임
- 새로운 원소 삽입 시 규칙을 깨는 요소를 모두 제거하여 최적 상태를 유지함
- 자신보다 큰 첫 번째 원소 찾기 등의 문제를 $O(N^2)$에서 $O(N)$으로 최적화함
구현 방식과 성능 차이
- Java Legacy Stack (
java.util.Stack)Vector를 상속받아 모든 메서드에synchronized가 적용되어 있음- 단일 스레드 환경에서도 불필요한 락(Lock) 오버헤드가 발생하여 성능이 저하됨
- 실제 개발 환경에서는 사용을 권장하지 않음
- 현대적인 방식 (
ArrayDeque)- 동기화 오버헤드가 없으며 가변 배열을 사용하여 캐시 지역성이 뛰어남
- 스택 기능이 필요할 때 가장 우선적으로 고려되는 구현체임
큐 (Queue)
- 삽입과 삭제 연산이 선입선출(FIFO, First-In First-Out)로 이루어지는 자료구조임
- 먼저 들어온 데이터가 먼저 나가는 공평한 구조임
- 삽입과 삭제가 양방향에서 각각 독립적으로 수행됨
1
2
3
4
5
6
7
8
9
10
// Queue는 인터페이스이므로 LinkedList로 구현
Queue<Integer> queue = new LinkedList<>();
queue.add(1);
queue.add(2);
queue.add(3);
System.out.println("Front Element: " + queue.peek()); // 1
System.out.println("Poll Element: " + queue.poll()); // 1
System.out.println("Is Empty: " + queue.isEmpty()); // false
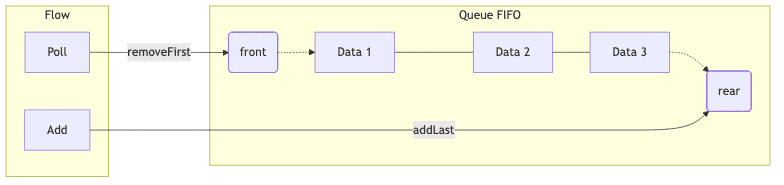
큐 용어 정리
- 위치
rear- 데이터가 삽입되는 가장 끝 영역임
front- 데이터가 삭제되는 가장 앞 영역임
- 연산
addrear부분에 새로운 데이터를 삽입함
pollfront부분에 있는 데이터를 삭제하고 확인함
peekfront부분에 있는 데이터를 확인만 수행함
큐의 활용처와 변형 구조
- 주요 알고리즘 적용
- 너비 우선 탐색(BFS, Breadth First Search)에서 경로 탐색 시 사용됨
- 대기열 처리나 프로세스 관리 등 순차적 처리가 필요한 영역에 적합함
- 원형 큐 (Circular Queue)
- 선형 큐에서 삭제 발생 시 공간이 낭비되는 문제를 해결하기 위한 구조임
- 배열의 끝이 시작과 연결되도록 나머지 연산(Modulo,
%)을 사용하여 인덱스를 순환시킴 - 고정된 배열 크기 내에서 빈 공간을 재활용하여 메모리 효율을 극대화함
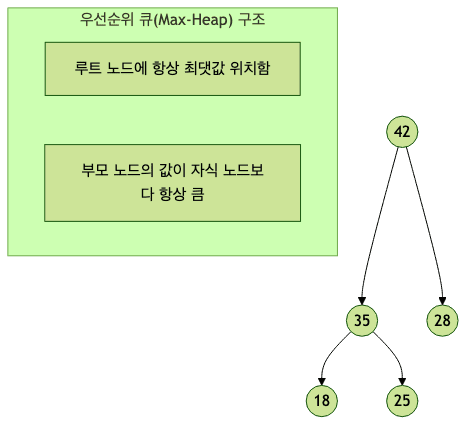
우선순위 큐 (Priority Queue)
- 값이 들어간 순서와 상관없이 우선순위가 높은 데이터가 먼저 나오는 특수한 구조임
- 큐 설정에 따라
front에 항상 최댓값 혹은 최솟값이 위치하도록 설계됨 -
내부적으로 힙(Heap) 자료구조를 이용하여 구현하며 삽입과 삭제에 $O(\log N)$이 소요됨
- 기본적으로 낮은 숫자가 우선순위를 갖는 최소 힙(Min Heap)으로 동작함
- 높은 숫자가 우선순위를 갖게 하려면
Collections.reverseOrder()를 사용해야 함
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
// 최소 힙 (기본) - 낮은 숫자가 우선
PriorityQueue<Integer> minHeap = new PriorityQueue<>();
minHeap.add(10);
minHeap.add(5);
minHeap.add(20);
System.out.println("Min Heap: " + minHeap.poll()); // 5 출력
// 최대 힙 - 높은 숫자가 우선
PriorityQueue<Integer> maxHeap = new PriorityQueue<>(Collections.reverseOrder());
maxHeap.add(10);
maxHeap.add(5);
maxHeap.add(20);
System.out.println("Max Heap: " + maxHeap.poll()); // 20 출력
// 절댓값 힙 - 절댓값이 낮은 숫자가 우선 (같으면 원래 숫자가 작은 순)
PriorityQueue<Integer> absHeap = new PriorityQueue<>((o1, o2) -> {
int abs1 = Math.abs(o1);
int abs2 = Math.abs(o2);
if (abs1 == abs2) return o1 - o2; // 절댓값이 같으면 원래 숫자 기준 오름차순
return abs1 - abs2; // 절댓값 기준 오름차순
});
absHeap.add(-10);
absHeap.add(5);
absHeap.add(-20);
System.out.println("Abs Heap: " + absHeap.poll()); // 5 출력
a
덱 (Deque)
- 덱(Double-Ended Queue)은 양쪽 끝에서 삽입과 삭제가 모두 가능한 자료구조임
- 스택과 큐의 장점을 결합하여 매우 유연하게 활용할 수 있음
- Java의
ArrayDeque가 대표적인 구현체이며 상황에 따라 스택 혹은 큐처럼 동작함 - 양쪽 끝에서 데이터 접근이 가능하므로 앞쪽(
First)과 뒤쪽(Last) 메서드를 구분해서 사용해야 함
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
// ArrayDeque 구현체 (일반적인 덱/스택/큐 연산 시 권장 - 속도 빠름)
Deque<Integer> arrayDeque = new ArrayDeque<>();
arrayDeque.offerLast(1);
arrayDeque.offerLast(2);
arrayDeque.offerLast(3);
System.out.println("ArrayDeque Poll: " + arrayDeque.pollFirst()); // 1 출력
// 덱의 양방향 활용
arrayDeque.offerFirst(100); // 앞쪽에 100 추가
arrayDeque.offerLast(200); // 뒤쪽에 200 추가
System.out.println("Front: " + arrayDeque.peekFirst()); // 100
System.out.println("Rear: " + arrayDeque.peekLast()); // 200
// LinkedList 구현체 (Deque 인터페이스 구현, 중간 삽입/삭제 시 유리)
Deque<Integer> linkedDeque = new LinkedList<>();
linkedDeque.offerFirst(10);
linkedDeque.offerLast(20);
System.out.println("LinkedList Poll: " + linkedDeque.pollFirst()); // 10 출력
// 사용법(메서드)은 동일함 (인터페이스가 Deque이므로)
// 덱을 스택처럼 사용할 경우 push(), pop()
// 덱을 큐처럼 사용할 경우 offer(), poll()
arrayDeque.push(100);
linkedDeque.push(100);
System.out.println("ArrayDeque Top: " + arrayDeque.peek()); // 100
System.out.println("LinkedList Top: " + linkedDeque.peek()); // 100

실제 서비스 환경의 활용
- 메시지 큐 (Queue)
- Kafka, RabbitMQ 등에서 서버 간 비동기 통신 시 버퍼 역할을 수행함
- 트래픽 폭주 시 데이터를 순서대로 안전하게 처리하여 안정성을 보장함
- 작업 큐와 프로세스 관리
- WAS(Tomcat 등)에서 들어오는 요청을 작업 큐에 쌓아두고 스레드 풀이 처리함
- JVM 스택 메모리
- 메서드 호출 시마다 로컬 변수와 매개변수가 스택 프레임에 쌓였다가 종료 시 제거됨
JVM 스택 프레임 동작 시퀀스

- 편집기 및 브라우저
- 실행 취소 및 뒤로 가기 기능에서 행동 이력을 스택으로 관리함
- 동시성 제어
- 생산자-소비자 패턴에서 블로킹 큐(BlockingQueue)를 활용하여 스레드를 대기시킴