- 💡해당 게시글은 최범균님의 ‘주니어 백엔드 개발자가 반드시 알아야 할 실무 지식’을 개인 공부목적으로 메모하였습니다.
7장에서 다루는 내용
- 네트워크 IO와 CPU
- 가상 스레드
- 논블로킹 I/O
네트워크 I/O와 블로킹 문제
서버의 네트워크 통신 구조
- 서버는 프로그램의 기본으로 네트워크 프로그래밍이 핵심임
-
클라이언트와 구성 요소 간 통신에 소켓과 네트워크를 사용함
-
서버 구조
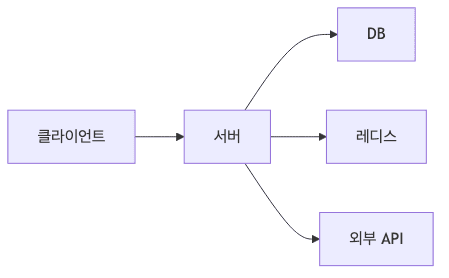
- 서버는 여러 구성 요소와 통신하며 데이터를 주고받음
- DB는 TCP 기반 프로토콜을 사용하여 데이터 전송
- 레디스와 외부 API 통신도 모두 네트워크를 통해 이루어짐
네트워크 I/O와 데이터 전송
- 네트워크를 통한 데이터 전송은 시간이 소요됨
- 데이터 처리를 위해서는 입출력 스트림 필요
1
2
3
4
5
6
7
// 데이터 전송 (write)
OutputStream out = socket.getOutputStream();
out.write(requestData);
// 데이터 수신 (read)
InputStream in = socket.getInputStream();
int len = in.read(responseBuffer);
블로킹 I/O의 개념과 동작
- 입출력 완료 때까지 스레드가 대기하는 것을 블로킹이라고 함
-
DB에 SELECT 쿼리를 실행하면 결과를 반환하기까지 서버는 대기함
-
스레드 상태 변화

- 입출력 완료를 기다리는 동안 스레드는 블로킹됨
- 블로킹 중인 스레드는 CPU를 거의 사용하지 않아 자원 낭비 발생
블로킹 I/O의 성능 문제
- CPU 사용률을 높이려면 CPU가 실행할 스레드를 많이 만들어야 함
-
요청당 스레드 방식으로 구현하면 CPU 낭비가 발생할 수 있음
- 메모리 문제
- 각 스레드는 메모리를 차지함 (플랫폼 스레드는 최소 1MB 이상)
- 블로킹된 스레드가 많아지면 메모리 낭비 발생
- 동시에 실행되는 스레드가 증가하면 컨텍스트 스위칭 비용 증가
- 컨텍스트 스위칭
- 운영 체제가 여러 스레드를 번갈아 가며 CPU에서 실행시킴
- 스레드를 전환할 때마다 CPU는 현재 실행 중인 스레드의 상태를 저장하고 다음 스레드의 상태를 복원함
- 컨텍스트 스위칭 자체가 CPU 자원을 소모함
가상 스레드
가상 스레드란?
- I/O 작업의 대기 시간이 많은 경우 CPU 낭비 발생
- 입출력 동안 스레드가 대기하므로 CPU가 유휴 상태에 놓임
- 가상 스레드를 사용하면 I/O 대기 중에도 다른 작업 수행 가능
스케줄링 메커니즘
- 가상 스레드는 경량형 스레드로 플랫폼 스레드보다 적은 자원을 사용함
- 운영 체제 수준의 플랫폼 스레드(OS 스레드)보다 JVM이 관리하는 경량 스레드임
-
여러 OS가 CPU로 실행할 스레드를 스케줄링하듯, JVM이 플랫폼 스레드에 여러 가상 스레드를 번갈아 실행함
-
가상 스레드 스케줄링
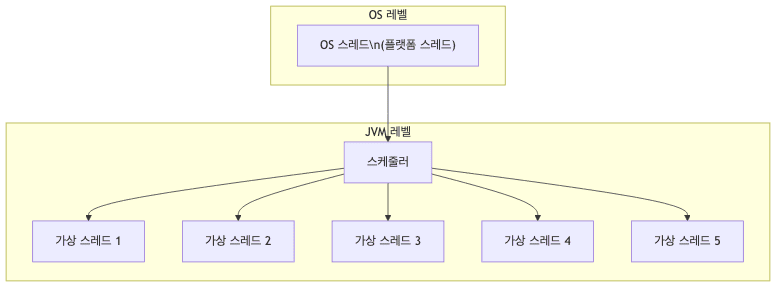
- JVM은 가상 스레드를 스케줄링함
- CPU 코어 개수만큼(또는 조금 더 많이) 캐리어 스레드를 생성함
-
가상 스레드는 캐리어 스레드 위에서 실행되며, IO 블로킹 시 다른 가상 스레드로 전환됨
-
언마운트 메커니즘
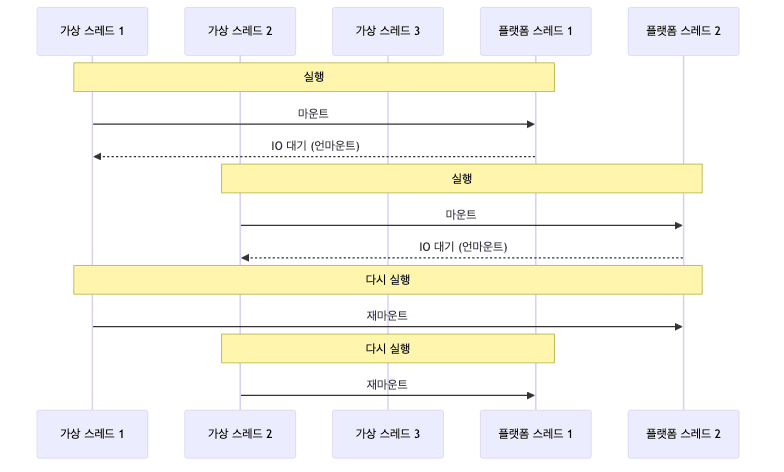
- 가상 스레드가 블로킹되면 플랫폼 스레드와 언마운트됨
- 언마운트된 플랫폼 스레드는 실행할 다른 가상 스레드를 찾아 실행함
- 이런 방식으로 플랫폼 스레드 2~3개로 수많은 가상 스레드를 실행할 수 있음
메모리 효율성
- 가상 스레드는 약 4KB에서 수십 KB 정도의 메모리만 사용함
- 플랫폼 스레드는 최소 1MB 이상의 스택 메모리를 사용함
- Go 언어의 고루틴도 유사한 메모리 효율을 가짐
사용법
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
// 가상 스레드 50개 생성 및 실행
int threadCount = 50;
Thread[] workers = new Thread[threadCount];
long startTime = System.currentTimeMillis();
for (int i = 0; i < threadCount; i++) {
workers[i] = Thread.ofVirtual().start(() -> {
try {
// IO 대기 시뮬레이션
Thread.sleep(2000);
} catch (InterruptedException ex) {
Thread.currentThread().interrupt();
}
});
}
// 모든 스레드 완료 대기
for (Thread worker : workers) {
try {
worker.join();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
long elapsed = System.currentTimeMillis() - startTime;
System.out.println("소요 시간: " + elapsed + "ms");
- 실행 결과
- 플랫폼 스레드
- 약 21,500ms
- 가상 스레드
- 약 2,000ms
- 플랫폼 스레드
성능 특성
- IO 중심 작업에 효과적
- IO 대기 시간이 긴 작업에서 가장 효과적임
- 트래픽이 많아서 동시에 100~1000개 이상의 요청을 처리해야 하는 경우 유리함
- 같은 CPU와 메모리 서버라면 더 많은 처리량을 달성할 수 있음
- CPU 중심 작업에는 부적합
- CPU 중심 작업에 가상 스레드를 사용하면 성능 개선 효과를 얻을 수 없음
- 오히려 성능이 나빠질 수 있음
- 이미지 처리나 복잡한 알고리즘 실행 같은 작업이 여기에 해당함
주의사항
-
synchronized와 pinned 상태 (Java 21)
-
피해야 할 패턴
1 2 3 4 5
Object lock = new Object(); synchronized (lock) { Thread.sleep(1000); // 가상 스레드가 pinned 상태가 되어 캐리어 스레드까지 블로킹 }
-
권장 패턴
1 2 3 4 5 6 7 8
// ReentrantLock 사용 ReentrantLock lock = new ReentrantLock(); lock.lock(); try { Thread.sleep(1000); // 가상 스레드만 블로킹, 캐리어 해제 } finally { lock.unlock(); }
- 블로킹된 연산에는
ReentrantLock,Thread.sleep()등이 포함됨 - Java 21 기준으로
synchronized블록 안에서는 가상 스레드가 언마운트되지 않음 (pinned 상태) - 가상 스레드가 고정(pinned)되면 CPU 효율을 높일 수 없으므로
ReentrantLock사용 권장
- 블로킹된 연산에는
-
- 스레드 풀 불필요
- 가상 스레드는 생성 비용이 적어 스레드 풀을 미리 구성할 필요 없음
- 필요한 시점에 생성하고 완료되면 제거하면 됨
- ThreadLocal 사용 최소화
- 가상 스레드 수가 많아지면 ThreadLocal 메모리 사용량 급증
- 대안
- ScopedValue (Java 21+) 사용 검토
논블로킹 I/O
논블로킹 I/O의 필요성
- 가상 스레드와 같은 경량 스레드를 사용해도 메모리와 스케줄링 비용이 발생함
- 경량 스레드가 많아질수록 더 많은 메모리를 사용하고 스케줄링에 더 많은 시간 소비
- 논블로킹 I/O는 Nginx, Netty, Node.js 등 고성능 서버에서 사용하는 방식임
동작 방식
- 논블로킹 I/O는 입출력이 끝날 때까지 스레드가 대기하지 않음
- 읽을 데이터가 없어도 즉시 리턴함
- 의사 코드
1 2 3 4
// 논블로킹 채널의 동작 방식 channel.configureBlocking(false); int readBytes = channel.read(buffer); // 읽을 데이터가 없으면 즉시 0 리턴 (블로킹하지 않음)
Selector 패턴
- 단순 반복문으로 논블로킹 I/O를 처리하면 busy-wait으로 CPU 낭비가 심함
Selector를 사용하면 IO 가능한 이벤트가 발생할 때까지 효율적으로 대기 가능
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
Selector sel = Selector.open();
ServerSocketChannel server = ServerSocketChannel.open();
server.bind(new InetSocketAddress(8080));
server.configureBlocking(false);
server.register(sel, SelectionKey.OP_ACCEPT);
while (true) {
sel.select(); // IO 가능한 이벤트가 발생할 때까지 대기
Iterator<SelectionKey> iter = sel.selectedKeys().iterator();
while (iter.hasNext()) {
SelectionKey key = iter.next();
iter.remove();
if (key.isAcceptable()) {
// 클라이언트 연결 수락
SocketChannel client = server.accept();
client.configureBlocking(false);
client.register(sel, SelectionKey.OP_READ);
} else if (key.isReadable()) {
// 데이터 읽기
SocketChannel client = (SocketChannel) key.channel();
ByteBuffer buf = ByteBuffer.allocate(1024);
int bytesRead = client.read(buf);
if (bytesRead > 0) {
buf.flip();
// 데이터 처리 로직
} else if (bytesRead < 0) {
// 클라이언트 연결 종료
key.cancel();
client.close();
}
// bytesRead == 0: 읽을 데이터 없음, 다음 이벤트 대기
}
}
}
- IO 멀티플렉싱
- 하나의 이벤트 루프에서 여러 IO 작업을 처리하는 개념
- OS에 따라
epoll(리눅스),IOCP(윈도우) 등을 사용해서 구현
리액터 패턴
- 리액터(reactor) 패턴은 논블로킹 I/O 구현에 사용하는 대표적인 패턴임
- 리액터와 핸들러 두 요소로 구성되며, 이벤트 발생 시 적절한 핸들러를 찾아 처리함
-
의사 코드
1 2 3 4 5 6 7 8 9
// 리액터 패턴의 기본 구조 while (isRunning) { List<Event> events = getEvents(); // 이벤트 발생 대기 for (Event event : events) { Handler handler = getHandler(event); // 적절한 핸들러 선택 handler.handle(event); // 이벤트 처리 } }
- Netty, Nginx, Node.js 등이 이 패턴을 따르며, 이벤트 루프(event loop)라고도 함
동시성 높이기
- 논블로킹 I/O를 1개 스레드로 구현하면 동시성이 떨어짐
-
채널들을 N개 그룹으로 나누고 각 그룹마다 스레드를 할당하여 동시성을 높임
- 스레드 분배 방식
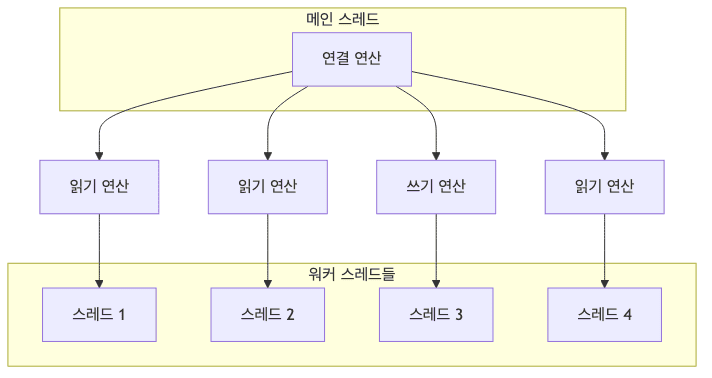
- 보통 CPU 개수만큼 그룹을 나누고 각 그룹마다 입출력을 처리할 스레드를 할당함
프레임워크 활용
- 논블로킹 I/O를 직접 구현하면 버퍼 관리, 개행 문자 처리 등이 복잡해짐
- Netty, Vert.x 등의 프레임워크가 논블로킹 I/O를 보다 쉽게 구현할 수 있도록 도와줌
성능 비교
- 블로킹 I/O vs 논블로킹 I/O (JVM 힙 메모리 1.5G 기준)
- 블로킹 I/O
- 최대 동접수 약 6천
- 논블로킹 I/O
- 최대 동접수 약 12만 (약 20배 성능 향상)
- 블로킹 I/O
언제 어떤 방법을 택할까
선택 기준
-
논블로킹 I/O나 가상 스레드 적용 시 다음을 고려해야 함
-
고려사항
- 성능 문제가 있는가?
- 문제가 있다면 네트워크 IO 관련 성능 문제인가?
- 구현 복잡도를 감당할 수 있는가?
선택 가이드
- 가장 먼저 검토해야 할 점은 성능 문제가 있는지 여부
- 문제가 없다면 새로운 기술을 쓸 필요가 없음
-
문제가 있다면 우선 순위와 구현 복잡도를 고려해야 함
- 기술 선택 플로우차트
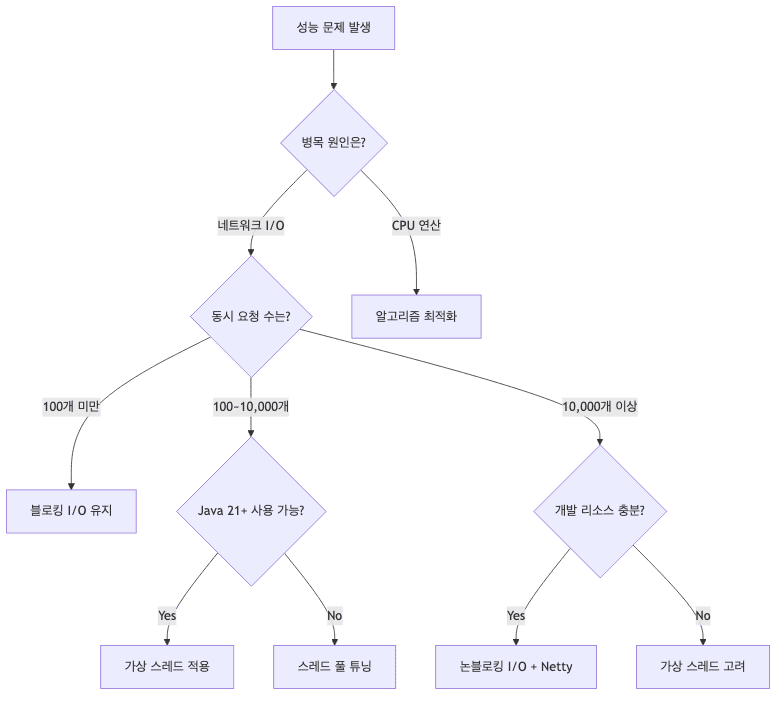
배운 점
- 블로킹 I/O는 스레드 대기 중 CPU가 유휴 상태가 되어 자원 낭비됨
- 가상 스레드는 기존 코드 변경 최소화하면서 성능 개선 가능
- 논블로킹 I/O는 최고 성능을 제공하지만 구현 복잡도 증가
- 성능 문제 여부를 측정 가능한 지표로 먼저 확인해야 함