- 💡해당 게시글은 최범균님의 ‘주니어 백엔드 개발자가 반드시 알아야 할 실무 지식’을 개인 공부목적으로 메모하였습니다.
9장에서 다루는 내용
- 개발자와 서버
- OS 계정과 권한
- 프로세스 관리
- 디스크 용량 관리
- 파일 디스크립터 제한
- 시간 맞추기
- 크론으로 스케줄링하기
- alias 등록하기
- 네트워크 정보 확인
개발자와 서버
서버와 OS의 관계
- 서버는 다양한 태스크를 수행하며, OS는 이를 관리하고 제어함
- 인프라 엔지니어가 아니더라도 백엔드 개발자라면 기본적인 서버 관리 능력이 필요함
가상화 기술
- VirtualBox, Vagrant
- 서버 관리의 베이스 환경 제공
- 실제 컴퓨터를 사서 작업할 필요 없이 OS 테스트 가능
OS 계정과 권한
OS 계정의 개념
- 서버 프로그램의 프로세스는 누가 실행했는지에 따라 프로세스가 구동될 수 있는 권한이 결정됨
root 계정
- 최고 관리자 권한을 가진 계정
- 모든 파일과 프로세스에 접근 가능
- root 계정으로 프로세스 실행 시 파일 수정 권한 확보
- 보안상 위험하므로 일반 계정 사용 권장
일반 사용자 계정
- 제한된 권한을 가짐
- 자신의 파일만 수정 가능
- 특정 디렉토리 외 시스템 파일 접근 제한
파일 권한 확인
1
2
$ ./run.sh
-bash: ./run.sh: Permission denied
-
권한 표기법
1 2
-rwxr--r--. 1 username groupname 1024 Jan 15 10:30 README.md -rwxr-----. 1 username groupname 2048 Jan 15 10:35 script.sh
구분 설명 r (Read) 읽기 권한 (4) w (Write) 쓰기 권한 (2) x (eXecute) 실행 권한 (1) -
권한 구조
- 소유자 권한 (rwx)
- 그룹 권한 (r–)
- 다른 계정 권한 (r–)
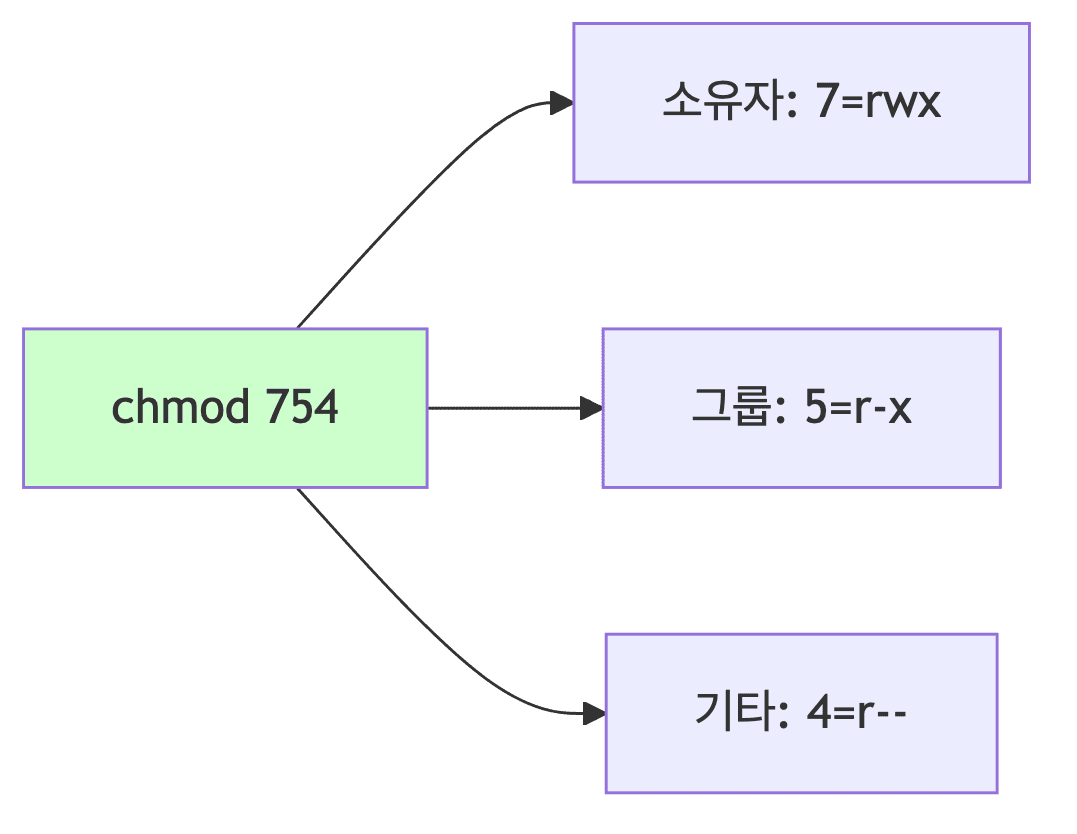
chmod - 권한 변경
1
2
# 숫자로 권한 변경
$ chmod 754 run.sh
- 7 (4+2+1)
- 소유자는 읽기, 쓰기, 실행 가능
- 5 (4+1)
- 그룹은 읽기, 실행만 가능
- 4
- 다른 계정은 읽기만 가능
1
2
# 기호로 권한 변경
$ chmod u+x run.sh # 소유자에게 실행 권한 추가
sudo 명령어
- 일반 사용자가 임시로 root 권한으로 명령 실행
-
개발자도 root 권한 필요 시 사용 가능
- sudo 설정
/etc/sudoers파일에서 권한 관리visudo명령으로 편집 가능- 설정 형식
1 2 3 4 5 6 7 8 9 10 11 12
# 사용자에게 모든 명령을 비밀번호 없이 허용 username ALL=(ALL) NOPASSWD: ALL # 사용자에게 모든 명령을 허용 (비밀번호 필요) username ALL=(ALL) ALL # 특정 명령어만 비밀번호 없이 허용 username ALL=(ALL) NOPASSWD: /usr/bin/systemctl, /usr/bin/apt-get # 그룹 단위로 권한 부여 (% 기호 사용) %sudo ALL=(ALL:ALL) ALL %admin ALL=(ALL) NOPASSWD: /usr/bin/systemctl restart *
사용자명(또는 %그룹명) 호스트=(실행사용자) 명령어ALL은 모든 것을 의미NOPASSWD:는 비밀번호 입력 생략
-
sudo 사용 예시
1 2
$ sudo systemctl start docker $ sudo systemctl stop docker
- NOPASSWD 옵션
1 2 3 4 5 6 7
# NOPASSWD 설정된 사용자는 비밀번호 입력 없이 실행 $ sudo apt-get update $ sudo systemctl restart nginx # NOPASSWD 설정되지 않은 사용자는 비밀번호 입력 필요 $ sudo systemctl restart nginx [sudo] password for username:
- 비밀번호 입력 없이 sudo 실행 가능
- 보안 주의
- root 권한과 유사하므로 신중하게 설정
프로세스
프로세스 확인하기
-
ps 명령어
1
$ ps aux- 실행 중인 모든 프로세스 확인
- 프로세스 ID, 소유자, CPU/메모리 사용량 등 표시
1
$ ps aux --sort -rss | head -n 6
- 메모리 사용량 순으로 정렬하여 상위 6개 표시
-
htop 명령어
- 실시간 프로세스 모니터링 도구
- CPU, 메모리 사용량을 시각적으로 표시
- top보다 사용하기 편리
프로세스 종료
-
kill 명령어
1
$ kill [옵션] PID
- 주요 시그널
-15(SIGTERM)- 정상 종료 요청 (기본값)
-9(SIGKILL)- 강제 종료
-
사용 예시
1 2
$ kill 옵션 PID # SIGTERM으로 정상 종료 시도 $ kill -9 옵션 PID # 강제 종료
- 주요 시그널
백그라운드 프로세스
-
기본적으로 포그라운드 실행
- 백그라운드 실행
1
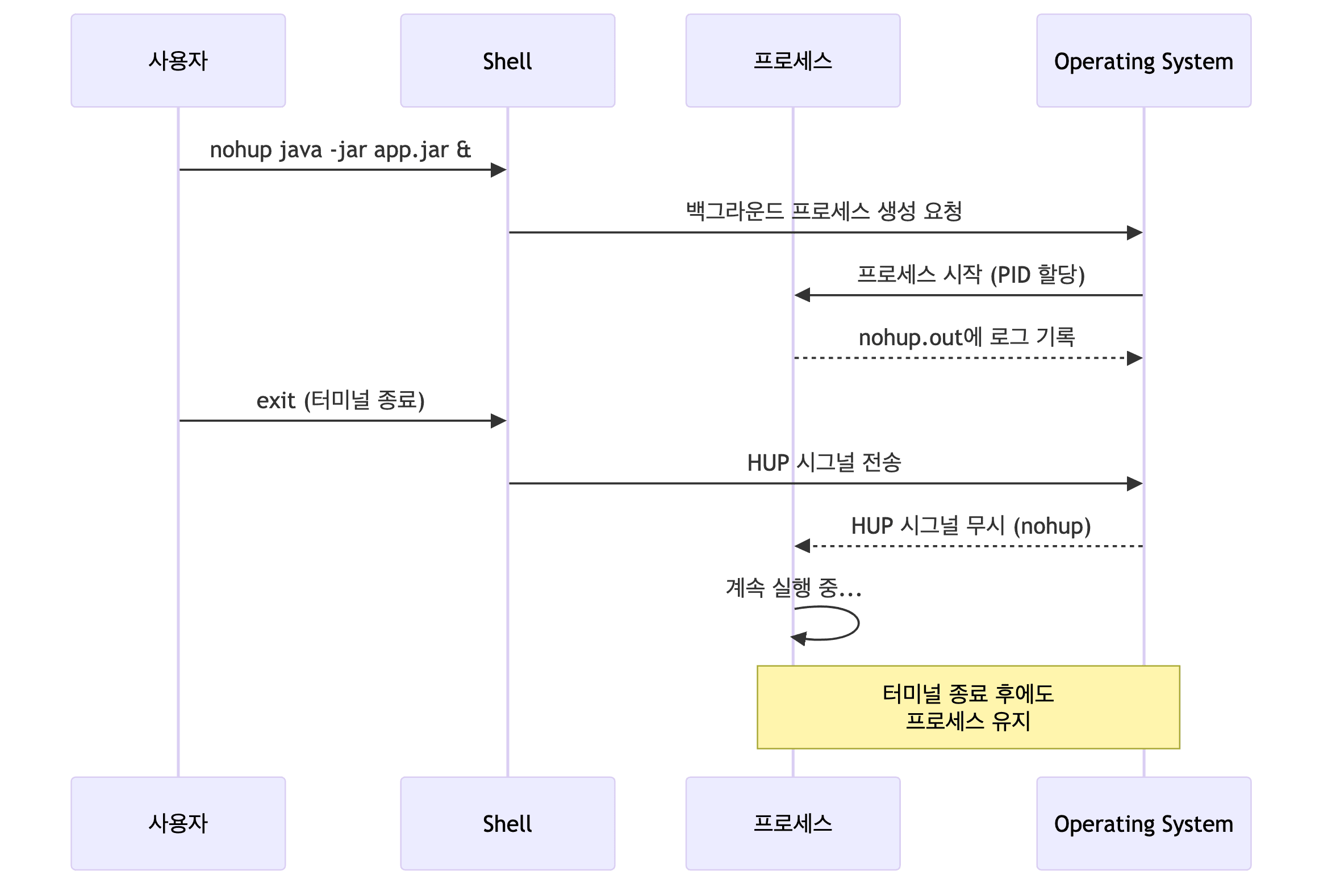
$ java -jar application.jar &
&를 뒤에 붙임- 터미널을 종료하면 프로세스가 유지되지 않음
-
nohup 명령어
1 2 3
$ nohup java -jar application.jar & [1] 12345 nohup: ignoring input and appending output to 'nohup.out'
- nohup의 특징
- No Hang Up
- 터미널 연결이 끊겨도 프로세스 유지
- 출력을
nohup.out파일에 기록 - HUP 시그널 무시
- No Hang Up
- nohup의 특징
-
로그 리다이렉션
1
$ nohup java -jar application.jar > app.log 2>&1 &
>- 표준 출력을 server.log로 리다이렉션
2>&1- 표준 에러도 표준 출력으로 합침
2>&1의 의미
- 리눅스 파일 디스크립터
2- 표준 에러 (stderr)
1- 표준 출력 (stdout)
&1- 파일 디스크립터 1을 의미
- 표준 에러를 표준 출력과 동일한 곳으로 보냄
nohup 프로세스 흐름
디스크 용량 관리
디스크 용량의 중요성
- 예전에는 디스크가 100% 차면 시스템 먹통
- 현대 OS는 일부 작업이 가능하지만 성능 저하
- 서버 모니터링 도구로 디스크 사용률 80% 넘기면 경고/알림 설정 필요
디스크 확인 명령어
-
df 명령어
1
$ df -h
- Disk Free
- 파일 시스템의 전체 용량과 사용량 표시
-h- human-readable (사람이 읽기 쉬운 형식)
1 2 3
Filesystem Size Used Avail Use% Mounted on /dev/sda1 100G 45G 50G 47% / /dev/sdb1 500G 320G 180G 64% /data
- Disk Free
-
du 명령어
1
$ du -sh /*
- Disk Usage
- 디렉토리나 파일의 용량 확인
-s- 요약 (summary)
-h- human-readable
1 2 3 4
24K ./project1 1.2M ./project2 48K ./backup 256K ./archive.tar.gz
- Disk Usage
용량 단위
- 바이트 단위
- K, M, G 사용
-h옵션- 자동으로 적절한 단위 표시 (MB, GB 등)
로그 파일 관리
- 로그 파일의 중요성
- 클라우드 환경에서 로그는 매우 중요한 파일
- 로그 파일이 쌓여 디스크가 꽉 차는 경우 많음
-
로그 관리 방법
- 로그 파일 위치 확인
- 일반적으로 서버 프로그램의 디스크 용량 관리 파일은 2가지
- 로그 파일
- 파일 저장(임시 파일 등)
- 일반적으로 서버 프로그램의 디스크 용량 관리 파일은 2가지
- 로그 남기는 방법
- 로그를 남기는 디렉토리가 많은 용량을 차지하는지 확인해야 함
1 2
$ cd /var/log $ du -sh *
- 로그 파일 압축/삭제
- 오래된 로그 파일은 압축하거나 삭제
- 로그 로테이션
- 일정 크기/날짜 기준으로 로그 파일 교체
- 로그 파일 위치 확인
-
find 명령으로 오래된 파일 삭제
1
$ find ./logs -mtime +29 -type f -delete
-mtime +29- 29일 이상 된 파일
-type f- 파일만 대상
-delete- 삭제 (주의:
-exec rm사용 가능)
- 삭제 (주의:
디렉토리별 용량 관리
- 한 디렉토리에 파일이 너무 많으면 속도 저하
- 시간별/날짜별 디렉토리 분리 권장
- ex)
/files/YYYY/MM/DD/형식으로 저장
로그 파일 크기 제한
- 로그 파일 주의사항
- 로그 파일이 커지면 디스크 공간 부족 발생
- 심각한 경우 95% 넘게 차면 삭제 수동 처리 필요
-
/dev/null 활용
1
$ cp /dev/null out.log
/dev/null- 널(null) 장치 파일
- 이 장치에 쓰는 데이터는 모두 버려짐
- 로그 파일을 빠르게 비울 때 유용
- 로그 파일 관리 팁
- 로그 로테이션 설정 필수
- 오래된 로그는 자동으로 삭제/압축
- 서비스 중요도에 따른 로그 관리 수준 조정
파일 디스크립터 제한
파일 디스크립터란?
- 프로세스가 데이터 입출력 때 OS로부터 파일 디스크립터 ID를 할당받음
- OS는 사용자나 시스템 수준에서 프로세스 제한 설정
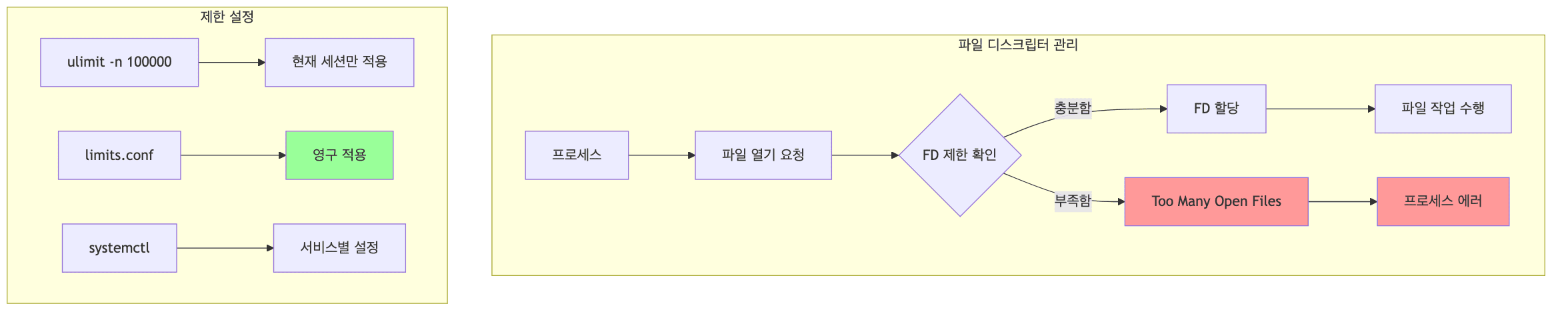
파일 디스크립터 제한 확인
-
ulimit 명령어
1
$ ulimit -a
-
주요 항목
1 2 3 4 5 6 7 8 9 10 11 12
real-time non-blocking time (microseconds, -R) unlimited core file size (blocks, -c) 0 data seg size (kbytes, -d) unlimited scheduling priority (-e) 0 file size (blocks, -f) unlimited pending signals (-i) 62780 max locked memory (kbytes, -l) 8192 max memory size (kbytes, -m) unlimited open files (-n) 1024 pipe size (512 bytes, -p) 8 POSIX message queues (bytes, -q) 819200 real-time priority (-r) 0
-
-
open files 제한
- 기본적으로 1024개로 제한됨
- “Too Many Open Files” 에러 발생 가능
파일 디스크립터 제한 변경
-
임시 변경 (ulimit)
1
$ ulimit -n 100000
- 현재 세션에만 적용
- 재접속 시 원래 값으로 복구
-
영구 변경 (/etc/security/limits.conf)
1 2 3
$ cat /etc/security/limits.conf * soft nofile 100000 * hard nofile 100000
soft- 경고 수준 (사용자가 변경 가능)
hard- 최대 제한 (사용자가 변경 불가)
-
nofile vs NOFILE
nofile- 파일 디스크립터 개수 제한
- soft와 hard 각각 설정 가능
systemd 설정
-
systemd로 실행되는 서비스
1 2
$ systemctl show -p DefaultLimitNOFILE DefaultLimitNOFILE=524288
-
서비스 파일에서 설정
1 2
[Service] LimitNOFILE=1048576
-
-
설정 변경 절차
/etc/systemd/system.conf또는 개별 서비스 파일 수정systemctl daemon-reload실행- 서비스 재시작
/etc/sysctl.conf 설정
-
fs.file-max
1 2
$ cat /proc/sys/fs/file-max fs.file-max=1048576
1 2
$ sysctl fs.file-max fs.file-max = 9223372036854775807
- 시스템 전체 파일 디스크립터 제한
sysctl -p명령으로 적용
실제 프로세스 사용 중인 파일 확인
1
2
$ lsof -p 프로세스ID
$ lsof -p 프로세스ID | wc -l
vi 에디터 팁
- 편집기 치환 명령 등으로 여러 파일을 한꺼번에 열면 파일 디스크립터 소진 가능
- 리눅스 서버에서는 파일 디스크립터를 초과하지 않도록 주의
시간 맞추기
서버 시간의 중요성
- 컴퓨터는 시간 동기화가 필수
- 각 시스템 간 시간 차이 발생 시 문제 발생
시간 오차의 영향
- 타임스탬프 생성 시 문제 발생
- 서버 시간이 어긋나면 타임스탬프 기록 오류
시간 동기화 방법
- chrony / ntp
- 시간을 동기화하는 서비스
- 지속적으로 시간 동기화 유지
크론으로 스케줄링하기
크론(Cron)이란?
- 서버를 운영하면 일정 시간마다 해야 할 작업 존재
- 크론은 리눅스를 포함한 유닉스 계열 OS의 시간 기반 스케줄러
크론 사용 예시
- 매일 0시 5분에 90일 이상된 로그 파일 삭제
- 매일 0시 10분에 10일 이상된 로그 파일 압축
- 매주 일요일 4시에 DB를 풀백업
- 매주 일요일 6시에 DB 백업 파일을 S3에 업로드
크론 설정
-
crontab 명령어
1
$ crontab -l
-l- 현재 설정된 크론 작업 목록 확인
1 2
0 1 * * * /opt/scripts/database-backup.sh 0 4 * * * /opt/scripts/cleanup-logs.sh
-
크론 작업 추가/수정
1
$ crontab -e
크론 표현식
-
기본 구조
1
* * * * * 명령어
- 각 필드 의미
- 분 (0-59)
- 시 (0-23)
- 일 (1-31)
- 월 (1-12)
- 요일 (0-7, 0과 7은 일요일)
- 각 필드 의미
-
크론 예시
0 0 * * *- 매일 0시 0분에
30 1 1 * *- 매월 1일 1시 30분에
5 4 * * 0- 매주 일요일 4시 5분에
- 콤마로 구분하여 개별 값 지정
0 1,2,3 * * *- 매일 1시, 2시, 3시 0분에
0,30 5 * * *- 매일 5시 0분, 5시 30분에
- 구간을 지정할 때는 ‘값1-값2’ 형식
30 1-3 * * *- 매일 1시에서 3시 매시 30분에(즉 1시 30분, 2시 30분, 3시 30분)
- 슬래시(/)를 이용해서 시간 간격을 지정
*/10 1 * * *- 매일 1시에 0분부터 1시 50분까지 10분 간격으로 실행
0 */2 * * *- 0시부터 2시간 간격으로 0분에 실행
크론 실행 결과 확인
-
로그 확인
1 2
$ crontab -l 0 4 * * * /opt/scripts/backup.sh > /var/log/backup.log 2>&1
- 크론으로 실행한 명령어의 표준 출력을 별도 파일에 남기기 권장
크론 관련 팁
- cron.deny vs cron.allow
cron.deny- 크론 사용을 거부할 사용자 목록
cron.allow- 크론 사용을 허용할 사용자 목록
- at 명령어
- 일회성 작업 스케줄링 가능
- cron과 달리 지정한 일시에 한 번만 실행
alias 등록하기
alias란?
- 서버를 운영하다 보면 자주 사용하는 명령어가 생김
- 로그를 보기 위해 특정 디렉토리로 이동하는 명령어 등
- 이런 명령어를 간결하게 등록하는 것이 alias
alias 사용법
-
alias 설정
1
$ alias cdlog='cd /var/log'
-
alias 확인
1 2 3 4 5 6 7 8
$ alias alias cdlog='cd /var/log' alias egrep='egrep --color=auto' alias fgrep='fgrep --color=auto' alias grep='grep --color=auto' alias l.='ls -d .* --color=auto' alias ll='ls -l --color=auto' alias ls='ls --color=auto'
alias 영구 등록
-
.bashrc 파일
1 2 3 4 5 6 7 8
# .bashrc # Source global definitions if [ -f /etc/bashrc ]; then . /etc/bashrc fi # alias alias cdlog='cd /var/log'
-
.bash_profile vs .bashrc
- .bash_profile
- 사용자 로그인 시 1회 실행
- PATH 같은 환경 변수 설정에 적합
- .bashrc
- 새로운 bash 셸을 시작할 때마다 실행
- alias 설정에 적합
-
.bash_profile에서 .bashrc 실행
1 2 3
if [ -f ~/.bashrc ]; then . ~/.bashrc fi
- .bash_profile
주의사항
- alias를 정의한 후에는
source ~/.bashrc실행하거나 재접속 필요
네트워크 정보 확인
서버 네트워크 관리의 중요성
- 서버를 운영하다 보면 네트워크 연결 정보를 확인해야 할 때 있음
- 이 절에서는 네트워크 관련 명령어와 사용법 소개
IP 정보 확인하기
-
ifconfig 명령어
1
$ ifconfig-
출력 정보
1 2 3 4 5 6 7 8 9 10 11 12
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.1.100 netmask 255.255.255.0 broadcast 192.168.1.255 inet6 fe80::a1b2:c3d4:e5f6:7890 prefixlen 64 scopeid 0x20<link> ether aa:bb:cc:dd:ee:ff txqueuelen 1000 (Ethernet) RX packets 123456 bytes 98765432 (98.7 MB) TX packets 45678 bytes 12345678 (12.3 MB) lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536 inet 127.0.0.1 netmask 255.0.0.0 inet6 ::1 prefixlen 128 scopeid 0x10<host> RX packets 1234 bytes 123456 (123.4 KB) TX packets 1234 bytes 123456 (123.4 KB) -
주요 항목
- IP 주소(inet)
- 192.168.1.100
- IPv6 주소(inet6)
- fe80::a1b2:c3d4:e5f6:7890
- MAC 주소(ether)
- aa:bb:cc:dd:ee:ff
- RX/TX
- 수신/송신 패킷 바이트 크기
- IP 주소(inet)
-
nc 명령으로 연결 확인하기
-
nc (netcat) 기본 사용
1 2 3 4
$ nc -z -v example.com 443 Ncat: Version 7.92 ( https://nmap.org/ncat ) Ncat: Connected to 93.184.216.34:443. Ncat: 0 bytes sent, 0 bytes received in 0.05 seconds.
-z- 연결만 확인 (데이터 전송 안 함)
-v- 자세한 정보 출력
-
UDP 포트 확인
1 2 3 4 5
$ nc -z -u -v localhost 8080 Ncat: Version 7.92 ( https://nmap.org/ncat ) Ncat: Connected to ::1:8080. Ncat: UDP packet sent successfully Ncat: 1 bytes sent, 0 bytes received in 2.00 seconds.
-u- UDP 소켓 사용
-
curl로 API 실행하기
- nc와 같은 도구나 wget을 사용해도 되지만, curl이나 wget을 사용하면 더욱 편리
- HTTP POST 요청을 보내거나 GET이나 POST 요청을 사용할 수 있음
netstat 명령으로 포트 사용 확인
-
netstat 기본 사용
1
$ netstat -lnptu
-l- 리스닝 서버 소켓 출력
-n- 숫자로 포트 번호 표시 (서비스명 대신)
-p- 소켓을 사용하는 PID/프로그램 이름 출력
-t- TCP 소켓 출력
-u- UDP 소켓 출력
-
netstat 출력 예시
1 2 3 4 5 6
$ netstat -lnptu Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 1234/master tcp 0 0 127.0.0.1:3306 0.0.0.0:* LISTEN 5678/mysqld tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 9012/nginx ...
-
netstat -anp 사용
1
$ netstat -anp | grep 8080
-a- 모든 소켓 표시
- grep과 함께 사용하여 현재 사용 중인 포트를 확인할 수 있음
포트 충돌
- 포트 사용 관련 주의사항
- 이미 포트가 사용 중이라면 오류 메시지나 netstat으로 확인
- 특정 서버가 9,999번 이하만 사용한다면 클라우드 인스턴스 소켓 충돌 가능
- 클라우드 인스턴스가 소켓을 사용하는 포트 범위는 좁으므로 충돌 방지 가능
배운 점
- 가장 기본적인 서버 관리는 OS 계정과 권한을 올바르게 이해하고 사용하는 것임
- 프로세스 관리(ps, htop, kill, nohup)는 서버 운영의 기본임
- 디스크 용량 관리를 소홀히 하면 시스템 장애로 이어질 수 있음
- 파일 디스크립터 제한을 적절히 설정하지 않으면 “Too Many Open Files” 에러 발생
- 크론을 이용하면 정기적인 작업을 자동화할 수 있음
- alias를 활용하면 자주 사용하는 명령어를 효율적으로 관리할 수 있음
- 네트워크 명령어(ifconfig, nc, netstat)로 서버의 네트워크 상태를 진단할 수 있음