개요
- BigQuery는 구글의 완전 관리형, 서버리스 데이터 웨어하우스
- 스토리지와 컴퓨팅이 완전히 분리된 아키텍처 채택
- 페타바이트급 데이터를 초 단위로 분석
아키텍처 구성
4대 핵심 컴포넌트
-
BigQuery는 네 가지 핵심 컴포넌트로 구성 (Google 인프라 논문 기준)
컴포넌트 역할 특징 Dremel 쿼리 실행 엔진 SQL 쿼리를 분산 처리하여 실행 Colossus 분산 스토리지 데이터를 컬럼 기반 포맷으로 저장 Jupiter 네트워크 인프라 Dremel과 Colossus 간 초고속 데이터 전송 Borg 자원 관리 & 스케줄링 수천 개의 Dremel 작업(Slot)을 물리적 머신에 할당 
Dremel (쿼리 실행 엔진)
개요
- Dremel은 BigQuery의 분산 쿼리 실행 엔진
- 구글 내부에서 대규모 데이터 분석용으로 개발
- 수천 개의 노드에서 병렬 쿼리 실행
쿼리 실행 구조
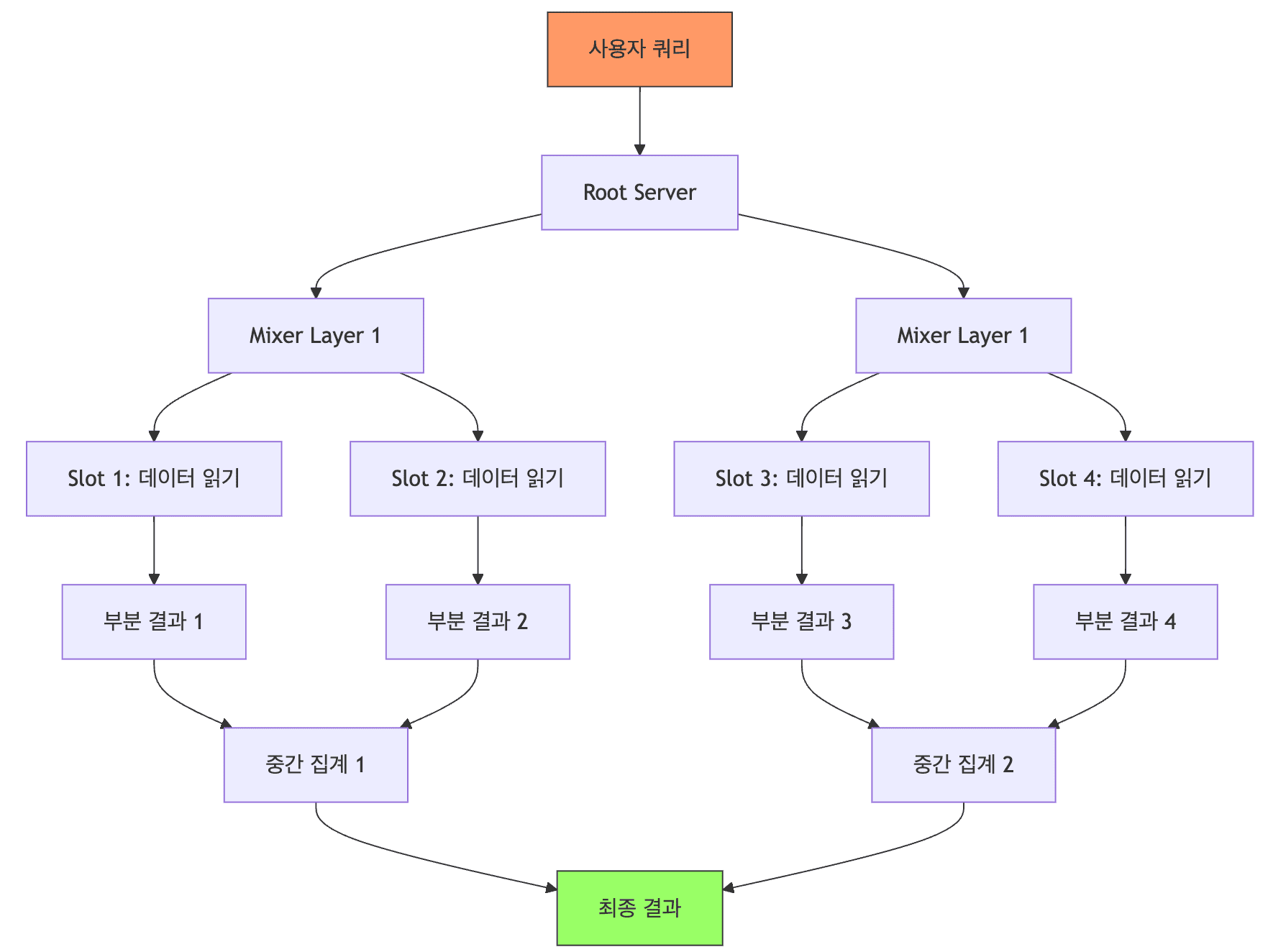
- 쿼리 실행 트리 구조
- Leaf Nodes (Slots)
- 데이터를 실제로 읽고 처리하는 작업 단위
- Colossus에서 데이터를 읽어 필터링, 집계 수행
- 단일 쿼리에 수천 개의 Slot 동시 할당 가능
- Mixers (Branch Nodes)
- Slot에서 처리된 데이터를 집계하는 중간 노드
- 여러 Slot의 결과를 병합하고 추가 집계 수행
- 계층 구조로 구성되어 최종 결과 생성
- Leaf Nodes (Slots)
Slot 기반 리소스 관리
- Slot은 쿼리 실행을 위한 가상 CPU와 메모리 단위
- 특징
- 동적 할당
- 쿼리 복잡도에 따라 자동으로 Slot 수 조정
- 공정성 보장
- 여러 사용자 간 Slot을 공평하게 분배
- 탄력적 확장
- 필요 시 수천 개의 Slot을 즉시 할당 가능
- 동적 할당
컬럼 기반 처리
- Dremel은 컬럼 단위로 데이터 읽기 및 처리
- 장점
- 쿼리에 필요한 컬럼만 읽어 I/O 최소화
- 같은 타입의 데이터를 연속 처리하여 CPU 효율 향상
- 컬럼별 압축으로 네트워크 대역폭 절약
중첩 데이터 지원
- ARRAY, STRUCT 등 복잡한 중첩 구조를 네이티브로 지원
- Capacitor 포맷으로 중첩 데이터를 효율적으로 저장 및 쿼리
Colossus (분산 스토리지)
개요
- Colossus는 구글의 차세대 분산 파일 시스템
- BigQuery의 모든 데이터를 저장하는 스토리지 레이어
- GFS(Google File System)의 후속 버전
주요 특징
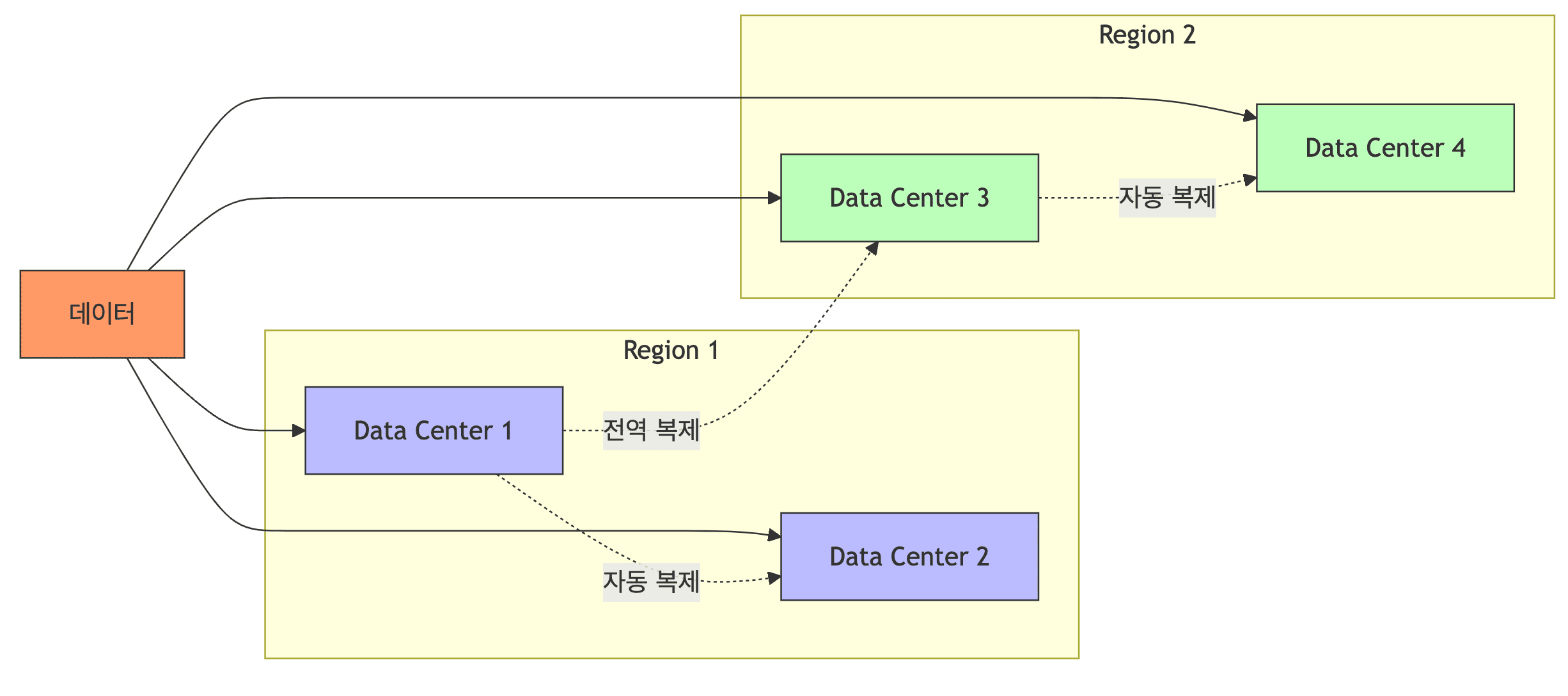
- 전역 분산
- 데이터가 전 세계 여러 데이터센터에 복제
- 99.999999999% (11개의 9) 내구성 보장
- 자동 복제 및 복구
- 데이터를 여러 가용 영역(Availability Zone)에 자동 복제
- 하드웨어 장애 발생 시 자동 데이터 복구
- 무제한 확장성
- 페타바이트급 데이터를 제한 없이 저장 가능
- 스토리지 용량 사전 할당 불필요
Capacitor 저장 포맷
- BigQuery는 Capacitor라는 독자적인 컬럼 기반 포맷 사용
- 특징
- 컬럼별 압축
- 각 컬럼의 데이터 타입과 분포에 최적화된 압축 알고리즘
- 평균 원본 데이터 크기의 1/10 수준으로 압축 (10배 이상의 효율)
- 중첩 구조 지원
- ARRAY, STRUCT를 효율적으로 인코딩
- 반복 레벨(Repetition Level)과 정의 레벨(Definition Level) 사용
- 빠른 스캔 속도
- 컬럼 단위 데이터 읽기로 불필요한 I/O 최소화
- 컬럼별 압축
보안
- 저장 데이터 암호화
- 디스크에 쓰기 전 자동 암호화
- Google 관리 키 또는 고객 관리 키(CMEK) 선택 가능
- 접근 제어
- IAM(Identity and Access Management)을 통한 세밀한 권한 관리
- 행 수준 보안(Row-Level Security) 지원
Jupiter (네트워크 인프라)
개요
- Jupiter는 구글 데이터센터 내부 초고속 네트워크 인프라
- Dremel(컴퓨팅)과 Colossus(스토리지) 간 데이터 전송 담당
성능
- 대역폭
- 페타비트급(Petabit/sec) 네트워크 용량
- 100,000대 이상 머신이 10Gbps 속도로 동시 통신 가능
- 저지연
- 데이터센터 내 노드 간 극히 낮은 지연 시간
- TB급 데이터를 수 초 내 전송 가능
스토리지-컴퓨팅 분리 지원
- Jupiter의 높은 대역폭으로 스토리지와 컴퓨팅 물리적 분리 가능
- 장점
- 컴퓨팅과 스토리지 독립적 확장
- 쿼리 실행 시 네트워크를 통해 데이터를 읽어도 성능 저하 거의 없음
- 스토리지 계층에서 데이터 공유하여 중복 저장 방지
서버리스 아키텍처
개념
- BigQuery는 진정한 의미의 서버리스 서비스
- 인프라 관리 완전 불필요
특징
- 자동 리소스 관리
- 쿼리 실행에 필요한 리소스 자동 할당 및 해제
- 서버, 클러스터, 노드 등 직접 관리 불필요
- 탄력적 확장
- 쿼리 부하에 따라 자동 리소스 확장
- 피크 시간에도 성능 저하 없이 처리
- 사용량 기반 과금
- On-Demand 모드 - 스캔한 데이터량에 비례 과금
- Editions (Autoscaling) - Edition 등급(Standard/Enterprise)에 따른 Slot Autoscaling 및 사용량 과금
고가용성
- 다중 리전 복제
- 데이터를 여러 리전에 자동 복제
- 리전 장애 발생 시에도 서비스 지속 가능
- 자동 페일오버
- 노드 장애 발생 시 다른 노드로 자동 전환
- 쿼리 실행 중 장애 발생 시 자동 재시도
쿼리 실행 흐름
단계별 처리
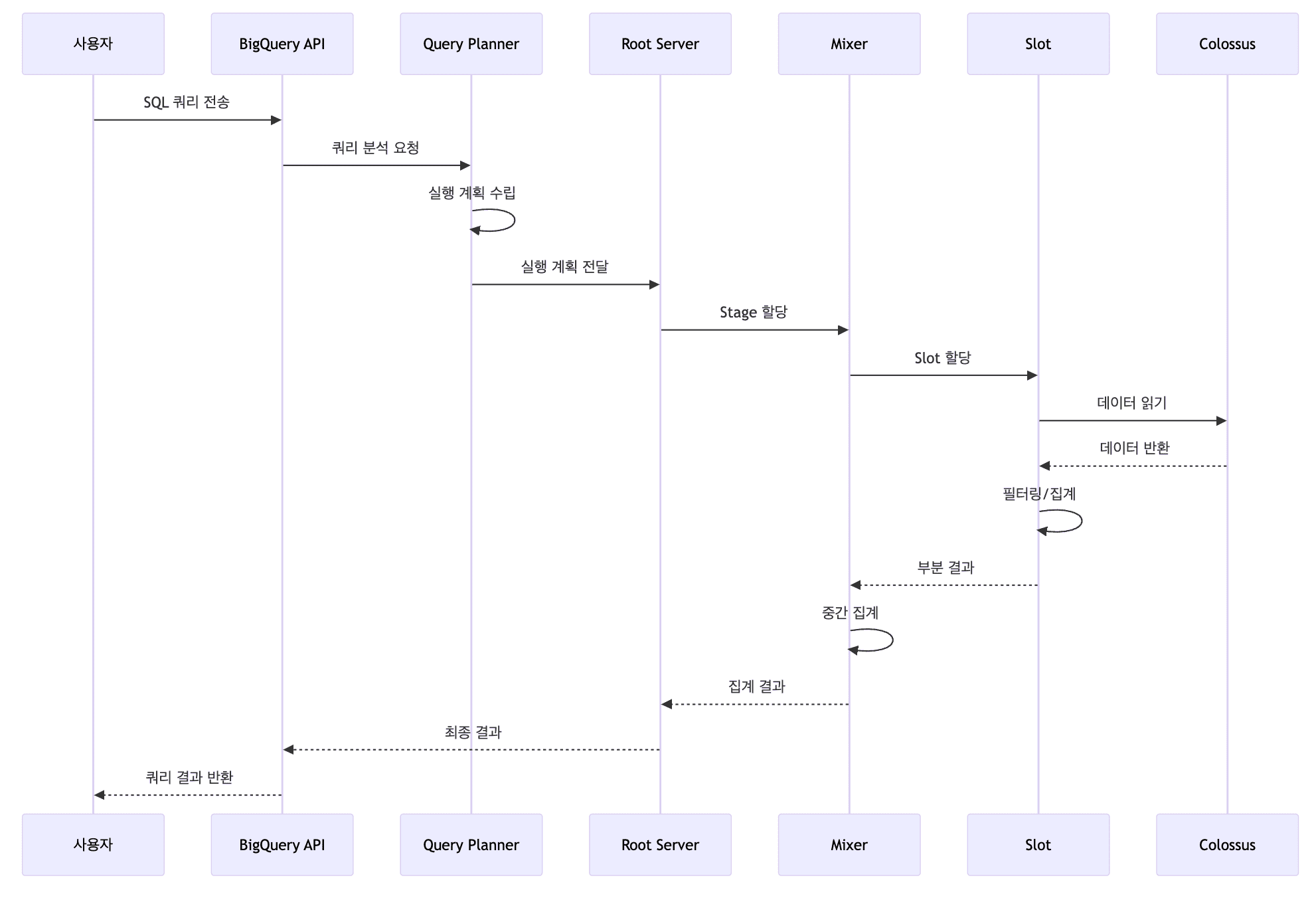
- 쿼리 접수
- 사용자가 SQL 쿼리를 BigQuery API로 전송
- Query Planner가 쿼리 분석 및 실행 계획 생성
- 실행 계획 수립
- 쿼리를 여러 Stage로 분할
- 각 Stage에 필요한 Slot 수 계산
- 인메모리 셔플(Remote Shuffle Service) 계획 수립 (디스크 I/O 없이 메모리 간 고속 데이터 교환)
- 분산 실행
- 각 Stage를 수천 개의 Slot에 할당
- Slot이 Colossus에서 데이터를 병렬로 읽기
- 필터링, 집계, 조인 등을 병렬 수행
- 데이터 집계
- Mixer 노드가 Slot 결과를 계층적으로 집계
- 최종 Mixer가 결과를 사용자에게 반환
- 결과 반환
- 쿼리 결과를 사용자에게 전송
- 결과가 클 경우 임시 테이블에 저장
최적화 기법
- Partition Pruning
- 파티션 필터를 사용하여 불필요한 파티션 스캔 제외
- 비용과 실행 시간 획기적 단축
- Predicate Pushdown
- 필터 조건을 데이터 읽기 단계로 이동
- 읽는 데이터량 최소화
- Column Pruning
- 쿼리에 필요한 컬럼만 읽도록 자동 최적화
- BI Engine 캐싱
- 자주 사용되는 쿼리 결과를 메모리에 캐싱
- 반복 쿼리 응답 시간을 밀리초 단위로 단축
BigQuery 차별화 요소
완전한 스토리지-컴퓨팅 분리
| 구분 | 전통적 DW | BigQuery |
|---|---|---|
| 아키텍처 | 스토리지-컴퓨팅 결합 | 완전 분리 |
| 확장 | 수동, 제한적 | 자동, 독립적 |
| 예시 | Teradata, Oracle Exadata | Dremel + Colossus |
진정한 서버리스
- 경쟁 제품과의 비교
- AWS Redshift (Provisioned) - 클러스터 크기 사전 지정 필요 (Serverless도 워크그룹 단위 자원 공유)
- Snowflake - Virtual Warehouse 사전 할당 필요
- BigQuery - 쿼리 단위 격리, 쿼리 하나하나가 독립적인 슬롯을 할당받아 자동 확장
무제한 동시성
- 동시 쿼리 수 제한 없음
- 각 쿼리가 독립적으로 리소스 할당
- 피크 시간에도 성능 저하 없음
분 단위 과금
- BigQuery Editions 사용 시 Slot Autoscaling 적용
- 경쟁사 - 시간 또는 일 단위 약정 필요
- BigQuery - 워크로드에 따라 초 단위로 Slot 자동 확장 및 과금
BigQuery ML 및 에코시스템
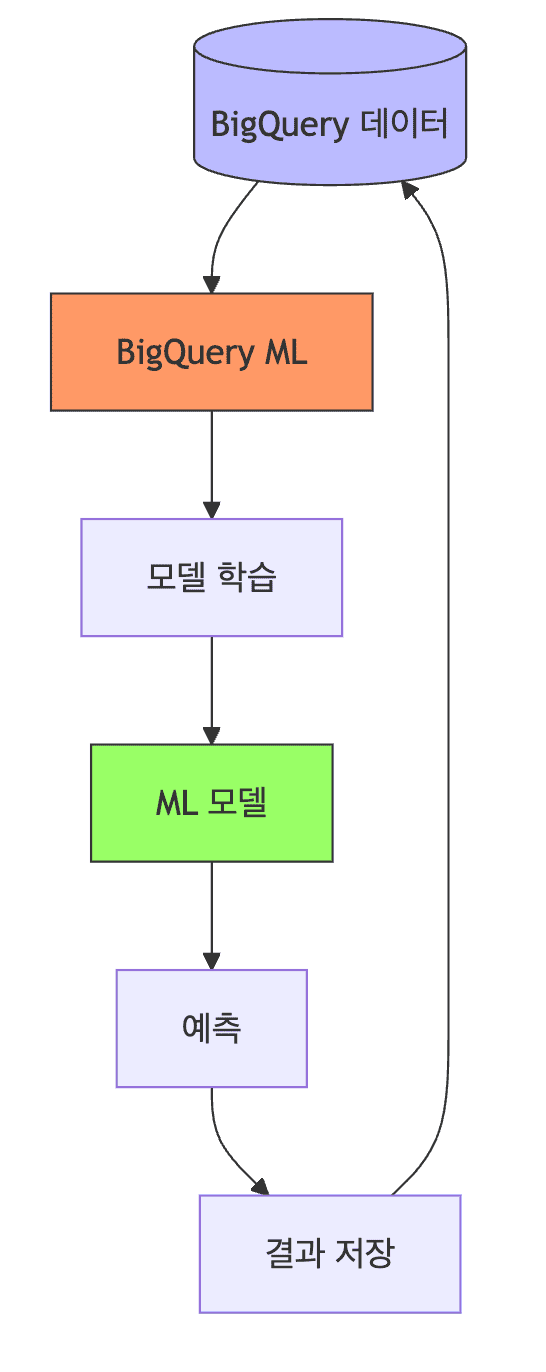
BigQuery ML
- SQL로 머신러닝 모델 학습 및 예측 가능
- 지원 모델
- 선형 회귀, 로지스틱 회귀
- K-Means 클러스터링
- 시계열 예측 (ARIMA)
- Deep Neural Network (DNN)
- AutoML Tables
연동 서비스
- Google Cloud 서비스
- Vertex AI - 고급 ML 모델 학습 및 배포
- Dataflow - 스트리밍 데이터 파이프라인
- Pub/Sub - 실시간 데이터 수집
- Looker, Data Studio - 시각화 및 BI
- 서드파티 통합
- Tableau, Power BI, Qlik 등 BI 도구
- dbt, Dataform 등 데이터 변환 도구
- Apache Spark, Apache Beam
성능 벤치마크
실제 성능 사례
| 작업 | 데이터 크기 | 소요 시간 | Slot 수 | 비용 (On-Demand) |
|---|---|---|---|---|
| 전체 스캔 | 1PB | ~30초 | 2,000 | $5,000 |
| JOIN 쿼리 | 10TB | ~20초 | 1,000 | $50 |
| 집계 쿼리 | 100TB | ~45초 | 1,500 | $500 |
- 경쟁사 대비 10배~100배 빠른 성능
TPC-DS 벤치마크
- TPC-DS는 데이터 웨어하우스 표준 벤치마크
- BigQuery는 99개 쿼리 중 대부분을 30초 이내 처리
- 경쟁사보다 높은 쿼리당 처리량(Queries per Hour) 기록
제약 사항
쿼리 제한
| 항목 | 제한 |
|---|---|
| 단일 쿼리 최대 실행 시간 | 6시간 |
| DML 쿼리 최대 실행 시간 | 6시간 |
| 쿼리 결과 크기 (응답) | 최대 2GB |
| 쿼리 결과 크기 (테이블 저장) | 무제한 |
스트리밍 제한
| 항목 | 제한 |
|---|---|
| 테이블당 초당 최대 행 삽입 | 1,000,000 |
| 행당 최대 크기 | 10MB |
| 최근 삽입 데이터 SELECT 지연 | 수 초 |
정리
-
BigQuery 아키텍처의 특징
요소 설명 Dremel 분산 쿼리 실행 엔진, Slot 기반 리소스 관리 Colossus 전역 분산 스토리지, Capacitor 컬럼 포맷 Jupiter 페타비트급 네트워크, 스토리지-컴퓨팅 분리 지원 서버리스 완전 관리형, 자동 확장, 무제한 동시성 성능 TB~PB급 데이터를 초 단위로 분석