개요
- 데이터베이스는 크게 OLTP와 OLAP로 구분됨
- 각각의 특징과 사용 사례를 이해하면 적절한 데이터베이스를 선택할 수 있음
OLTP와 OLAP
OLTP (Online Transactional Processing)
- PostgreSQL, MySQL이 해당함
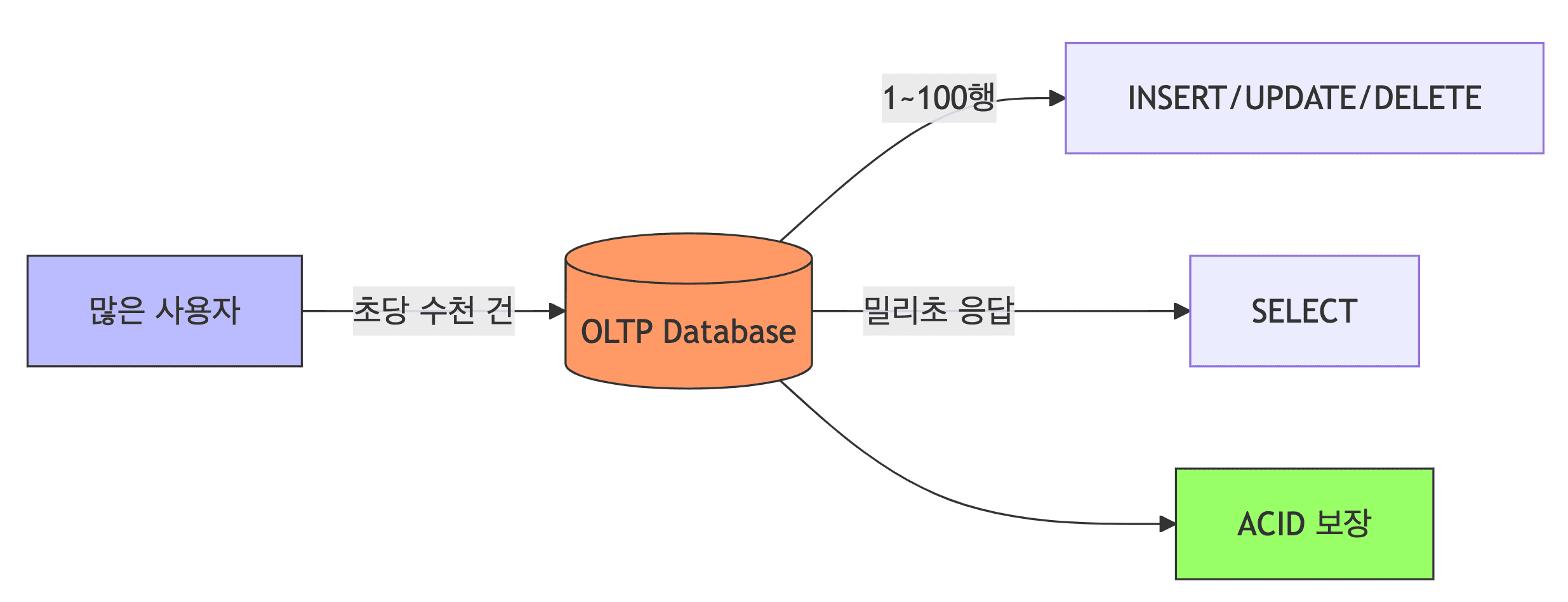
- 목적
- 빠르고 정확한 일일 거래 처리
- 특징
- 많은 사용자의 작은 쿼리들 (SELECT 1~100행, INSERT/UPDATE 1행)
- 높은 빈도 (초당 수천 건)
- 실시간 응답 (밀리초 단위)
- ACID 보장 (데이터 무결성)
- 데이터 특성
- 정규화된 스키마 (중복 최소화)
- 행(Row) 기반 저장
- 주로 INSERT/UPDATE/DELETE 작업
- 실제 예시
- 은행 계좌이체 (트랜잭션 안전성이 중요)
- 온라인 쇼핑 결제
- CRM 고객정보 업데이트
- 주문관리 시스템
OLAP (Online Analytical Processing)
- BigQuery, Redshift, AnalyticDB가 해당함
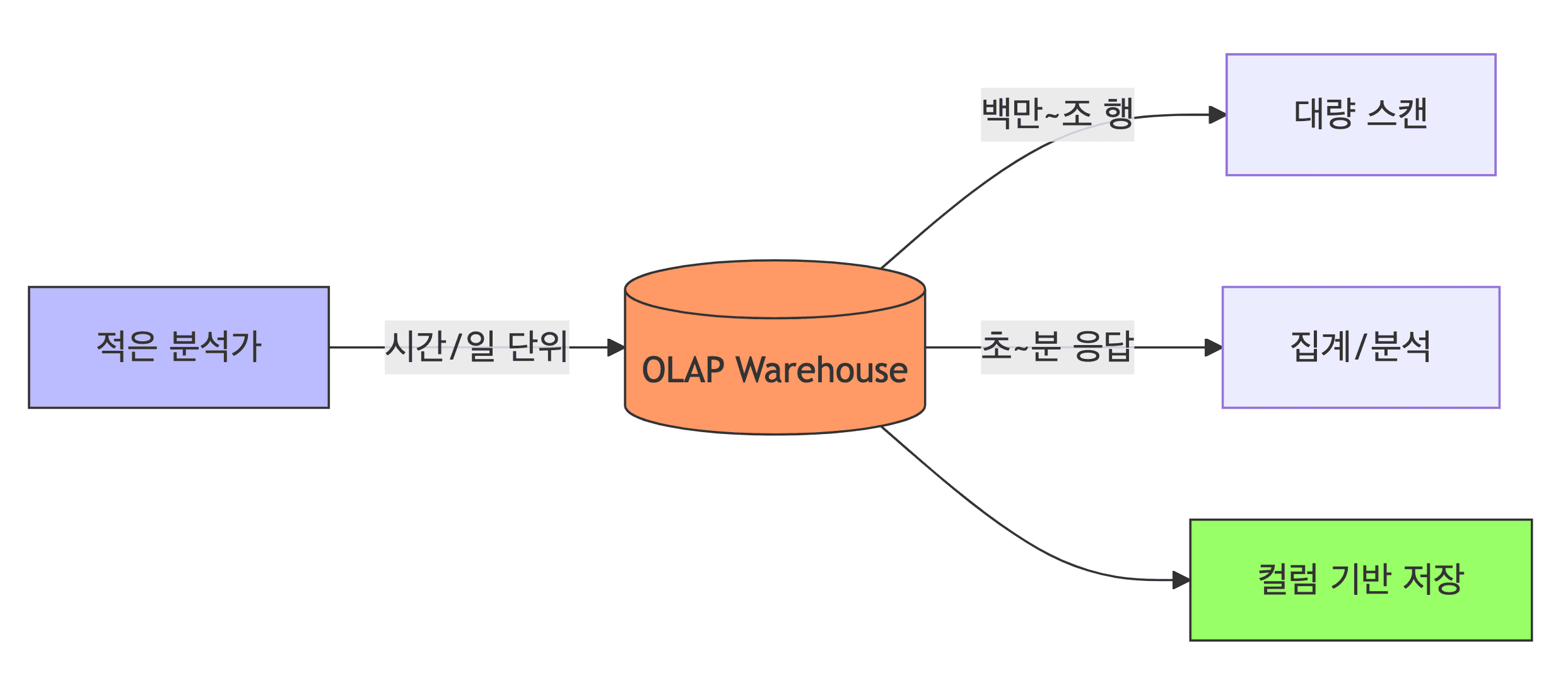
- 목적
- 대규모 데이터 분석 및 보고서 생성
- 특징
- 적은 사용자의 큰 쿼리들 (SELECT 백만~조 행)
- 낮은 빈도 (시간/일 단위)
- 느린 응답 허용 (초~분 단위)
- 일관성보다는 쿼리 성능 중시
- 데이터 특성
- 비정규화된 스키마 (조인 최소화)
- 컬럼(Column) 기반 저장
- 대부분 READ 작업 (일괄 INSERT)
- 실제 예시
- 월간 매출 분석 리포트
- 고객 행동 분석
- 광고 성과 분석 (수백만 행 집계)
- 데이터 사이언스/ML 모델 학습
저장 방식 비교
Row-Based Storage
-
PostgreSQL, MySQL이 사용함
-
테이블 데이터
customer_id name email age city 1 Kim k@… 28 Seoul 2 Lee l@… 35 Busan 3 Park p@… 42 Seoul -
물리적 저장
1
[1][Kim][k@...][28][Seoul] [2][Lee][l@...][35][Busan] [3][Park][p@...][42][Seoul]
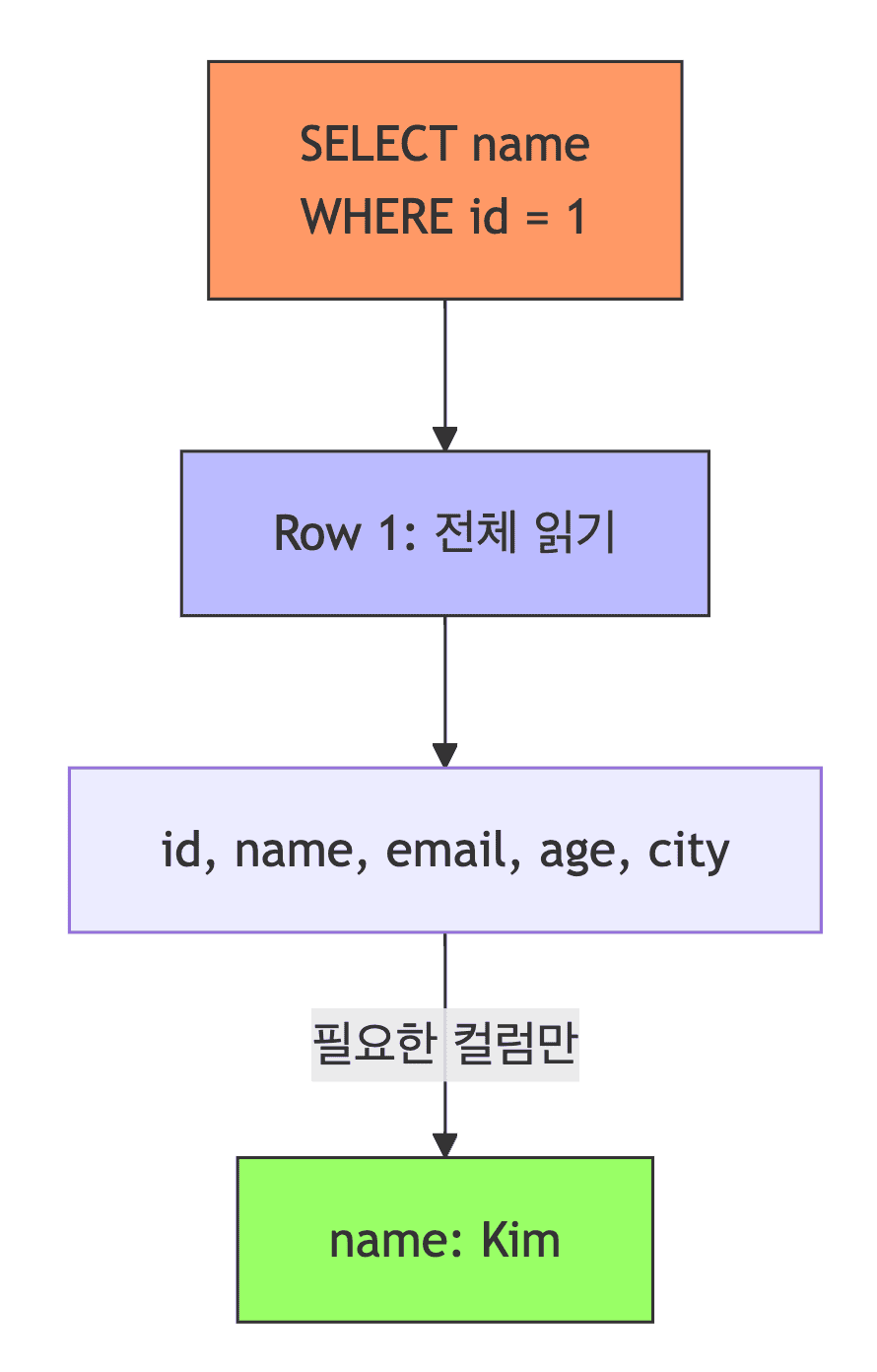
- 장점
- 한 행의 모든 데이터가 함께 저장되므로, 한 행을 조회하기 빠름
- 한 행을 한 번의 메모리 접근으로 읽을 수 있음
- INSERT/UPDATE 쉬움 (한 행의 모든 값을 한 번에 변경)
- 단점
- 특정 컬럼만 집계하려면 비효율적
SELECT AVG(age) FROM customers WHERE city = 'Seoul'실행 시- 100만 행에서 name, email, city 정보까지 다 읽어야 함 (불필요한 I/O 발생)
- 압축이 안 좋음 (다양한 데이터 타입이 섞여있음)
Columnar Storage
-
BigQuery, AnalyticDB, Redshift가 사용함
- 컬럼별로 분리
1 2 3 4 5
customer_id: [1, 2, 3, 4, 5, ...] name: [Kim, Lee, Park, Choi, ...] email: [k@..., l@..., p@..., c@..., ...] age: [28, 35, 42, 31, 29, ...] city: [Seoul, Busan, Seoul, Seoul, ...]
- 물리적 저장
1 2
[age 컬럼] = [28][35][42][31][29][26]... [city 컬럼] = [Seoul][Busan][Seoul][Seoul]...
- 컬럼별로 분리
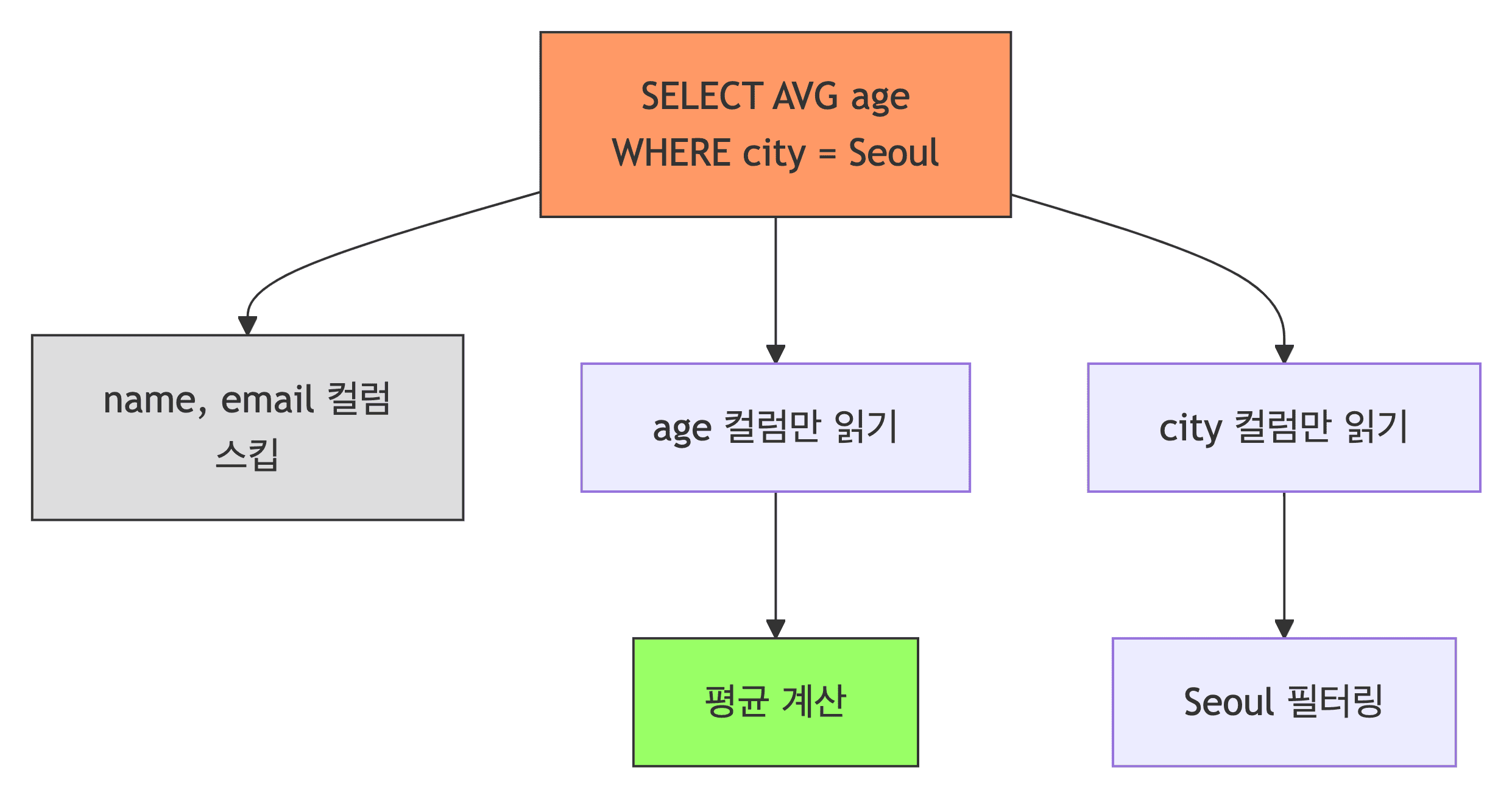
- 장점
- 분석 쿼리 빠름
SELECT AVG(age) WHERE city='Seoul'실행 시- age와 city 컬럼만 읽으면 되고, 나머지는 스킵
- Row-based는 100만 행 전체를 읽어야 하지만, Columnar는 필요한 2개 컬럼만 쏙 빼서 읽음 (100배 이상 빠름)
- 압축이 우수함
- 같은 타입의 데이터를 연속으로 저장하므로 압축 효율이 극대화됨
- 예:
city컬럼에 ‘Seoul’이 100만 개 있으면,Seoul: 100만개형태의 메타데이터로 저장하여 용량을 획기적으로 줄임 (저장 용량 90% 이상 감소)
- 메모리 효율
- 필요한 컬럼만 메모리에 로드
- 분석 쿼리 빠름
- 단점
- 한 행 조회 느림
- age만 필요해도 다른 모든 컬럼을 다시 매핑해야 함
- UPDATE 느림
- 한 행을 수정하려면 모든 컬럼을 다시 써야 함
- 구현이 복잡함
- 한 행 조회 느림
성능 비교
| 쿼리 | Row-Based (MySQL) | Columnar (BigQuery) |
|---|---|---|
SELECT name WHERE id = 1 |
1ms | 50ms |
SELECT AVG(salary) |
5초 | 100ms |
SELECT AVG(salary) WHERE age > 30 |
8초 | 150ms |
아키텍처 비교
단일 서버 (PostgreSQL/MySQL)
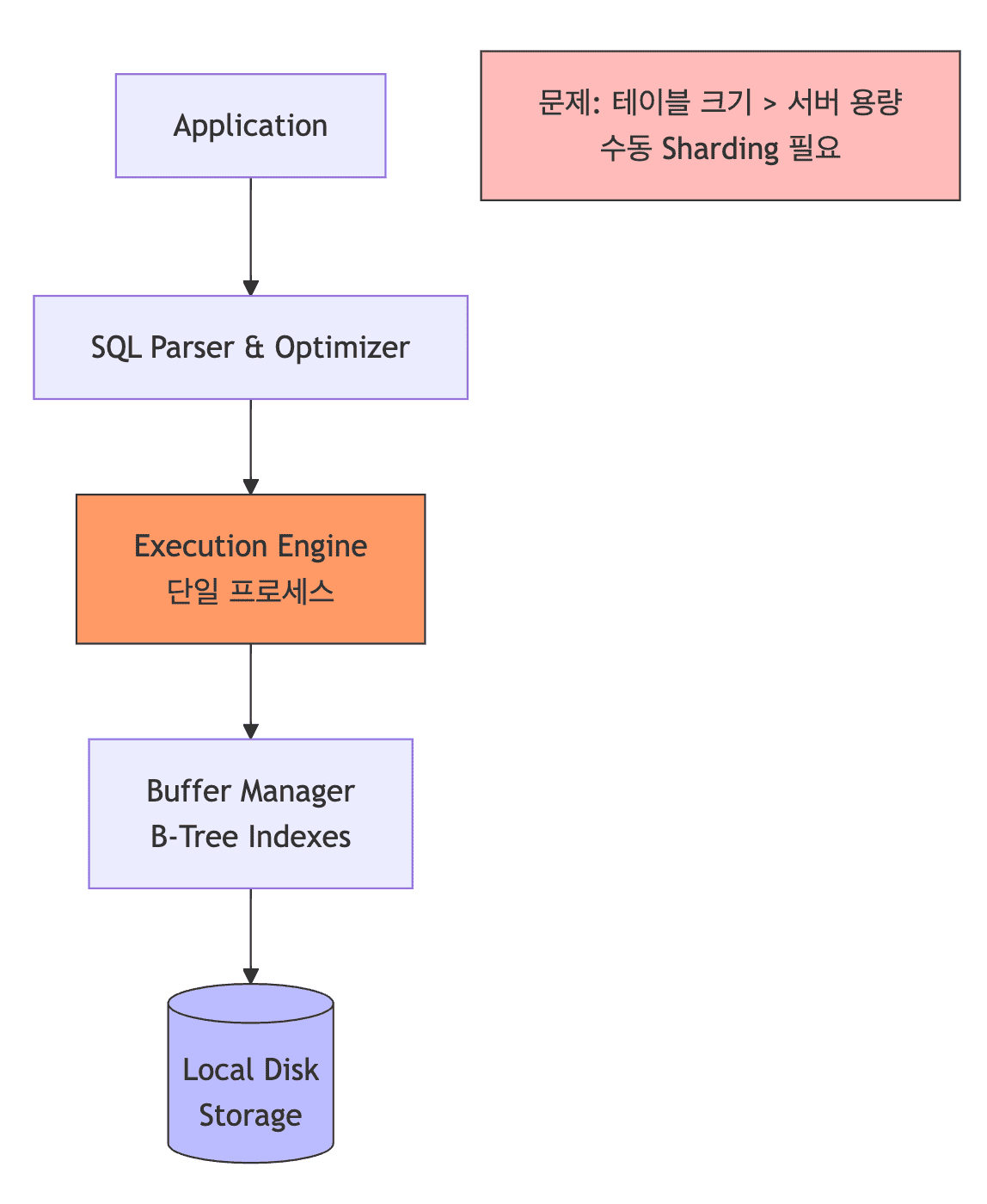
- 특징
- 하나의 서버에서 모든 일 처리
- 수평 확장 어려움 (Sharding 복잡)
- 높은 동시성 처리 (멀티스레드)
MPP (BigQuery/Redshift/AnalyticDB)
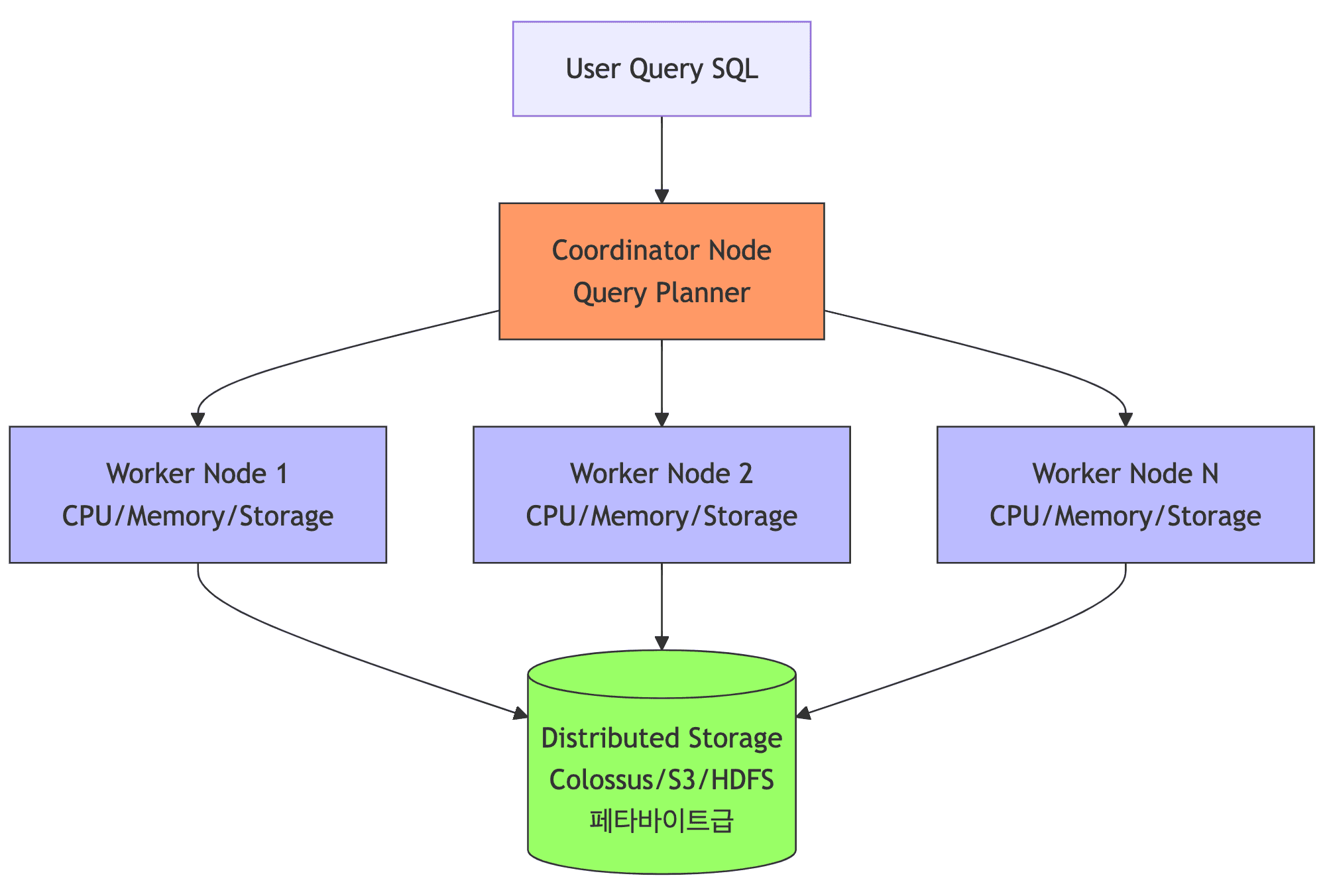
- Shared-Nothing Architecture (또는 Storage-Compute Decoupled)
- 각 노드가 독립적으로 자신의 데이터 처리
- BigQuery는 특히 스토리지(Colossus)와 연산(Borg)이 완전히 분리된 구조로, 무제한 확장성을 제공함
- 특징
- 쿼리가 자동으로 분산 (1조 행 데이터도 수천 개 노드에서 병렬 처리)
- 수평 확장 자동 (노드 추가하면 성능 거의 선형 증가)
- Fault Tolerance (한 노드 실패해도 다른 노드가 처리)
- 느린 쿼리지만 확장성 무한
데이터베이스 비교
AnalyticDB와 BigQuery
| 특징 | AnalyticDB for MySQL | BigQuery |
|---|---|---|
| 아키텍처 | MPP (분산) | Serverless (Storage-Compute Decoupled) |
| 스토리지 | 컬럼 기반 | 컬럼 기반 (Capacitor 포맷) |
| 가격 모델 | 예약형 (시간당) | On-Demand (TB당) 또는 Editions (Autoscaling) |
| 쿼리 속도 | 중간~빠름 (수초) | 매우 빠름 (초 단위) |
| 데이터 크기 제한 | 클러스터 용량 제한 | 무제한 (페타바이트) |
| 관리 복잡도 | 높음 (노드 관리) | 낮음 (자동 관리) |
| 실시간 삽입 | 매우 우수 (MySQL 호환) - 높은 동시성 | 우수 (스트리밍 지원, 비용 발생) |
| 강점 | 기존 MySQL 호환성 | 무제한 확장성, 구글 ML 통합 |
가격 모델 비교

- PostgreSQL / MySQL (On-Premise)
- 초기 비용: 하드웨어 구매 $10,000+
- 매월 운영비: 인력 (DBA), 유지보수 $5,000+
- 확장 시: 하드웨어 추가 구매 (시간 소요)
- AnalyticDB for MySQL (알리바바)
- 월간: 예약형 $179~$359 (8-16 cores 기준)
- 데이터 저장: $0.15/GB/month
- 특징: 예측 가능한 비용
- BigQuery (구글)
- Option A: On-Demand (문서당 과금)
- 쿼리 비용: $6.25 per TiB 스캔 (약 $5.70 per TB)
- 특징: 사용한 만큼만 지불, 비용 예측 어려움
- Option B: BigQuery Editions (Slot Autoscaling)
- 쿼리량에 따라 슬롯(연산 자원)이 자동으로 늘어나고 줄어드는 구조
- Standard / Enterprise / Enterprise Plus 등급에 따라 슬롯당 비용 지불
- 기존의 정액제(Flat Rate)는 폐지됨
- 특징: “예측 가능성”보다는 “성능과 비용의 유연성”이 강조됨
- 예시
- 쿼리가 없을 때는 슬롯 0개 (비용 0), 폭주시 수천 개로 자동 확장 (비용 발생)
- Option A: On-Demand (문서당 과금)
사용 사례
PostgreSQL / MySQL
- 웹 애플리케이션의 운영 데이터 (회원정보, 주문, 재고)
- 자주 업데이트가 필요한 데이터 (계좌 잔액, 상품 재고)
- ACID 보장 필수 (금융, 결제)
- 데이터 크기 < 1TB
AnalyticDB for MySQL
- MySQL 생태계에 이미 데이터가 있는 상황
- 중간 규모 분석 (1TB ~ 100TB)
- 알리바바 클라우드 생태계 (OSS, DataWorks와 통합)
- 예측 가능한 월간 비용 필요
BigQuery
- 초대규모 데이터 (100TB+)
- 실시간 분석 필요 (스트리밍 데이터 수집)
- 구글 AI/ML 서비스 통합 필요 (BigQuery ML, Vertex AI)
- 인프라 관리 최소화 원함
- 비용이 중요하지 않거나 예측 가능해야 할 때 (Slot 예약)
의사결정 가이드
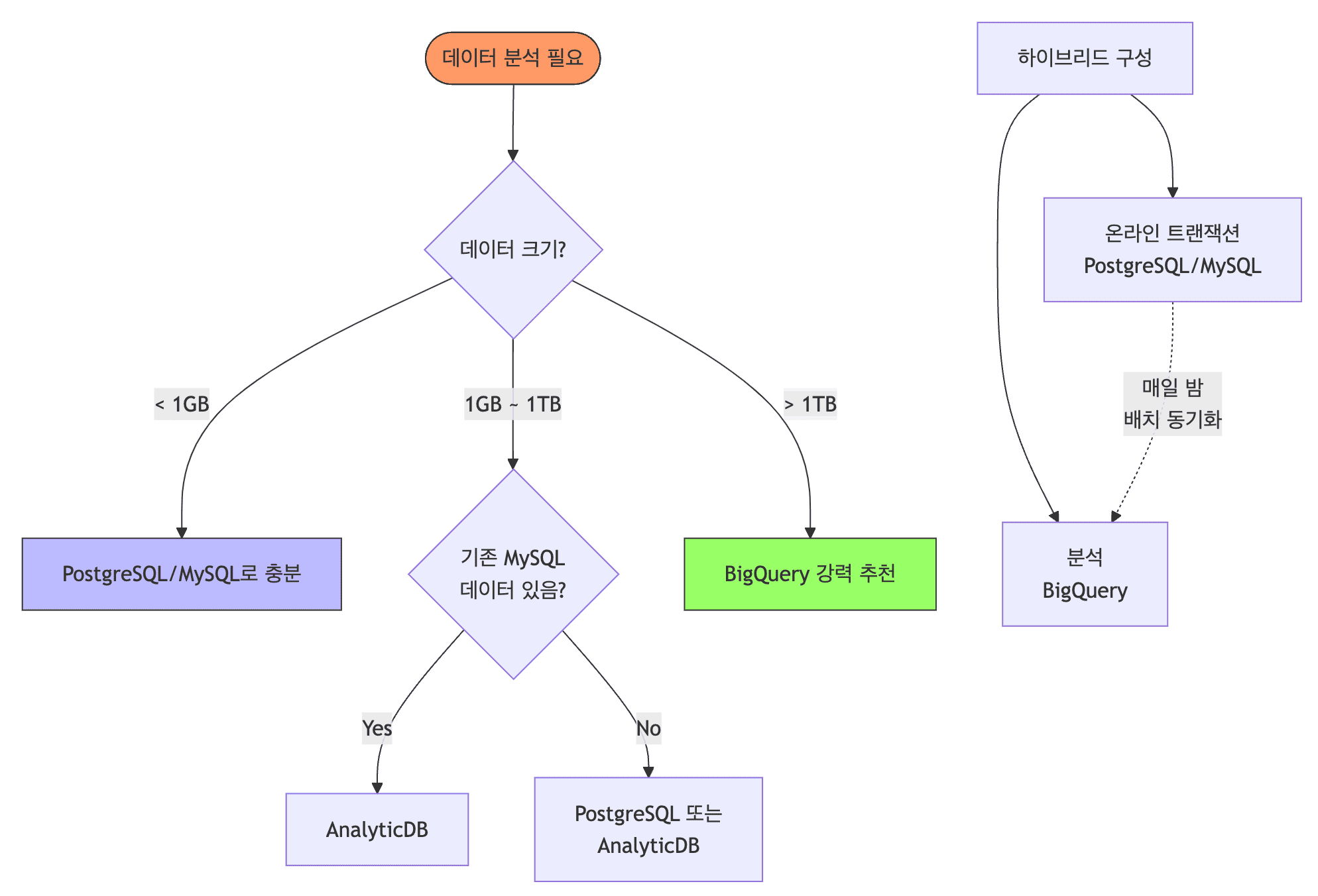
정리
| 항목 | PostgreSQL/MySQL | AnalyticDB | BigQuery |
|---|---|---|---|
| 용도 | OLTP (거래) | OLAP (분석) | OLAP (초대규모 분석) |
| 저장소 | Row-based | Columnar | Columnar |
| 확장성 | 수동/어려움 | 중간 (MPP) | 무제한 |
| 응답시간 | ms | 초 | 초 |
| 동시성 | 높음 | 낮음 | 낮음 |
| 데이터 크기 | GB ~ TB | TB | PB |
| 관리복잡도 | 높음 | 중간 | 낮음 |
| 비용 예측 | 가능 | 가능 | 어려움 (On-Demand) |