개요
- 대용량 테이블을 더 작고 관리 가능한 단위로 분할하는 기법으로 쿼리 성능 향상과 데이터 관리 효율성을 제공함
- 중요
- 이 글은 단일 DB 인스턴스 내에서의 논리적 분할(파티셔닝)을 다루며 서버를 물리적으로 나누는 샤딩(Sharding)과는 구별됨
- 파티셔닝
- 하나의 DB 서버 내에서 테이블을 논리적으로 분할
- 샤딩
- 여러 DB 서버에 데이터를 물리적으로 분산
수평 파티셔닝
-
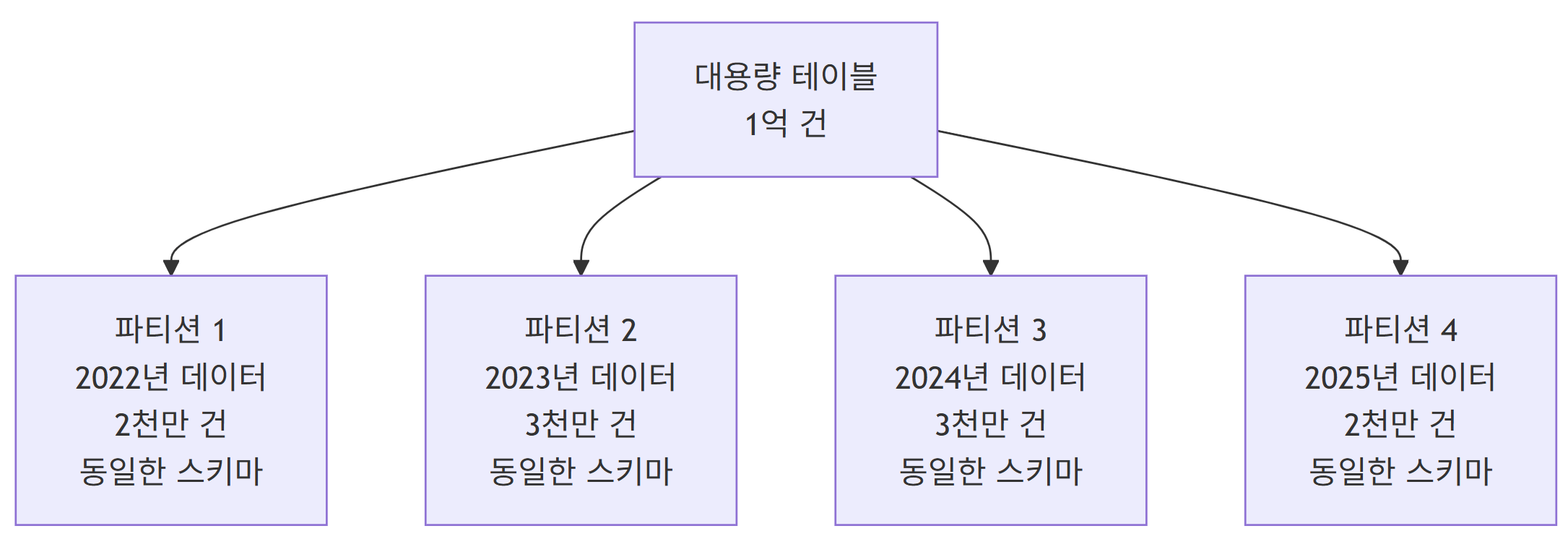
행을 기준으로 테이블을 분할하는 방식으로 각 파티션은 동일한 스키마를 가지지만 다른 행 집합을 저장함
-
구조
특징
- 동일한 스키마
- 다른 행 집합
- 수평 확장 용이
- 논리적으로는 하나의 테이블, 물리적으로는 여러 테이블
장점
- 쿼리 성능 향상(파티션 프루닝)
- 데이터 관리 효율성
- 병렬 처리 가능
- 파티션 단위 백업/복구
- 오래된 파티션 삭제 용이
사용 사례
- 대용량 테이블
- 시계열 데이터
- 지역별 데이터 분산
- 데이터 보관 정책이 필요한 경우
수직 파티셔닝
-
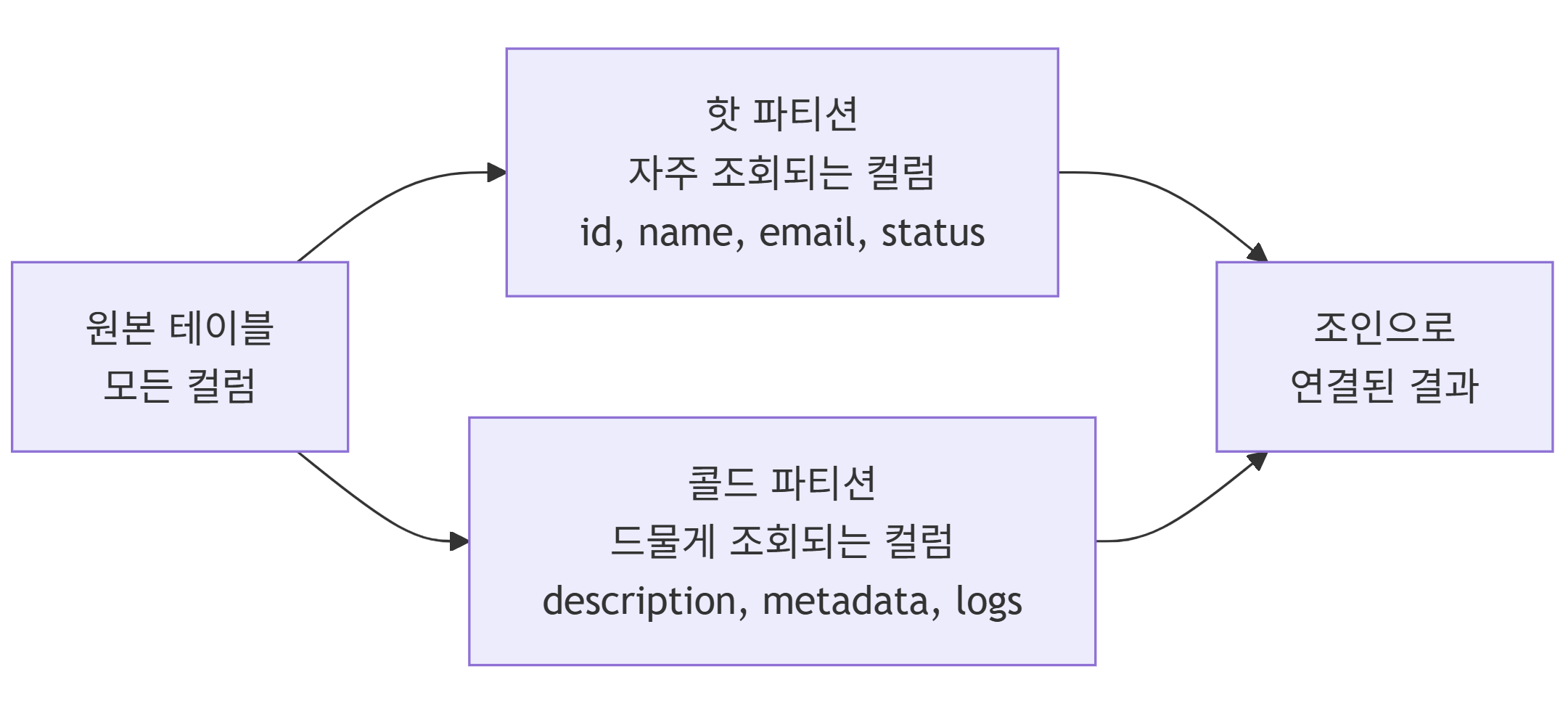
컬럼을 기준으로 테이블을 분할하는 방식으로 자주 함께 조회되는 컬럼들을 그룹화함
-
구조
특징
- 컬럼 기준 분할
- 자주 함께 조회되는 컬럼 그룹화
- I/O 최적화
- 각 파티션은 다른 행 수를 가질 수 있음
장점
- 필요한 컬럼만 읽어 I/O 감소
- 자주 사용되지 않는 컬럼 분리
- 캐시 효율성 향상
- 대용량 컬럼(
BLOB,TEXT) 분리로 성능 향상
사용 사례
- 넓은 테이블(많은 컬럼)
- 다양한 접근 패턴
- 자주 사용되지 않는 대용량 컬럼(
BLOB,TEXT등) - 핫 데이터와 콜드 데이터가 명확히 구분되는 경우
파티셔닝 방식
Range Partitioning
- 컬럼 값의 범위에 따라 데이터를 분할함
-
날짜나 순차적 ID 같은 이력성 데이터에 특히 유리하며 시계열 데이터 관리에 가장 많이 사용됨
-
구조

- 참고
-
본 예시는
MySQL 8.0기준으로 작성되었으며PostgreSQL이나Oracle은 파티셔닝 문법이 다를 수 있음1 2 3 4 5 6 7 8 9 10
CREATE TABLE orders ( order_id INT, order_date DATE, amount DECIMAL(10,2) ) PARTITION BY RANGE (YEAR(order_date)) ( PARTITION p2022 VALUES LESS THAN (2023), PARTITION p2023 VALUES LESS THAN (2024), PARTITION p2024 VALUES LESS THAN (2025), PARTITION p_future VALUES LESS THAN MAXVALUE );
-
특징
- 범위 기반 분할
- 시계열 데이터에 최적
- 오래된 파티션 삭제 용이
List Partitioning
- 명시적인 값 목록을 기준으로 데이터를 분할함
-
지역, 부서 코드처럼 불연속적인 값들로 데이터를 그룹화할 때 사용됨
- 참고
-
본 예시는
MySQL 8.0기준으로 작성되었음1 2 3 4 5 6 7 8 9
CREATE TABLE sales ( sale_id INT, region VARCHAR(50), amount DECIMAL(10,2) ) PARTITION BY LIST (region) ( PARTITION p_north VALUES IN ('Seoul', 'Incheon'), PARTITION p_south VALUES IN ('Busan', 'Daegu'), PARTITION p_etc VALUES IN (DEFAULT) );
-
특징
- 명시적 값 목록 기반
- 불연속적 값에 적합
- 지역, 부서 등 카테고리별 분할
Hash Partitioning
- 해시 함수를 사용하여 데이터를 균등하게 분산시킴
- 중복성이 없는 컬럼에 적용하며 데이터가 자동으로 고르게 분포됨
- ex)
- ID 컬럼
- ex)
-
동작 원리

- 참고
-
본 예시는
MySQL 8.0기준으로 작성되었음1 2 3 4 5
CREATE TABLE users ( user_id INT, username VARCHAR(50), email VARCHAR(100) ) PARTITION BY HASH (user_id) PARTITIONS 4;
-
특징
- 해시 함수 기반 분할
- 균등한 데이터 분산
- 범위 기준이 명확하지 않을 때 유용
장점
- 자동 균등 분산
- 파티션 간 부하 균형
단점
- 파티션 프루닝 어려움
- 범위 쿼리 비효율적
- 범위 조건(
>,<,BETWEEN) 검색 시 모든 파티션을 스캔해야 함(Full Partition Scan) - 등호(
=) 검색 위주의 워크로드에만 사용해야 함 - 범위 쿼리가 필요한 경우 Hash Partitioning은 부적합함
Composite Partitioning
- 여러 파티셔닝 방식을 조합함
-
Range-Hash, Range-List 같은 조합으로 더 세밀한 데이터 분할이 가능하며 복잡한 데이터 관리 요구사항을 충족함
- 참고
-
본 예시는
MySQL 8.0기준으로 작성되었음1 2 3 4 5 6 7 8 9 10 11
-- Range-Hash 복합 파티셔닝 CREATE TABLE orders ( order_id INT, order_date DATE, customer_id INT, amount DECIMAL(10,2) ) PARTITION BY RANGE (YEAR(order_date)) SUBPARTITION BY HASH (customer_id) SUBPARTITIONS 4 ( PARTITION p2023 VALUES LESS THAN (2024), PARTITION p2024 VALUES LESS THAN (2025) );
-
특징
- 여러 방식 조합
- 세밀한 데이터 분할
- 복잡한 요구사항 충족
파티션 프루닝
- 쿼리 실행 시 불필요한 파티션을 제거하여 성능을 최적화하는 기법임
-
쿼리 옵티마이저가
WHERE절의 조건을 분석하여 관련 없는 파티션을 스캔 대상에서 제외함 -
동작 원리

- 쿼리 옵티마이저가
WHERE절 분석 - 파티션 키 조건 추출
- 관련 없는 파티션 제외
- 필요한 파티션만 스캔
- 쿼리 옵티마이저가
효과
- I/O 작업 감소
- 메모리 사용량 감소
- 쿼리 실행 시간 단축
- 파티션 개수가 많을수록 효과 증가
조건
- 쿼리 조건이 파티션 키를 직접 참조
- 상수나 파라미터 사용
- 파티션 키에 대한 직접적인 비교 연산
- 함수나 연산을 파티션 키에 적용하면 프루닝 실패 가능
1
2
3
4
5
6
7
8
9
10
11
-- Range 파티셔닝된 테이블
-- 파티션 - p2022, p2023, p2024
-- 이 쿼리는 p2023 파티션만 스캔
SELECT * FROM orders
WHERE order_date >= '2023-01-01'
AND order_date < '2024-01-01';
-- 이 쿼리는 프루닝 실패 (함수 사용)
SELECT * FROM orders
WHERE YEAR(order_date) = 2023; -- 모든 파티션 스캔
MySQL 8.0의 개선 사항
-
기본적으로 함수를 파티션 키에 적용하면 프루닝이 실패하지만
MySQL 8.0부터는 Virtual Column이나 Functional Index를 활용하면 함수 결과로도 파티셔닝 최적화가 가능함1 2 3 4 5 6 7 8 9 10
-- Virtual Column을 사용한 파티셔닝 CREATE TABLE orders ( order_id INT, order_date DATE, order_year INT AS (YEAR(order_date)) VIRTUAL, amount DECIMAL(10,2) ) PARTITION BY RANGE (order_year) ( PARTITION p2022 VALUES LESS THAN (2023), PARTITION p2023 VALUES LESS THAN (2024) );
PostgreSQL 설정
constraint_exclusion설정으로 제어- 기본값
partition(파티션 테이블에만 적용)
on- 모든 테이블에 적용
off- 비활성화
최적화 팁
- 테이블 통계를 최신 상태로 유지
- 파티션 키에 대한 인덱스 생성
- 파티션 키를
WHERE절에 포함 - 파티션 키에 함수나 연산 적용 지양 (최신 버전 기능 활용 고려)
- 파티션 개수는 적절히 유지(너무 많으면 오버헤드)
파티셔닝과 인덱스
- 파티셔닝의 가장 큰 난관은 인덱스 설계임
- 인덱스 전략에 따라 성능이 크게 달라짐
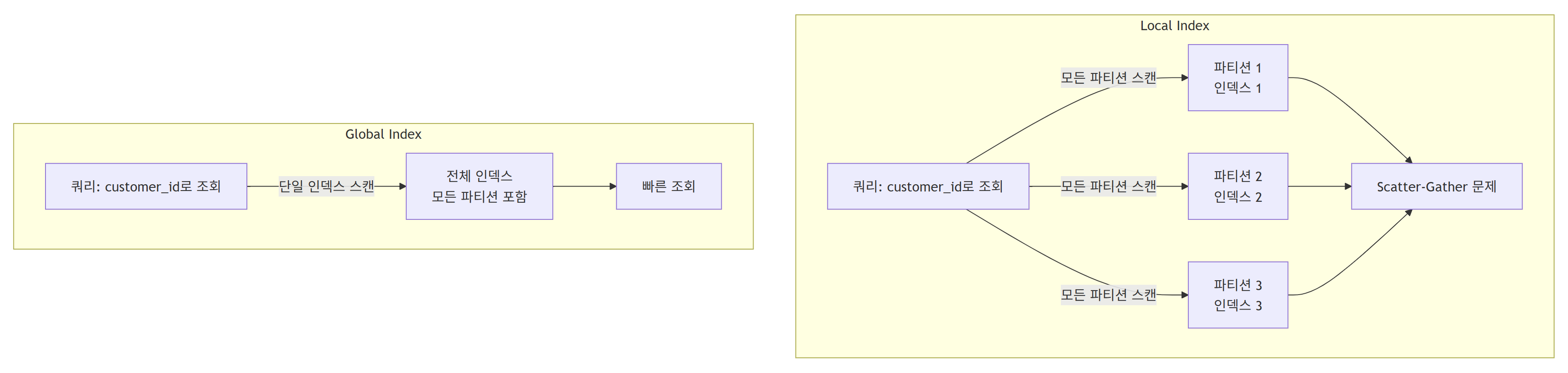
Local Index (로컬 인덱스)
- 각 파티션별로 인덱스를 따로 만드는 방식
특징
- 각 파티션마다 독립적인 인덱스 존재
- 파티션 삭제/추가 시 해당 파티션의 인덱스만 영향받음
- 관리가 상대적으로 편함
단점
- 파티션 키가 아닌 컬럼으로 조회하면 모든 파티션의 인덱스를 뒤져야 함
- Scatter-Gather 문제 발생
- ex)
order_date로 파티셔닝했는데customer_id로 조회하면 모든 파티션 스캔 필요
사용 시점
- 파티션 키로 주로 조회하는 경우
- 파티션 삭제/추가가 빈번한 경우
Global Index (글로벌 인덱스)
- 파티션과 상관없이 전체 데이터를 아우르는 인덱스
특징
- 파티션 키가 아닌 컬럼으로도 빠른 조회 가능
- Scatter-Gather 문제 없음
단점
- 파티션 삭제/추가 시 인덱스 재구축 비용이 큼
- 관리 복잡도 증가
사용 시점
- 다양한 컬럼으로 조회가 필요한 경우
- 파티션 키가 아닌 컬럼으로의 조회가 빈번한 경우
DBMS별 지원 여부
- Oracle
- Global Index를 지원하며
GLOBAL키워드로 생성 가능
- Global Index를 지원하며
- MySQL
- Global Index를 지원하지 않음
- MySQL의 파티션 테이블에 생성되는 모든 인덱스는 Local Index임
- 따라서 MySQL에서는 파티션 키가 포함되지 않은 쿼리는 필연적으로 모든 파티션을 스캔해야 함
- PostgreSQL
- 기본적으로 각 파티션은 개별 테이블로 취급되므로 Local Index 구조임
- 12 버전부터 파티션 테이블에 대한 인덱스 생성이 쉬워졌으나, 내부적으로는 여전히 각 파티션별 인덱스가 생성됨
Local vs Global Index 비교
파티셔닝 설계 가이드
파티션 키 선택
- 자주 쿼리 조건에 사용되는 컬럼
- 데이터 분산이 균등한 컬럼
- 시계열 데이터의 경우 날짜/시간 컬럼
- 카디널리티가 적절한 컬럼
파티션 개수 결정
- 너무 적으면 효과 제한적
- 너무 많으면 관리 복잡도 증가
- 파티션이 수천 개 이상으로 너무 많아지면 메타데이터 관리 비용 때문에 오히려 성능이 저하될 수 있음
- Open File Limit 등 시스템 리소스 제한에 영향받을 수 있음
- 일반적으로 10-50개 정도 권장
- 파티션당 데이터 크기 고려
파티셔닝 전략
- Range
- 시계열 데이터, 순차적 ID
- List
- 카테고리별 분류, 지역 코드
- Hash
- 균등 분산이 필요한 경우 (등호 검색 위주)
- Composite
- 복잡한 요구사항
파티셔닝 주의사항
- 파티션 키 변경은 테이블 재생성 필요
- 조인 성능에 영향 가능
- 인덱스 설계 복잡도 증가
- Local Index vs Global Index 선택이 중요함
- 파티션 프루닝이 작동하지 않으면 성능 저하
- Unique Key 제약
- 대부분의 DBMS에서 파티셔닝 테이블에
UNIQUE인덱스나Primary Key를 걸려면 반드시 파티션 키 컬럼이 포함되어야 함 - ex)
order_date로 파티셔닝한 경우PRIMARY KEY (order_id)는 불가능하고PRIMARY KEY (order_id, order_date)형태여야 함- 이 제약 때문에 PK 설계를 재검토해야 하는 경우가 많음
- 대부분의 DBMS에서 파티셔닝 테이블에
파티셔닝 모니터링
- 파티션별 데이터 분포 확인
- 파티션 프루닝 효과 측정
- 파티션별 쿼리 성능 모니터링
- 오래된 파티션 정리 계획 수립
결론
- 파티셔닝은 대용량 데이터 관리와 성능 최적화에 필수적임
- 파티션 프루닝을 활용하여 불필요한 파티션 스캔을 방지하는 것이 성능 향상의 핵심임
- 인덱스 전략(Local vs Global)과 Unique Key 제약을 고려한 설계가 중요함