개요
- 데이터베이스에서 쿼리를 실행할 때 데이터를 읽는 다양한 방식을 이해하는 것이 성능 최적화에 중요함
- 쿼리 옵티마이저가 쿼리 조건과 인덱스 상태를 분석하여 최적의 스캔 방식을 선택함
- 참고
- 이 포스팅의 용어는 엔터프라이즈 DB(
Oracle)에서 주로 사용되는 표준 용어를 기준으로 설명하지만 개념은 대부분의 RDBMS에 통용됨 - ex)
MySQL 8.0+의Skip Scan Range Access등
- 이 포스팅의 용어는 엔터프라이즈 DB(
Full Table Scan
- 테이블의 모든 데이터를 처음부터 끝까지 순차적으로 읽는 방식임
-
멀티블록 I/O를 사용하여 한 번에 여러 블록을 읽으며 인덱스가 없거나 조건에 맞는 데이터 비율이 높을 때 사용됨
-
동작 과정

특징
- 순차적 읽기로 디스크 I/O 효율적
- 멀티블록 I/O 사용
- 인덱스 오버헤드 없음
- 전체 데이터를 읽어야 하므로 대용량 테이블에서는 비효율적
사용 시점
- 인덱스가 없는 경우
- 조건에 맞는 데이터 비율이 높은 경우
- HDD 환경
- 전체의 10-20% 이상
- NVMe SSD 환경
- 선택도가 20-30%까지 올라가도 인덱스 스캔이 유리한 경우가 많음
- 저장 매체(HDD/SSD)에 따라 손익 분기점이 달라질 수 있음
- HDD 환경
HDD vs SSD I/O 특성 비교
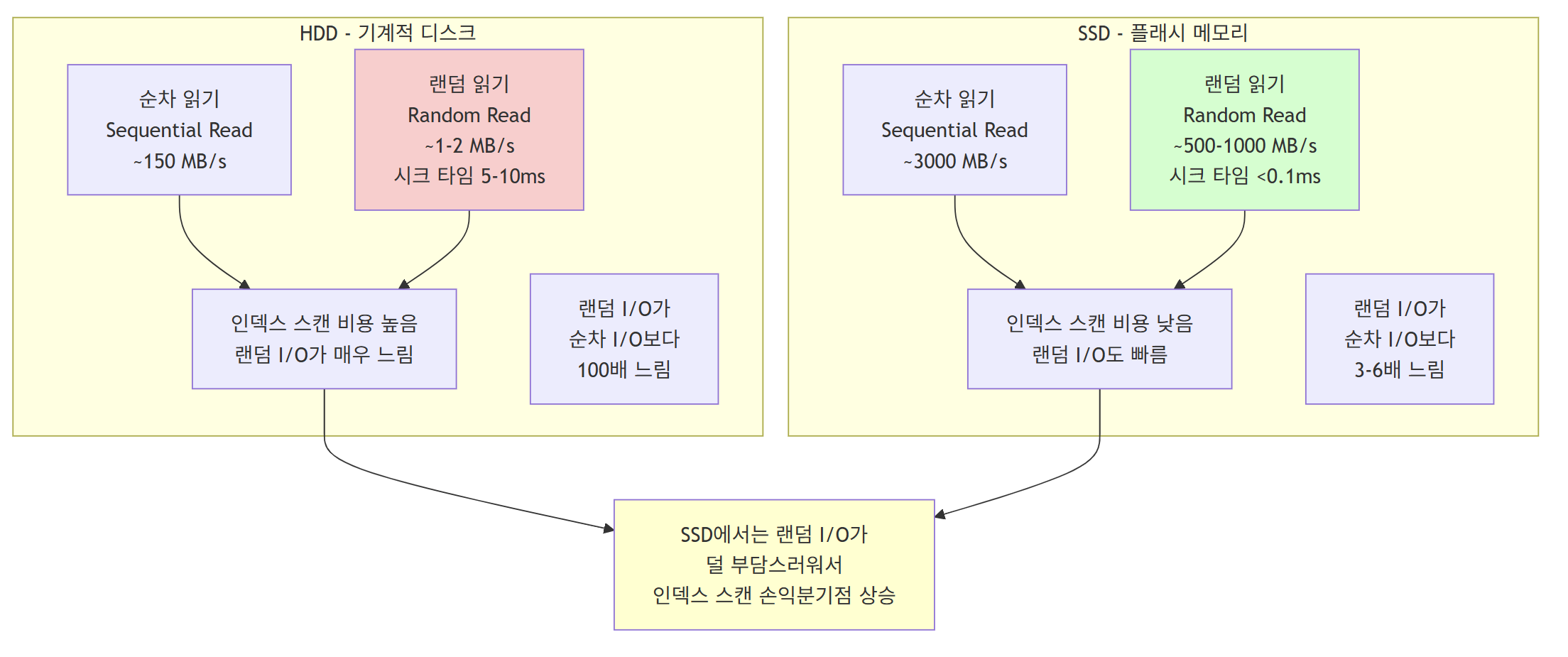
- HDD 환경의 특징
- 기계적 헤드 이동으로 인한 높은 시크 타임(5-10ms)
- 랜덤 I/O가 순차 I/O보다 100배 이상 느림
- 인덱스 스캔 시 랜덤 액세스 비용이 매우 높아서 선택도가 낮을 때만 유리함
- SSD 환경의 특징
- 전자적 접근으로 시크 타임이 거의 없음(<0.1ms)
- 랜덤 I/O가 순차 I/O보다 3-6배 정도만 느림
- 인덱스 스캔 시 랜덤 액세스 비용이 낮아서 선택도가 더 높아도 인덱스 스캔이 유리함
- 소량의 테이블
- 넓은 범위의 데이터 접근
- 옵티마이저가 인덱스보다 효율적이라고 판단한 경우
최적화
- 파티셔닝을 통한 파티션 프루닝
- 병렬 처리 활용
- 테이블 통계 정보 최신화
Index Range Scan
- 인덱스의 특정 범위를 스캔하는 가장 일반적인 방식임
-
B+Tree 구조를 따라 조건을 만족하는 첫 번째 엔트리를 찾고 리프 노드를 스캔하며
ROWID를 통해 테이블 데이터에 접근함 -
동작 과정
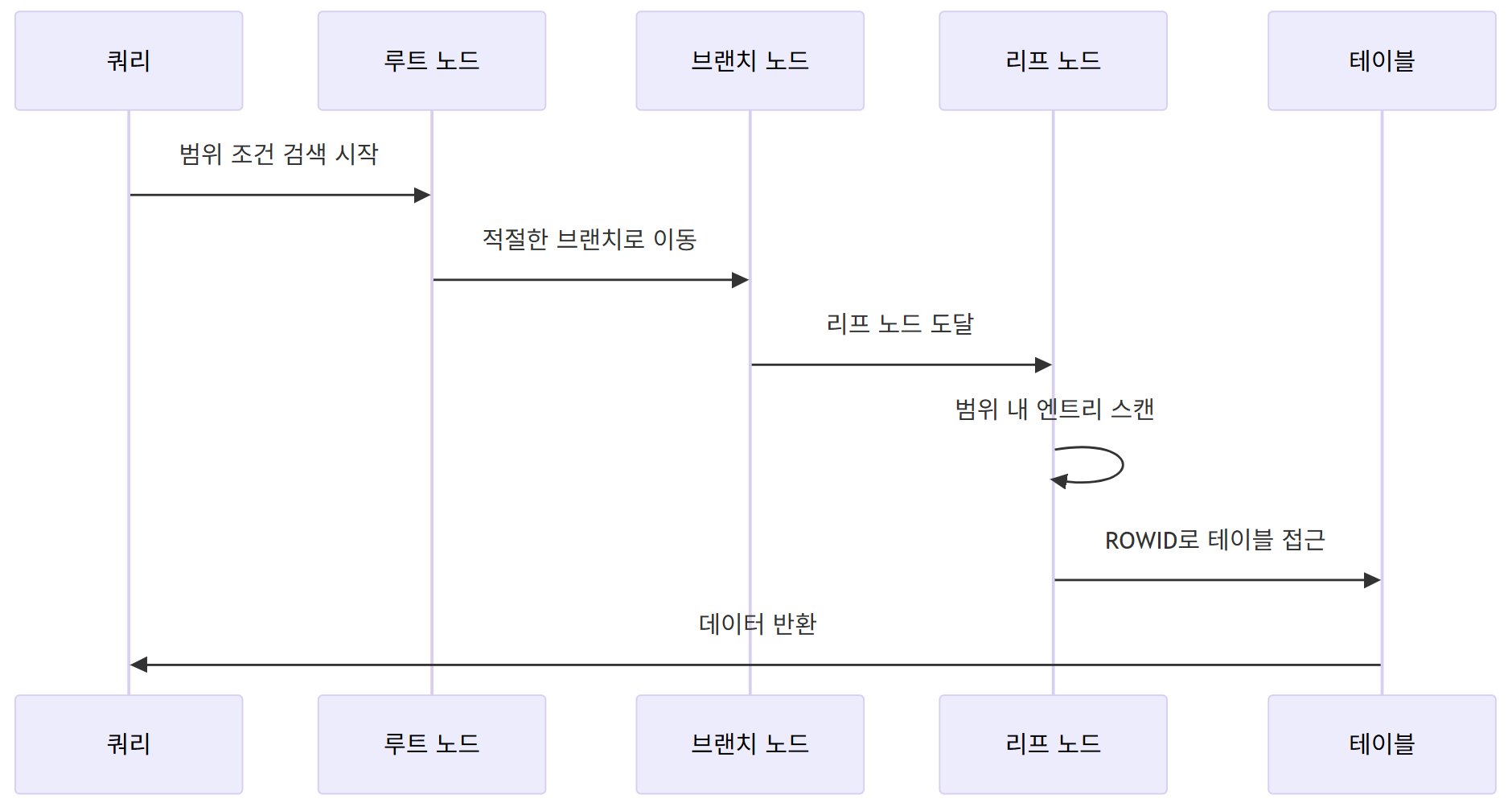
특징
- 선택도가 낮을 때 효율적
- 범위 조건에 최적화
- 정렬된 결과 제공
- 리프 노드가 연결되어 있어 범위 스캔에 효율적
사용 시점
WHERE절에 인덱스 컬럼 사용- 범위 조건(
>,<,BETWEEN등) - 선택도가 낮은 경우
- HDD 환경
- 전체의 5-10% 이하
- NVMe SSD 환경
- 선택도가 더 높아도 유리한 경우가 많음
- HDD 환경
- 등호 조건과 범위 조건이 혼합된 경우
성능 고려 사항
- 인덱스 스캔 후 테이블 랜덤 액세스 비용
- 선택도가 높으면 Full Table Scan보다 비효율적일 수 있음
- 랜덤 액세스 비용이 클수록 성능 저하
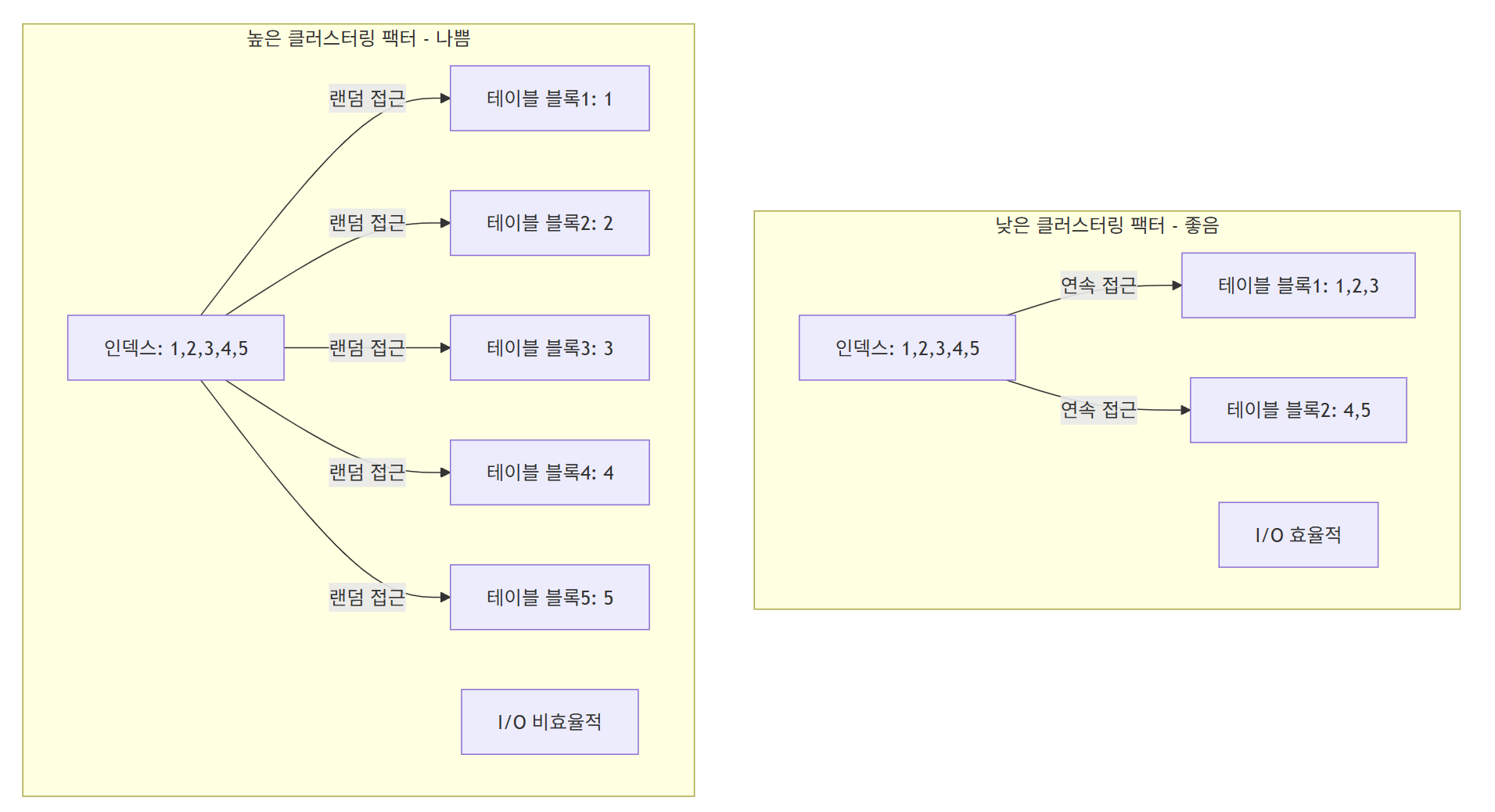
- 클러스터링 팩터(Clustering Factor)가 낮을수록 효율적
클러스터링 팩터
- 클러스터링 팩터는 인덱스 정렬 순서와 데이터 물리적 저장 순서의 일치 여부를 나타냄
- 낮은 클러스터링 팩터(좋은 경우)
- 인덱스 순서와 테이블 물리적 순서가 일치
- 연속된 인덱스 엔트리가 같은 데이터 블록에 위치
- 랜덤 액세스 비용이 낮음
- 높은 클러스터링 팩터(나쁜 경우)
- 인덱스 순서와 테이블 물리적 순서가 불일치
- 연속된 인덱스 엔트리가 서로 다른 데이터 블록에 분산
- 랜덤 액세스 비용이 높음
Index Full Scan
- 인덱스 전체를 처음부터 끝까지 읽는 방식으로 테이블이 아닌 인덱스를 스캔함
- 결과 집합의 순서가 보장되며 Single Block I/O를 사용함
- B+Tree의 논리적 순서(Linked List)를 따라 순차적으로 스캔함
특징
- 인덱스 전체 스캔
- 정렬된 결과 보장
- Single Block I/O
- 논리적 순서를 따라 한 블록씩 읽음
- 테이블 접근 필요 시 각 엔트리마다 랜덤 액세스
사용 시점
- 인덱스 컬럼만 조회하는 경우
ORDER BY가 인덱스 순서와 일치하는 경우- 인덱스 선행 컬럼이
WHERE절에 없는 경우
Index Fast Full Scan
- 인덱스 세그먼트 전체를 스캔하지만 인덱스 구조를 따르지 않음
- 멀티블록 I/O와 병렬 스캔이 가능하며 결과 집합 순서가 보장되지 않음
- 중요
Index Full Scan과의 결정적 차이는 Single Block I/O (논리적 순서) vs Multi Block I/O (물리적 순서)임
- 장점
- Full Table Scan보다 빠름(인덱스가 테이블보다 작은 경우)
- 멀티블록 I/O로 효율적
특징
- 인덱스 구조 무시
- B+Tree의 논리적 순서(Linked List)를 따르지 않고 물리적 블록을 통째로 읽음
- 멀티블록 I/O 사용
- 병렬 스캔 가능
- 순서 보장 안 됨
사용 조건
- 쿼리에 필요한 모든 컬럼이 인덱스에 포함
ORDER BY가 필요 없는 경우
Index Fast Full Scan vs Index Full Scan 비교

Index Skip Scan
- 복합 인덱스의 선행 컬럼을 조건에 사용하지 않아도 인덱스를 활용하는 기법임
-
인덱스의 distinct 값들을 건너뛰며 스캔하여 선행 컬럼의 카디널리티가 낮을 때 효과적임
-
동작 원리
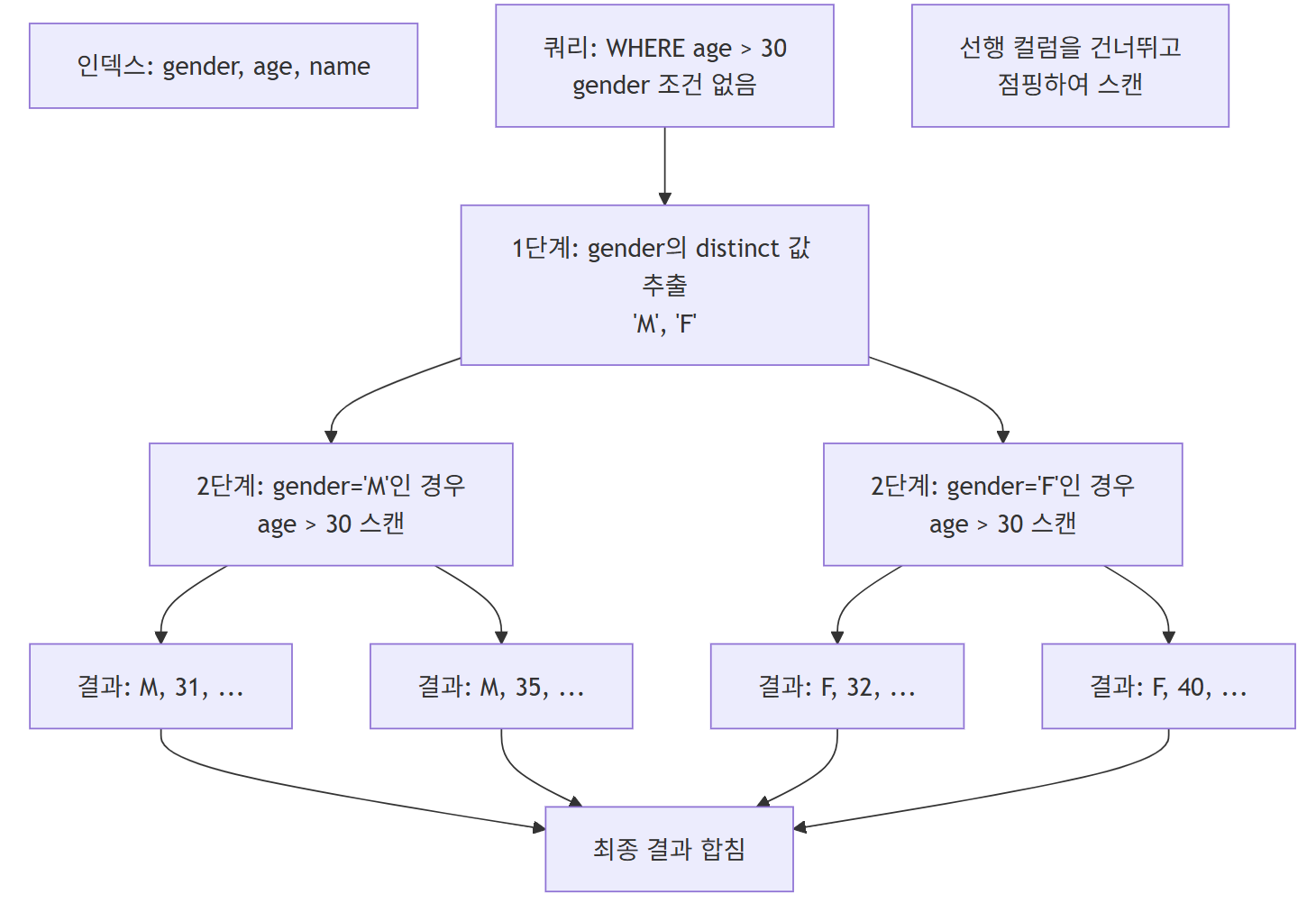
특징
- 선행 컬럼 없이도 인덱스 활용
- 낮은 카디널리티 선행 컬럼에 효과적
-
인덱스 distinct 값 스캔
- ex)
- 인덱스 - gender, age, name
-
쿼리 -
WHERE age > 30(gender 조건 없음) - Skip Scan 동작
- gender의 각 distinct 값(‘M’, ‘F’)에 대해
- 해당 gender 값과 age > 30 조건으로 인덱스 스캔
제한 사항
PostgreSQL- 수동 구현 필요(
WITH RECURSIVE)
- 수동 구현 필요(
MySQL- 8.0 이전
GROUP BY최적화(Loose Index Scan)에서만 제한적 사용
- 8.0 이후
Skip Scan Range Access도입으로 일반WHERE절에서도 지원- 범위 검색 쿼리에서 선행 컬럼 없이도 인덱스 활용 가능
- ex)
1 2 3 4
-- 인덱스 - gender, age, name -- MySQL 8.0+에서 Skip Scan 사용 가능 SELECT * FROM users WHERE age > 30; -- EXPLAIN 결과 - type=range, key=idx_gender_age_name, Extra=Using where; Using index for skip scan
- 8.0 이전
Index-Only Scan
- 테이블 접근 없이 인덱스만으로 쿼리를 처리하는 방식임
- 쿼리에 필요한 모든 컬럼이 인덱스에 포함되어야 함
- DBMS별 구현 차이
PostgreSQLVisibility Map을 통해 힙 영역 접근을 최소화함
MySQL InnoDBUndo Log를 통해 MVCC를 처리하므로 커버링 인덱스만으로도 충분히 Index-Only Scan(Using index)이 가능함
- 장점
- 랜덤 액세스 제거로 성능 향상
- 디스크 I/O 최소화
- 메모리 효율적
- 대량 데이터 조회 시 큰 성능 차이
1 2 3
-- 인덱스 - user_id, email, name -- 커버링 인덱스로 Index-Only Scan 가능 SELECT email, name FROM users WHERE user_id = 123;
Index-Only Scan vs 일반 Index Scan 비교
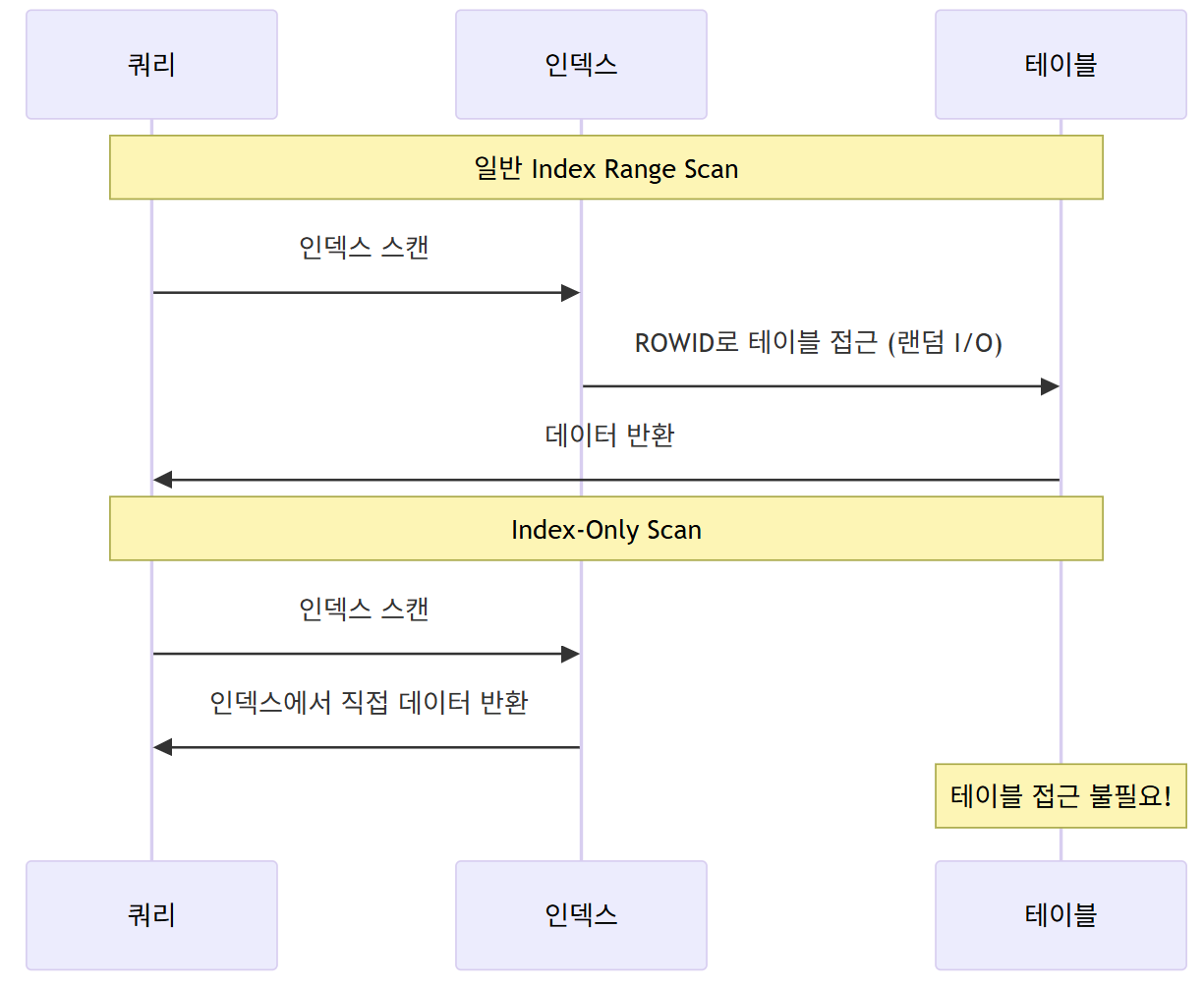
특징
- 테이블 접근 불필요
- 커버링 인덱스와 함께 사용
- 최고의 성능 제공
- 랜덤 액세스 비용 제로
조건
- 쿼리에 필요한 모든 컬럼이 인덱스에 포함
WHERE절 조건이 인덱스 컬럼 사용SELECT절 컬럼이 인덱스에 포함PostgreSQL의 경우Visibility Map을 통한 힙 접근 최소화MySQL InnoDB의 경우 커버링 인덱스만으로도 가능
스캔 방식 선택 기준
- 옵티마이저가 쿼리 비용을 계산하여 최적의 스캔 방식을 선택함
- 핵심
- 결국 I/O를 줄이는 것이 핵심임
- Random Access 최소화
- Sequential Read 극대화
비용 계산 요소
- 선택도
- 조건을 만족하는 데이터 비율
- 인덱스 크기
- 인덱스가 테이블보다 작으면 유리
- 클러스터링 팩터
- 인덱스 순서와 테이블 물리적 순서의 일치도
- 통계 정보
- 최신 통계 정보가 중요
스캔 방식 비교표
| 스캔 방식 | 테이블 접근 | 순서 보장 | I/O 타입 | 사용 조건 |
|---|---|---|---|---|
| Full Table Scan | 필요 | 없음 | 멀티블록 | 선택도 높음, 인덱스 없음 |
| Index Range Scan | 필요 | 있음 | 랜덤 | 선택도 낮음, 범위 조건 |
| Index Full Scan | 필요 | 있음 | 싱글블록 | 인덱스 컬럼만 조회 |
| Index Fast Full Scan | 불필요 | 없음 | 멀티블록 | 인덱스만으로 처리 가능 |
| Index-Only Scan | 불필요 | 있음 | 싱글블록 | 커버링 인덱스 |
최적화 팁
EXPLAIN PLAN으로 실행 계획 확인- 통계 정보를 정기적으로 갱신
- 인덱스 사용 여부 모니터링
- 불필요한 인덱스 제거
- 커버링 인덱스 설계로 Index-Only Scan 유도
결론
- 스캔 방식은 쿼리 옵티마이저가 자동 선택하지만 인덱스 설계가 성능을 결정함
- Index-Only Scan을 활용하기 위한 커버링 인덱스 설계가 성능 최적화의 핵심임
- 결국 I/O를 줄이는 것이 핵심이며 Random Access 최소화와 Sequential Read 극대화가 모든 스캔 방식의 최적화 목표임