학습 개요
- R은 자료 처리, 통계 분석, 그래 픽스 분야 등에 탁월한 기능을 가지고 있는 무료 통계 시스템임
- 대화형 프로그래밍 언어를 기반으로 다양한 통계 분석 함수 및 그래프 함수들을 포함하고 있음
- R을 이용하여 데이터를 읽고, 처리하는 방법을 알아보고, 기술 통계량을 구하는 법, 히스토그램 등 기본적인 통계 그래프를 그리는 방법을 알아보도록 함
학습 목표
- R 사용법을 익힐 수 있음
- 데이터를 읽어 들이는 방법을 이해할 수 있음
- 행렬 연산 방법을 설명할 수 있음
- 기술 통계량을 구할 수 있음
- 통계 그래프를 그릴 수 있음
강의록
R 소개 및 다운로드
R의 소개
- 통계 소프트웨어 시스템(statistical software system)
- 데이터를 효율적으로 처리하고 분석할 수 있으며, 다양한 통계적 분석과 그래프 등을 구현할 수 있는 통계 시스템
- 대화형 언어(interpreted language)
- 언어가 입력된 즉시 시행이 됨
- 객체 지향(object-oriented) 시스템
- R은 객체를 다룰 수 있도록 구성되어 있음
- 데이터, 변수, 행렬 등은 모두 객체이며, 객체는 연산자
<-, 또는=에 의해 생성 됨
R의 기능
- 자료 처리 기능
- 자료의 구성, 소팅, 결합 등이 프로그램 처리로 쉽게 이루어짐
- 자료 분석 기능
- 자료를 분석하기 위해 필요한 통계 분석 함수 및 분석 결과 제공 등이 다양함
- 언어 기능
- 함수 문을 쉽게 작성할 수 있으며, C언어 및 FORTRAN 언어 등과 인터페이스(Interface)가 가능
- 그래픽스 기능
- 대화형 그래픽스에 의한 자료 분석의 기능 및 분석 결과의 그래픽스 처리 기능이 뛰어남
R 다운 받기: www.r-project.org
R 다운 받기: Download

R 메뉴얼:

자료 읽기
설문지
- 설문
-
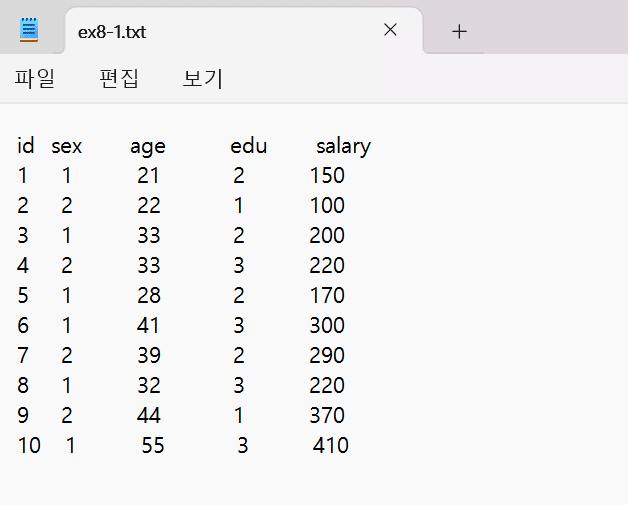
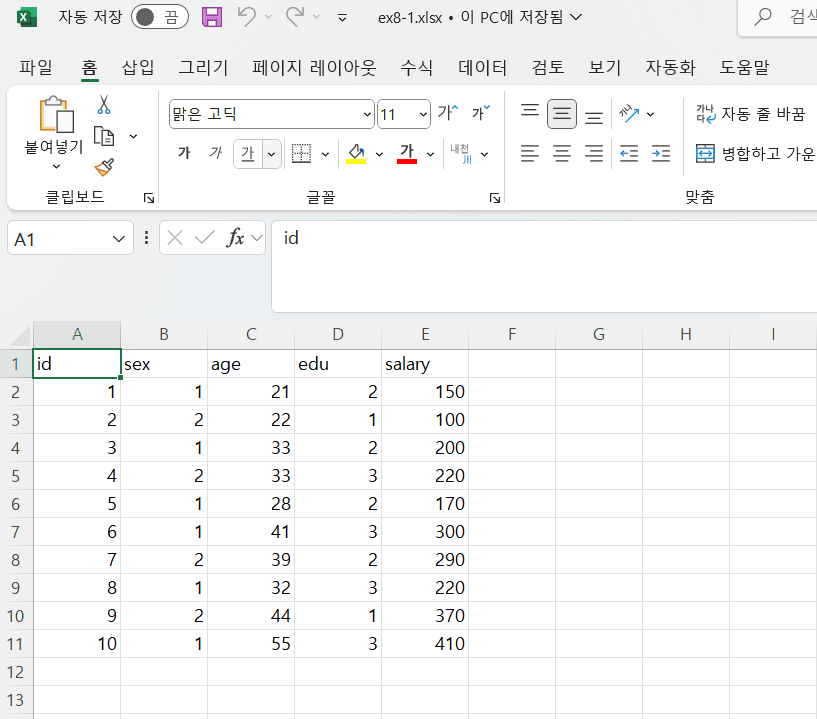
어느 집단에서 표본을 10명 추출하여 다음과 같은 4개 문항에 대하여 설문조사를 실시하였다.
일련번호 변수1 (성별) 변수2 (나이) 변수3 (교육정도) 변수4 (월수입) 1 1 21 2 150 2 2 22 1 100 3 1 33 2 200 4 2 33 3 220 5 1 28 2 170 6 1 41 3 300 7 2 39 2 290 8 1 32 3 220 9 2 44 1 370 10 1 55 3 410 - 귀하의 성별은?
- 남자
- 여자
- 귀하의 나이는? (단위: 세)
- 교육 정도는?
- 중졸 이하
- 고졸
- 대졸 이상
- 월 수입 (단위: 만원)
- 귀하의 성별은?
-
텍스트 자료 읽기: read.table, read.csv
-
ex-8-1.txt
-
ex-8-1.csv
1
2
3
ex8 = read.table("D:/01_KNOU/2025년도 1학기/데이터 정보 처리 입문/dataintro/ex8-1.txt", header=T) # 텍스트 파일 불러오기 (첫 행을 열 이름으로 사용)
# ex8 = read.csv("c:/data/dataintro/ex8-1.csv")
head(ex8) # 데이터의 처음 6행 출력
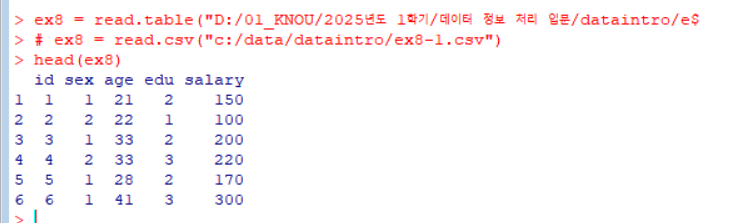
head = T- true 첫 번째 케이스는 변수로 되어있음
엑셀 자료 읽기: (package: xlsx, readxl)
-
Packages-Install → package(s)
엑셀 자료 읽기
-
xlsx 패키지 사용
1 2 3
library(xlsx) # xlsx 패키지 로드 ex8_xls = read.xlsx("D:/01_KNOU/2025년도 1학기/데이터 정보 처리 입문/dataintro/ex8-1.xlsx", 1) # ex8-1.xlsx 파일의 첫 번째 시트에서 데이터를 불러옴 head(ex8_xls, 3) # 데이터의 처음 3행 출력

-
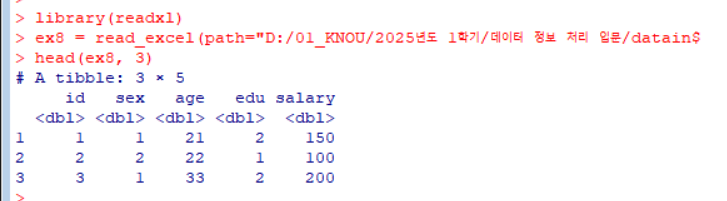
readxl 패키지 사용
1 2 3
library(readxl) # readxl 패키지 로드 ex8 = read_excel(path="D:/01_KNOU/2025년도 1학기/데이터 정보 처리 입문/dataintro/ex8-1.xlsx") # ex8-1.xlsx 파일 의 데이터를 읽어오기 head(ex8, 3) # 데이터의 처음 3행 출력
기술 통계 량 구하기
-
변수 월 급여(salary)의 평균 및 표준 편차 구하기
1 2 3 4 5 6 7
ex8 = read.csv("D:/01_KNOU/2025년도 1학기/데이터 정보 처리 입문/dataintro/ex8-1.csv") # CSV 파일 읽기 head(ex8, 3) # 데이터의 처음 3행 출력 names(ex8) # 열 이름 출력 attach(ex8) # 데이터 프레임의 변수를 직접 참조 가능하게 만듦 mean(ex8$salary) # salary 열의 평균 계산 sd(ex8$salary) # salary 열의 표준 편차 계산 summary(ex8$salary) # salary 열에 대한 요약 통계량 출력 (최솟값, 최댓값, 중앙값 등)

그룹 별 기술 통계 량 구하기
-
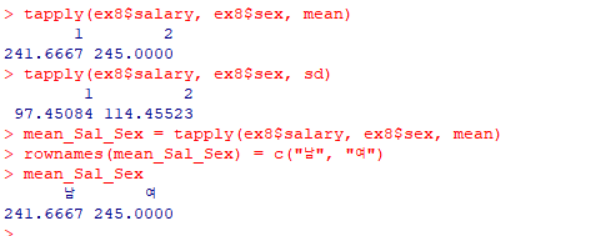
성별과 교육 정도 별로 월 급여(salary)의 평균 및 표준 편차 구하기
1 2 3 4 5 6
tapply(ex8$salary, ex8$sex, mean) # sex에 따라 salary의 평균 계산 tapply(ex8$salary, ex8$sex, sd) # sex에 따라 salary의 표준 편차 계산 mean_Sal_Sex = tapply(ex8$salary, ex8$sex, mean) # sex에 따른 salary의 평균을 mean_Sal_Sex에 저장 rownames(mean_Sal_Sex) = c("남", "여") # 행 이름을 "남"과 "여"로 설정 mean_Sal_Sex # 결과 출력
1 2 3 4
sd_sal_edu = tapply(ex8$salary, ex8$edu, sd) # edu에 따라 salary의 표준 편차 계산 sd_sal_edu # 결과 출력 rownames(sd_sal_edu) = c("중졸이하", "고졸", "대졸이상") # 학력 수준별 이름 설정 sd_sal_edu # 결과 출력

1 2 3 4 5 6 7 8
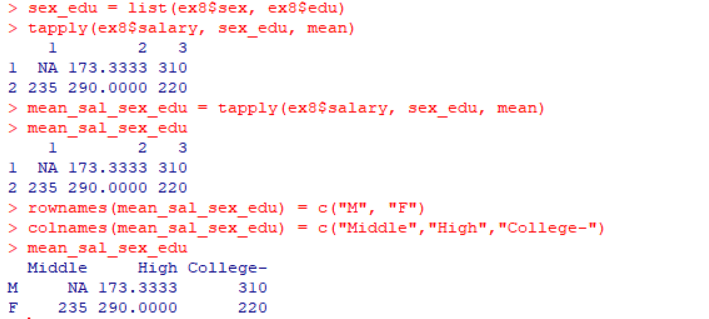
sex_edu = list(ex8$sex, ex8$edu) # 성별(sex)과 학력(edu)을 조합한 리스트 생성 tapply(ex8$salary, sex_edu, mean) # 성별과 학력별 salary의 평균 계산 mean_sal_sex_edu = tapply(ex8$salary, sex_edu, mean) # 결과를 mean_sal_sex_edu에 저장 mean_sal_sex_edu # 결과 출력 rownames(mean_sal_sex_edu) = c("M", "F") # 행 이름에 성별("M" = 남성, "F" = 여성) 설정 colnames(mean_sal_sex_edu) = c("Middle", "High", "College-") # 열 이름에 학력 수준 설정 mean_sal_sex_edu # 결과 출력
빈도 표 및 분할 표 구하기
- 성별과 교육 정도의 빈도 표 및 분할 표
-
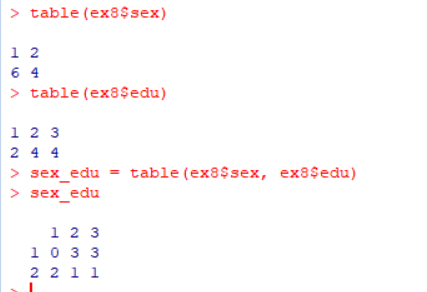
table()함수를 이용하여 빈도수를 계산1 2 3 4 5
table(ex8$sex) # 성별(sex) 변수의 빈도수 계산 table(ex8$edu) # 학력(edu) 변수의 빈도수 계산 sex_edu = table(ex8$sex, ex8$edu) # 성별(sex)과 학력(edu) 변수의 교차 빈도수 계산하여 sex_edu에 저장 sex_edu # sex_edu 출력
-
출력 표의 행/열 이름 설정
1 2 3 4
colnames(sex_edu) = c("중졸이하", "고졸", "대졸이상") rownames(sex_edu) = c("남", "녀") sex_edu

-
-
summary()함수는 최대 빈도값, 총 빈도수, 각 조합에 대한 빈도 요약을 제공1
summary(sex_edu) # 성별(sex)과 학력(edu)의 교차표(sex_edu)에 대한 요약 통계 출력

그래프 그리기
막대 그림 및 원 그림
-
교육(edu) 변수의 막대 그림 및 원 그림
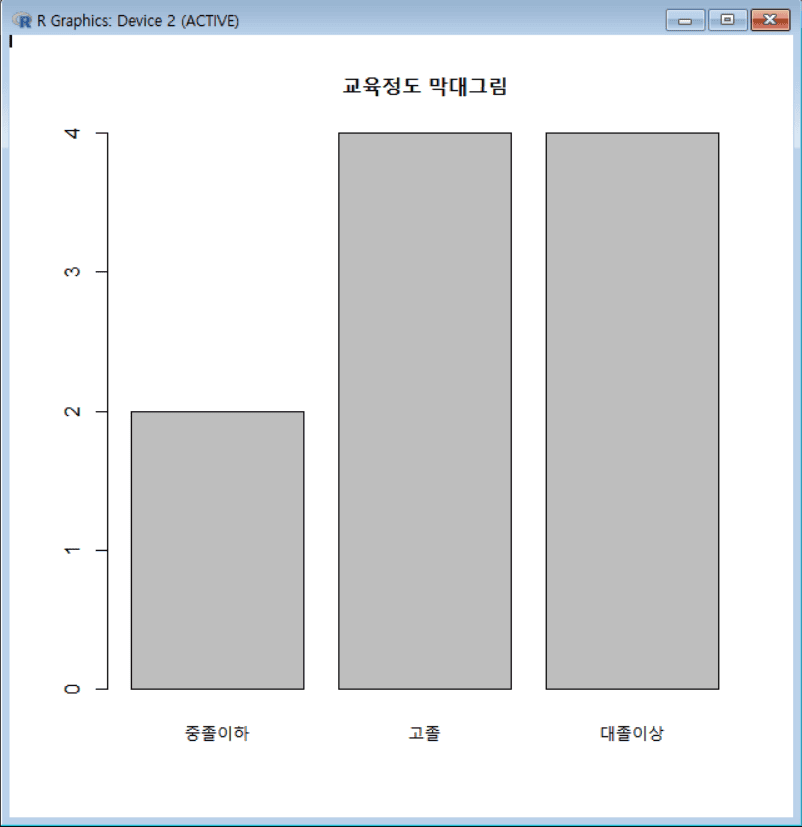
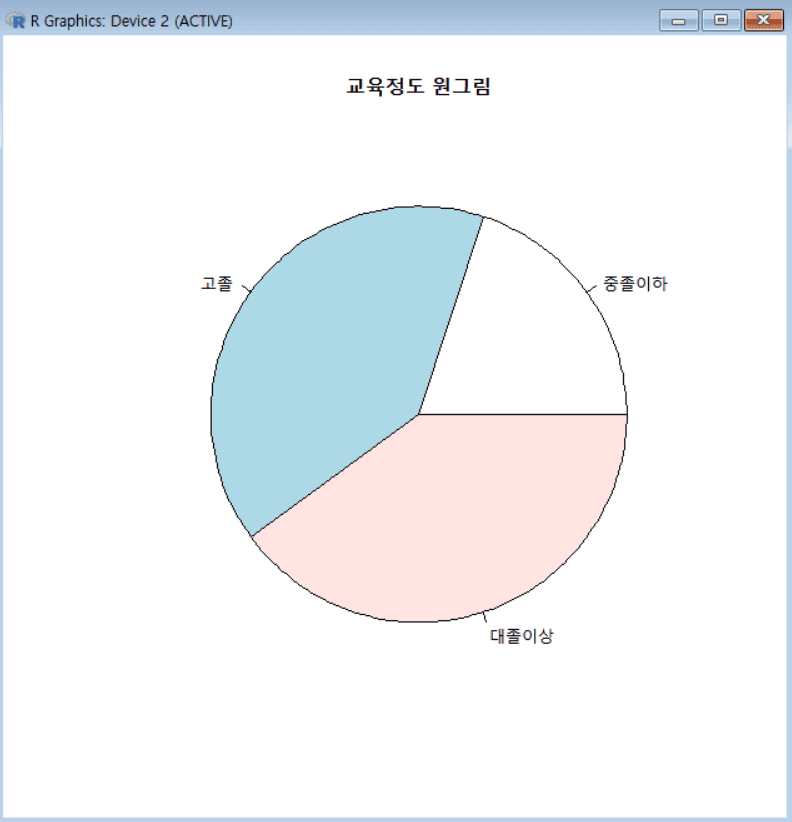
1 2 3 4 5 6 7 8 9 10
edu_freq = table(ex8$edu) # 학력(edu) 변수의 빈도를 계산하여 edu_freq에 저장 edu_freq # 결과(빈도수) 출력 rownames(edu_freq) = c("중졸이하", "고졸", "대졸이상") barplot(edu_freq) # 막대 그래프 생성 title("교육정도 막대그림") # 막대 그래프 제목 추가 pie(edu_freq) # 원형 그래프 생성 title("교육정도 원그림") # 원형 그래프 제목 추가 # pie(edu_freq, main="교육정도 원그림") # pie 함수에서 바로 main 파라미터로 제목을 설정 가능

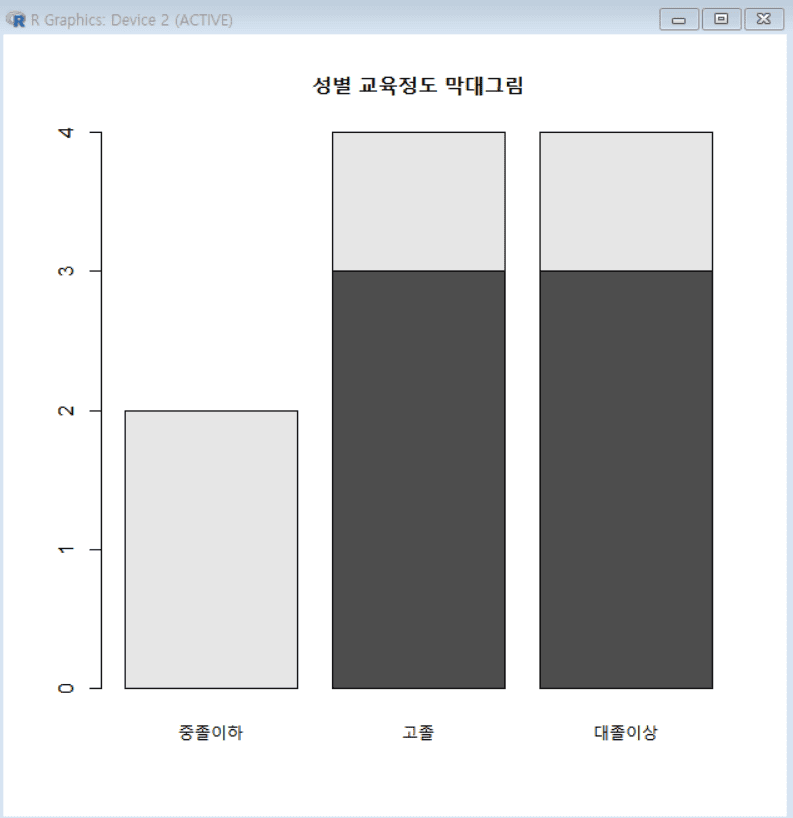
성별 구분 막대 그림
- 성별 구분 교육(edu) 변수의 막대 그림
1
2
3
4
5
6
7
8
sex_edu = table(ex8$sex, ex8$edu) # 성별(sex)과 교육 수준(edu)의 빈도를 교차표 형태로 계산
sex_edu # 교차표 출력
colnames(sex_edu) = c("중졸이하", "고졸", "대졸이상") # 교차표 열 이름(학력 수준) 설정
rownames(sex_edu) = c("남", "녀") # 교차표 행 이름(성별) 설정
barplot(sex_edu) # 성별 및 학력 수준에 따른 빈도 막대 그래프 생성
barplot(sex_edu, main = "성별 교육정도 막대그림") # 그래프에 제목 추가

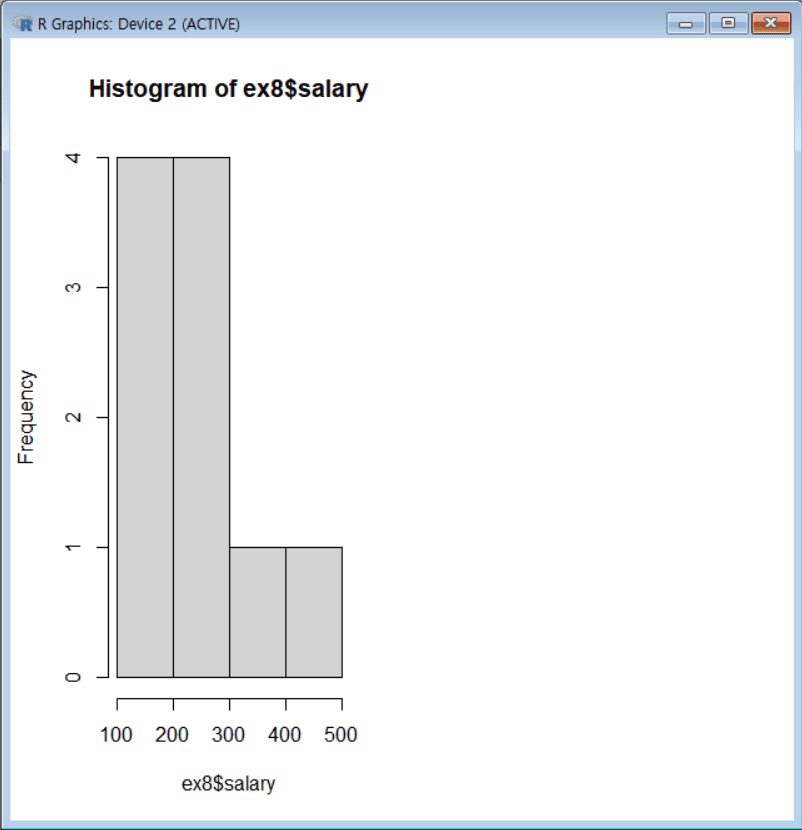
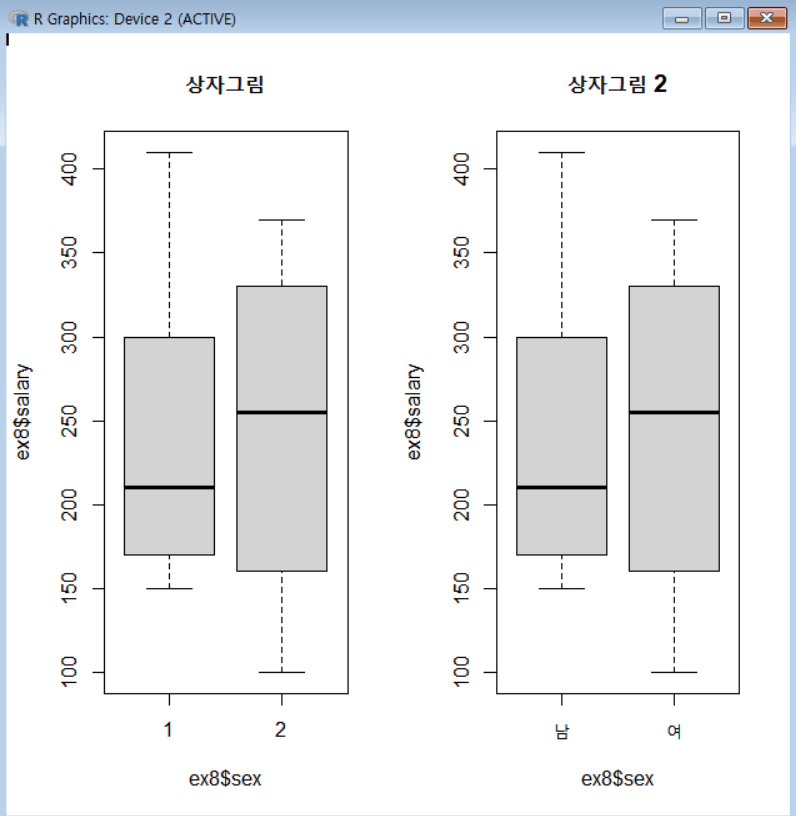
히스토그램, 줄기-잎 그림, 상자그림
-
월 급여(salary) 변수의 히스토그램, 줄기-잎 그림, 성별에 따른 상자 그림
1 2 3 4 5 6
hist(ex8$salary, nclass=4) stem(ex8$salary) par(mfrow=c(1,2)) boxplot(ex8$salary~ex8$sex, main="상자그림") ex8$sex = factor(ex8$sex, levels=c(1:2), labels = c("남", "여")) boxplot(ex8$salary~ex8$sex, main="상자그림 2")
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
# 히스토그램 생성 hist(ex8$salary, nclass = 4) # ex8$salary 변수의 히스토그램 생성 (계급 개수 4로 설정) # 줄기-잎 그림 생성 stem(ex8$salary) # ex8$salary 데이터의 줄기-잎 그림 출력 # 그래프를 한 화면에 1행 2열로 배치 par(mfrow = c(1, 2)) # 그래프를 한 화면에 두 개(1행 2열) 배치하도록 설정 # 성별에 따라 급여(salary)의 분포를 나타내는 상자그림(boxplot) 생성 boxplot(ex8$salary ~ ex8$sex, main = "상자그림") # ex8$salary 변수를 ex8$sex(성별)에 따라 구분하여 상자그림 생성 # 성별(sex) 변수를 의미 있는 라벨로 설정 ex8$sex = factor(ex8$sex, levels = c(1:2), labels = c("남", "여")) # 성별(sex) 데이터를 팩터로 변환하고 라벨(1 → "남", 2 → "여")을 설정 # 성별 라벨을 적용한 후 다시 상자그림 생성 boxplot(ex8$salary ~ ex8$sex, main = "상자그림 2") # ex8$salary 변수를 변환된 ex8$sex(성별) 기준으로 상자그림 생성
연속형 자료 그래프 : 줄기-잎 그림
- 줄기-잎 그림(stem-and-leaf plot)
- 분포의 대략적인 형태를 살펴보기 위하여 작성되는 그래프로 군집의 존재 여부, 집중도가 높은 구간, 대칭 성의 여부, 자료의 범위 및 산포, 특이 값의 존재 여부 등을 파악하는데 이용 됨
-
ex) 점수 자료: 54 57 55 23 51 64 90 51 52 43 15 10 82 74 54 78 37 73 52 48 41 33 52 30 41 51 18 39 46 28 53 44 46 56 28 58 29 58 67 35 25 38 61 53 23 73 69 47 41 45 77 56 89 28 54 99 10 43 35 24 21 23 67 14 53
1 2
score = scan("D:/01_KNOU/2025년도 1학기/데이터 정보 처리 입문/dataintro/score.txt") # score.txt 파일에서 데이터 읽기 stem(score) # 줄기-잎 그림 출력
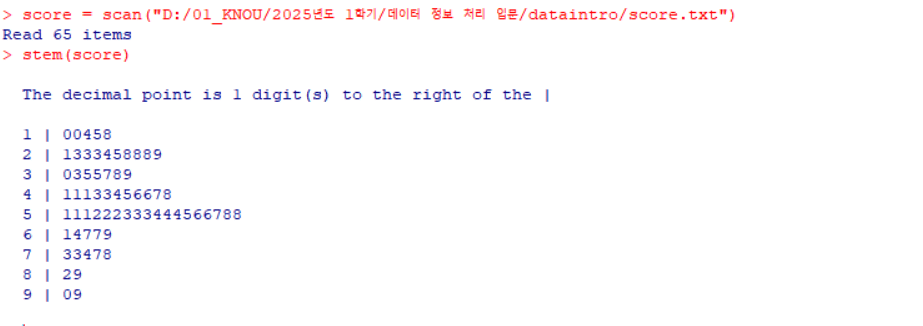
1 2
?stem # 줄기-잎 그림(stem 함수)에 대한 도움말 확인 stem(score, scale = 2) # 줄기-잎 그림 출력, scale = 2로 그림의 크기를 확장

연속 형 자료 그래프 : 상자 그림
1
2
3
4
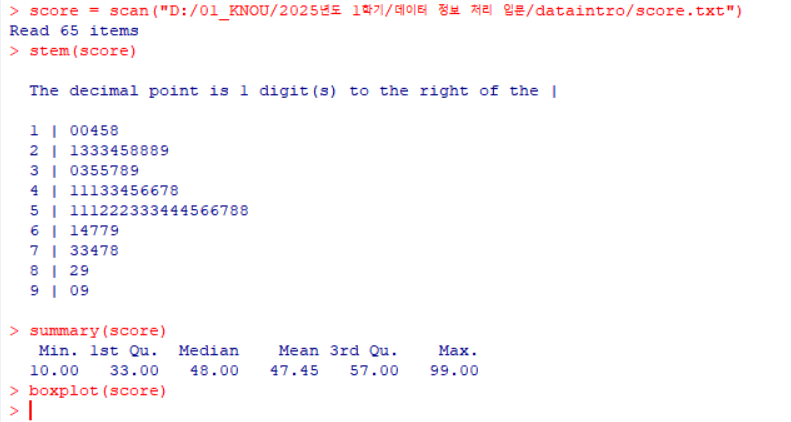
score = scan("D:/01_KNOU/2025년도 1학기/데이터 정보 처리 입문/dataintro/score.txt") # score.txt 파일에서 데이터를 읽어와 'score'에 저장
stem(score) # 줄기-잎 그림 출력하여 데이터 분포 요약
summary(score) # score 데이터의 기초 통계량(최소값, 최대값, 평균, 중앙값 등) 출력
boxplot(score) # score 데이터의 상자그림 출력으로 데이터의 분포와 이상값(outliers) 확인
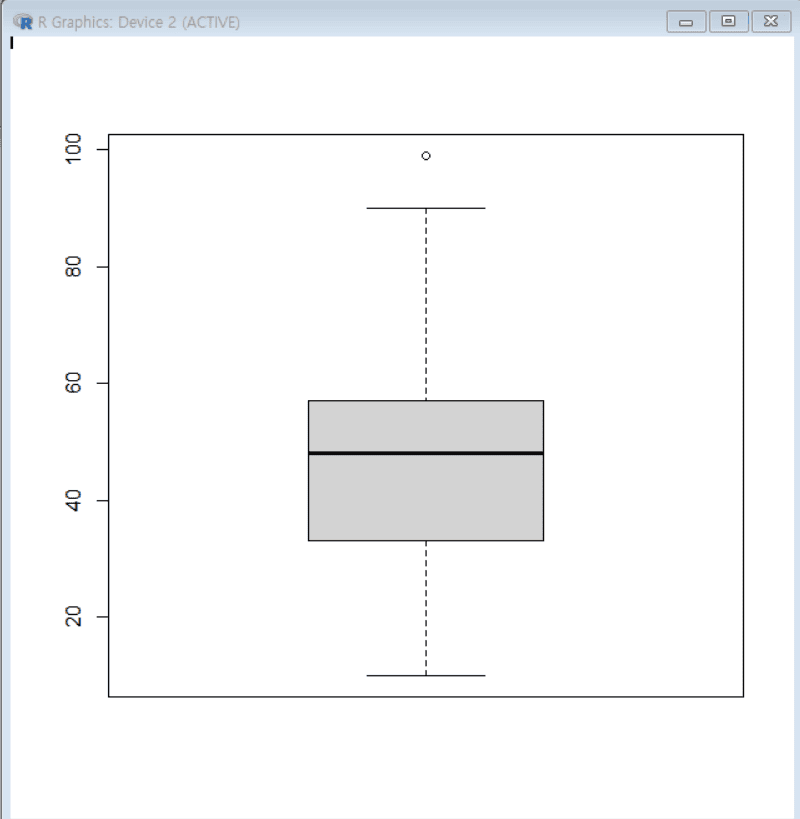
산점도 그리기
-
(age, salary) 산점도 그리기
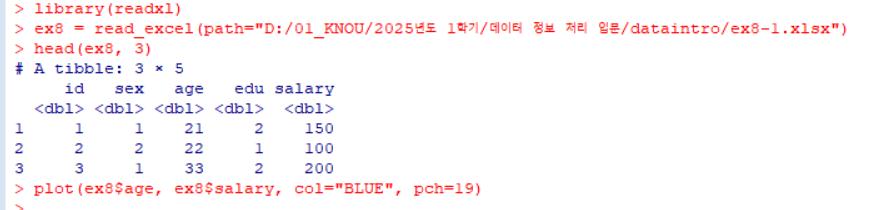
1 2 3 4
library(readxl) # Excel 파일을 읽어올 수 있는 readxl 패키지 로드 ex8 = read_excel(path="D:/01_KNOU/2025년도 1학기/데이터 정보 처리 입문/dataintro/ex8-1.xlsx") # ex8-1.xlsx을 읽어서 ex8 데이터프레임으로 저장 head(ex8, 3) # ex8 데이터프레임의 첫 3행 출력 plot(ex8$age, ex8$salary, col = "BLUE", pch = 19) # 나이(age)와 급여(salary)의 산점도 출력 (파란색 점, pch=19로 채워진 점 표시)
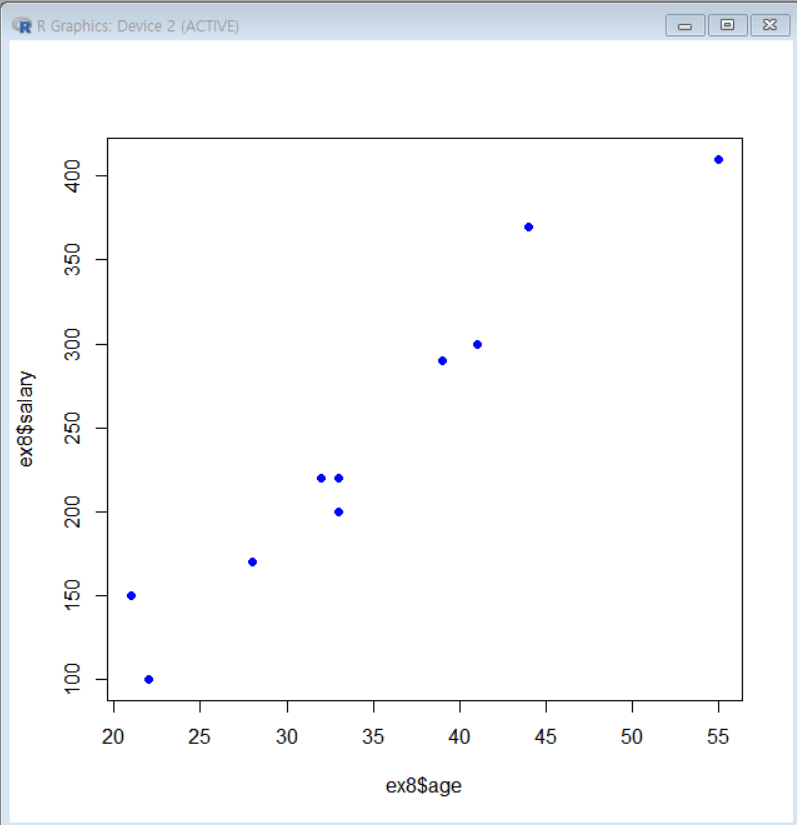
-
성별로 구분한 산점도 그리기
1 2 3 4 5
plot(ex8$age, ex8$salary, type = "n") # 빈 플롯 생성 points(ex8$age[ex8$sex == 1], ex8$salary[ex8$sex == 1], pch = "M", col = "BLUE") # 남성 데이터 추가 points(ex8$age[ex8$sex == 2], ex8$salary[ex8$sex == 2], pch = "F", col = "RED") # 여성 데이터 추가 legend("bottomright", legend = c("Male", "Female"), pch = c("M", "F"), col = c("BLUE", "RED")) # 범례 추가 legend(locator(1), legend = c("Male", "Female"), pch = c("M", "F"), col = c("BLUE", "RED")) # 마우스로 범례 위치 지정

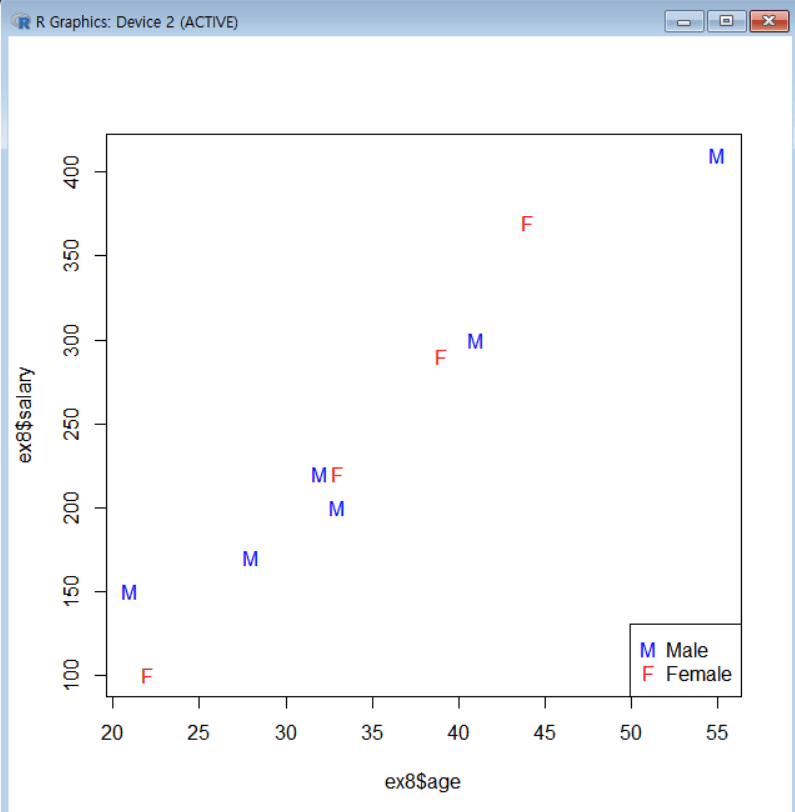
R 연산
스칼라와 벡터 연산
-
스칼라 연산
1 2 3 4 5 6 7
x = 4 # 변수 x에 값 4를 할당 y = 4 * x + 7 # y는 4*x + 7로 계산 y # y의 값을 출력 x <- 4 # 변수 x에 값 4를 할당 (화살표 방식) y <- 4 * x + 7 # y는 4*x + 7로 계산 y # y의 값을 출력
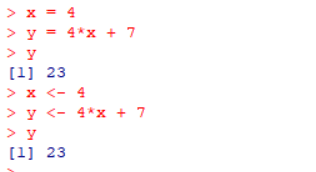
-
벡터 연산
1 2 3 4 5 6 7 8 9 10 11 12
x = c(-10:10) # -10부터 10까지의 정수를 생성하여 x에 저장 y = 4 * x + 7 # y는 x 값을 이용해 4*x + 7로 계산 y # y 값을 출력 x[3] # x의 세 번째 요소를 출력 x[1:5] # x의 1번째부터 5번째 요소를 출력 x1 = x[x < 0] # x 중에서 0보다 작은 값들만 추출하여 x1에 저장 x1 # x1 값을 출력 y = 4 * x1 + 7 # x1 값을 이용해 y를 계산 (4*x1 + 7) y # 새로운 y 값을 출력

data frame
1
2
3
4
5
6
7
8
9
10
11
12
13
x = c('red', 'green', 'blue') # 색상을 나타내는 문자열 벡터 생성
y = c(1, 2, 3) # 숫자 벡터 y 생성
z = c(4, 5, 6) # 숫자 벡터 z 생성
dframe = data.frame(x, y, z) # x, y, z 벡터를 결합해 데이터프레임 생성
dframe # 데이터프레임 출력
dframe[1, 1] # 데이터프레임의 1행 1열 값 출력
dframe[1, 2] # 데이터프레임의 1행 2열 값 출력
names(dframe) # 데이터프레임의 열 이름(컬럼 이름) 출력
dframe$y # 데이터프레임의 y 열(벡터 형태) 출력
dframe[, 2] # 데이터프레임의 2번째 열 출력 (y와 동일)

seq 함수: 일련의 값을 갖는 객체를 생성
1
2
3
4
5
6
x_seq = seq(-pi, pi, 1) # -π에서 π까지 1 간격으로 시퀀스 생성
x_seq # x_seq 출력
round(x_seq, 4) # x_seq 값을 소수점 4자리까지 반올림하여 출력
x1_seq = seq(-pi, pi, length = 10) # -π에서 π까지 10개 값으로 균등 분할한 시퀀스 생성
x1_seq # x1_seq 출력

행렬 연산
-
행렬 생성
1 2 3
x = c(1:12) # 1부터 12까지의 숫자를 가진 벡터 생성 x = matrix(x, ncol = 4, byrow = T) # 벡터 x를 4개의 열로 가지는 행렬로 변환, 행 단위로 채움 x # 행렬 x 출력

-
모든 원소 값이 동일한 상수인 행렬
1 2
x = matrix(1, nrow = 4, ncol = 3) # 값 1로 채워진 4x3 행렬 생성 x # 행렬 x 출력

-
서브 행렬 추출
1 2 3 4 5 6
x = c(1:12) # 1에서 12까지의 숫자를 가진 벡터 생성 x = matrix(x, ncol = 4, byrow = T) # 4개의 열로 구성된 행렬 생성 (행 단위로 채움) x # 행렬 x 출력 x[, c(1:3)] # x의 1~3열만 선택해 출력 x[c(1:3), -2] # x의 1~3행에서 두 번째 열을 제외하고 선택해 출력

- 행렬 연산 함수
ncol(x)- 열의 수
nrow(x)- 행의 수
t(x)- 전치 행렬
cbind(...)- 열을 더할 때 이용되는 함수
rbind(...)- 행을 더할 때 이용되는 함수
diag(x)- 대각 행렬
apply(x,m,fun)- 행 또는 열에 함수 적용
x %*% y- 두 행렬의 곱
solve(x)- 역행렬
-
행렬의 곱 및
apply함수 예1 2 3 4 5 6 7 8 9
x = c(1, 2, 3, 5, 6, 7) # 벡터 x 생성 x = matrix(x, ncol = 3, byrow = T) # 3개의 열로 구성된 행렬로 변환 (행 우선 방식) x # 행렬 x 출력 y <- c(1:4) # 벡터 y 생성 (1부터 4까지) y <- matrix(y, ncol = 2) # 2개의 열로 구성된 행렬로 변환 (기본적으로 열 우선 방식) y # 행렬 y 출력 t(x) %*% y # x의 전치된 행렬과 y를 행렬 곱셈 수행

-
t(x) %*% y
( C[i,j] ) 계산 예제 결과 값 첫 번째 행(1, 5)과 첫 번째 열(1, 2)의 내적: ( 11 + 52 = 1 + 10 ) 11 첫 번째 행(1, 5)과 두 번째 열(3, 4)의 내적: ( 13 + 54 = 3 + 20 ) 23 두 번째 행(2, 6)과 첫 번째 열(1, 2)의 내적: ( 21 + 62 = 2 + 12 ) 14 두 번째 행(2, 6)과 두 번째 열(3, 4)의 내적: ( 23 + 64 = 6 + 24 ) 30 세 번째 행(3, 7)과 첫 번째 열(1, 2)의 내적: ( 31 + 72 = 3 + 14 ) 17 세 번째 행(3, 7)과 두 번째 열(3, 4)의 내적: ( 33 + 74 = 9 + 28 ) 37
1 2
apply(x, 1, mean) # x 행렬의 각 행(row)에 대해 평균을 계산 apply(x, 2, mean) # x 행렬의 각 열(column)에 대해 평균을 계산

-
연습 문제
-
그룹 변수인 성별(sex)의 값에 따라 변수 salary의 평균(mean)을 구하는 명령은 ?
a.
tapply(salary, sex, mean) -
데이터 객체의 처음 6개의 케이스를 출력하고자 한다. R 명령은 ?
1
> ( b )(ex.data)
a.
head -
다음과 같은 텍스트 파일을 읽어 들이는 R 명령은 ?
1
ex.data = ( a )("c:/data/example.txt", header=T)
a.
read.table -
데이터 객체 ex.data의 변수들을 직접 사용하고자 한다. 유용한 명령은?
a.
attach(ex.data) -
package xlsx를 인스톨하였다. 이를 가동 시키기 위한 명령은?
a.
library(xlsx)