Role
PostgreSQL의 Role 모델
-
PostgreSQL은 사용자(User)와 그룹(Group)을 통합한 Role 개념을 사용함
- Role = User + Group의 개념 통합
-
Role의 특징
- 역할(Role)
- 데이터베이스 객체(테이블, 함수, 스키마 등)를 소유(Own)할 수 있음
- 권한 부여(Grant)
- 자신이 소유한 객체에 대해 다른 Role에 권한을 부여 가능
- 그룹 멤버십(Membership)
- Role을 다른 Role에 속하게 할 수 있음 (상속 개념)
- 역할(Role)
Role 타입
1
2
3
4
5
6
7
8
-- 로그인 가능한 유저 (WITH LOGIN)
CREATE ROLE db_user WITH LOGIN PASSWORD 'password';
-- 로그인 불가능한 그룹 (NOLOGIN)
CREATE ROLE read_only_group NOLOGIN;
-- 슈퍼유저 (모든 권한을 가진 관리자)
CREATE ROLE admin WITH SUPERUSER LOGIN PASSWORD 'password';
Role 속성
1
2
3
4
5
6
7
CREATE ROLE my_user
WITH
LOGIN -- 로그인 가능 여부
PASSWORD 'pass' -- 비밀번호
CREATEROLE -- 다른 Role 생성 가능
CREATEDB -- 데이터베이스 생성 가능
VALID UNTIL '2025-12-31'; -- 비밀번호 만료 날짜
Role 계층 구조와 권한 상속
1
2
3
4
5
6
7
8
9
10
11
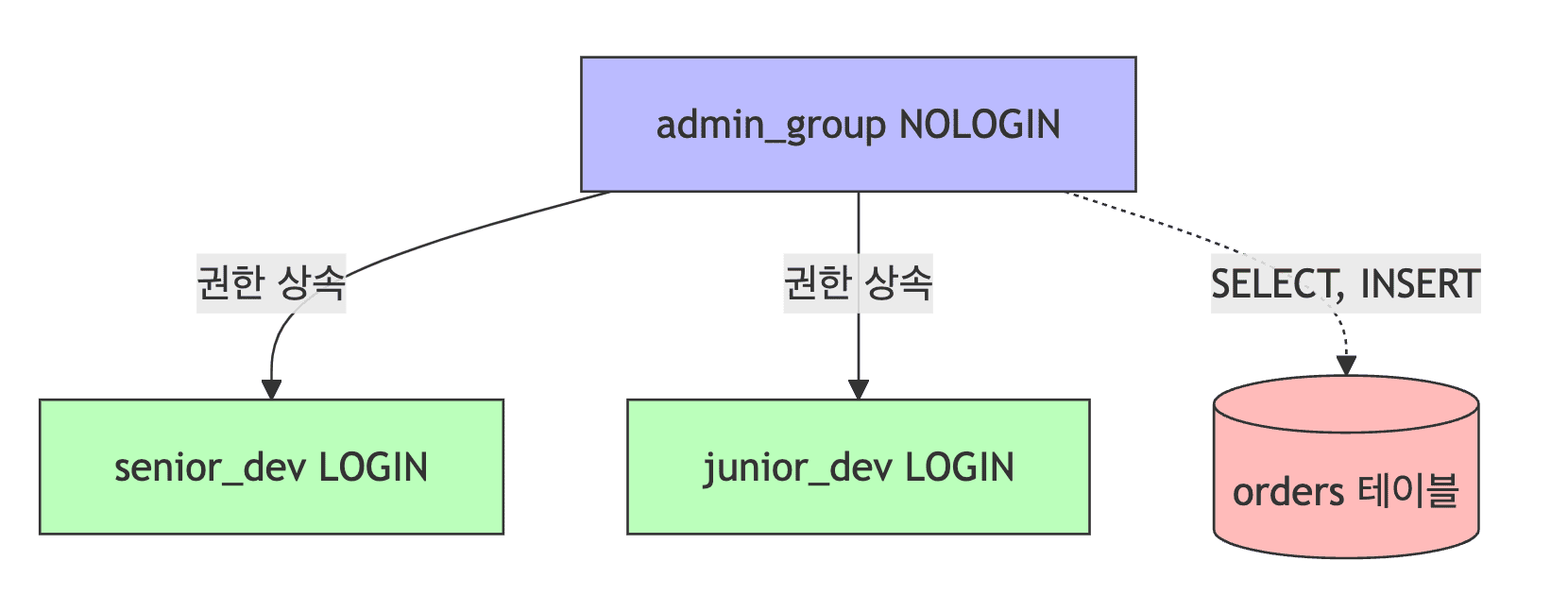
-- 기본 Role 생성
CREATE ROLE admin_group NOLOGIN;
CREATE ROLE senior_dev WITH LOGIN PASSWORD 'pass';
CREATE ROLE junior_dev WITH LOGIN PASSWORD 'pass';
-- Role을 그룹에 추가 (권한 상속 설정)
GRANT admin_group TO senior_dev;
GRANT admin_group TO junior_dev;
-- 그룹에 권한을 주면 모든 멤버가 권한을 갖게 됨
GRANT SELECT, INSERT ON TABLE orders TO admin_group;
- SET ROLE
- 로그인한 유저가 다른 Role로 전환 가능 (권한이 있다면)
1 2
SET ROLE admin_group; -- admin_group의 권한으로 작업 RESET ROLE; -- 원래대로 돌아가기
- 로그인한 유저가 다른 Role로 전환 가능 (권한이 있다면)
Schema
Schema의 역할
- 스키마는 데이터베이스 내의 네임스페이스(Namespace)임
-
같은 이름의 테이블을 여러 스키마에 만들 수 있음
구조 설명 public.userspublic 스키마의 users 테이블 analytics.usersanalytics 스키마의 users 테이블 archive.usersarchive 스키마의 users 테이블
Schema의 실제 목적
- 팀 단위 격리
frontend_team.users,backend_team.users(같은 이름이지만 다른 테이블)
- 애플리케이션 기능 분리
public.*(public API 용)internal.*(내부용)analytics.*(분석용)
- 접근 제어
- 각 스키마별로 다른 권한 부여 가능
Search Path
- 스키마를 지정하지 않고 테이블에 접근할 때, PostgreSQL은 search_path 순서대로 테이블을 찾음
1
2
3
4
5
6
7
8
9
-- 현재 search_path 확인
SHOW search_path;
-- Output: "$user", public
-- search_path 변경 (세션 단위)
SET search_path TO my_schema, public;
-- search_path 변경 (특정 유저에게 영구적용)
ALTER ROLE my_user SET search_path TO my_schema, public;

Schema 보안
- search_path에 여러 스키마가 있으면 SQL Injection 위험이 증가함
- 권장
- search_path에서 untrusted schema를 제거
1
SET search_path TO "$user", public;
- search_path에서 untrusted schema를 제거
제약 조건
- 제약조건은 테이블에 저장되는 데이터의 유효성을 보장함
제약 조건 종류
| 제약 조건 | 설명 | 예시 |
|---|---|---|
| Primary Key | 유일하고 NULL 불가 | product_id SERIAL PRIMARY KEY |
| Foreign Key | 다른 테이블 참조 | FOREIGN KEY (customer_id) REFERENCES customers(id) |
| UNIQUE | 값이 유일해야 함 (NULL 제외) | email VARCHAR(100) UNIQUE |
| NOT NULL | NULL 값 불가 | name VARCHAR(100) NOT NULL |
| CHECK | 특정 조건 만족 필요 | CHECK (price > 0) |
| EXCLUSION | 범위 충돌 방지 | EXCLUDE USING GIST (room_id WITH =, time_slot WITH &&) |
Primary Key
1
2
3
4
5
6
7
8
9
10
11
12
CREATE TABLE products (
product_id SERIAL PRIMARY KEY,
sku VARCHAR(20)
);
-- 복합 Primary Key
CREATE TABLE order_items (
order_id INT,
product_id INT,
quantity INT,
PRIMARY KEY (order_id, product_id)
);
- 동작
product_id = 1인 행이 이미 있으면, 또 다른product_id = 1행을 삽입하려 하면 UNIQUE VIOLATION 에러 발생
Foreign Key
1
2
3
4
5
6
7
8
CREATE TABLE orders (
order_id SERIAL PRIMARY KEY,
customer_id INT NOT NULL,
order_date DATE,
CONSTRAINT fk_orders_customer
FOREIGN KEY (customer_id)
REFERENCES customers(customer_id)
);
- 동작
orders.customer_id = 999를 삽입하려고 하는데,customers테이블에customer_id = 999가 없으면 FOREIGN KEY VIOLATION 에러customers테이블에서customer_id = 123행을 삭제하려는데,orders테이블에customer_id = 123이 있으면 삭제 실패
CHECK 제약 조건
1
2
3
4
5
6
7
CREATE TABLE products (
product_id SERIAL PRIMARY KEY,
price NUMERIC NOT NULL,
discount_price NUMERIC,
CONSTRAINT check_price_positive CHECK (price > 0),
CONSTRAINT check_discount_valid CHECK (discount_price < price OR discount_price IS NULL)
);
- 동작
price = -100을 삽입하려면 CHECK VIOLATION 에러
EXCLUSION 제약 조건
1
2
3
4
5
6
7
8
9
10
-- 정수형(Integer) 등 스칼라 데이터 타입의 GIST 인덱싱을 위해 필요
CREATE EXTENSION IF NOT EXISTS btree_gist;
-- 회의실 이중 예약 방지
CREATE TABLE conference_room_bookings (
booking_id SERIAL PRIMARY KEY,
room_id INT,
time_slot TSRANGE,
EXCLUDE USING GIST (room_id WITH =, time_slot WITH &&)
);
- 동작
- 같은
room_id&& (겹치는time_slot)인 행 추가 불가 room_id = 1,time_slot = '2024-01-01 10:00 ~ 11:00'이 있으면room_id = 1,time_slot = '2024-01-01 10:30 ~ 11:30'삽입 불가
- 같은
Partition
Partition이 필요한 이유
- 테이블의 행이 수억 개 이상으로 커지면, 전체 테이블을 스캔하는 쿼리가 매우 느려짐
-
파티셔닝을 통해 필요한 파티션만 스캔(Partition Pruning)하여 성능을 획기적으로 향상시킴
구분 파티션 없음 파티션 있음 테이블 크기 users: 1억 행 users_2024_01: 500만 행
users_2024_02: 510만 행
users_2024_03: 520만 행쿼리 SELECT * FROM users WHERE created_at = '2024-01-15'동일 스캔 범위 1억 행 모두 스캔 users_2024_01만 스캔 성능 느림 빠름 (약 20배 향상)
Partition 종류
-
Range Partitioning
-
날짜, 숫자 범위로 데이터를 나누는 방식
1 2 3 4 5 6 7 8 9 10 11 12 13
-- 로그 테이블을 월별로 파티션 CREATE TABLE logs ( log_id BIGSERIAL, log_date DATE NOT NULL, level VARCHAR(10), message TEXT ) PARTITION BY RANGE (log_date); CREATE TABLE logs_2024_01 PARTITION OF logs FOR VALUES FROM ('2024-01-01') TO ('2024-02-01'); CREATE TABLE logs_2024_02 PARTITION OF logs FOR VALUES FROM ('2024-02-01') TO ('2024-03-01');
-
-
List Partitioning
-
특정 값(카테고리, 지역)에 따라 데이터를 나누는 방식
```sql – 지역별로 고객 데이터 파티션 CREATE TABLE customers ( customer_id INT, region VARCHAR(20), name VARCHAR(100), email VARCHAR(100) ) PARTITION BY LIST (region);
CREATE TABLE customers_asia PARTITION OF customers FOR VALUES IN (‘KR’, ‘JP’, ‘CN’, ‘TH’);
CREATE TABLE customers_america PARTITION OF customers FOR VALUES IN (‘US’, ‘CA’, ‘MX’); ```
-
-
Hash Partitioning
-
데이터의 해시값을 기준으로 균등하게 분산
1 2 3 4 5 6 7 8 9 10
CREATE TABLE orders ( order_id BIGSERIAL, customer_id INT, amount NUMERIC ) PARTITION BY HASH (customer_id); CREATE TABLE orders_0 PARTITION OF orders FOR VALUES WITH (MODULUS 4, REMAINDER 0); CREATE TABLE orders_1 PARTITION OF orders FOR VALUES WITH (MODULUS 4, REMAINDER 1); CREATE TABLE orders_2 PARTITION OF orders FOR VALUES WITH (MODULUS 4, REMAINDER 2); CREATE TABLE orders_3 PARTITION OF orders FOR VALUES WITH (MODULUS 4, REMAINDER 3);
-
Partition Pruning
- 쿼리의 WHERE 절에 파티션 키가 있으면, PostgreSQL이 불필요한 파티션을 건너뜀
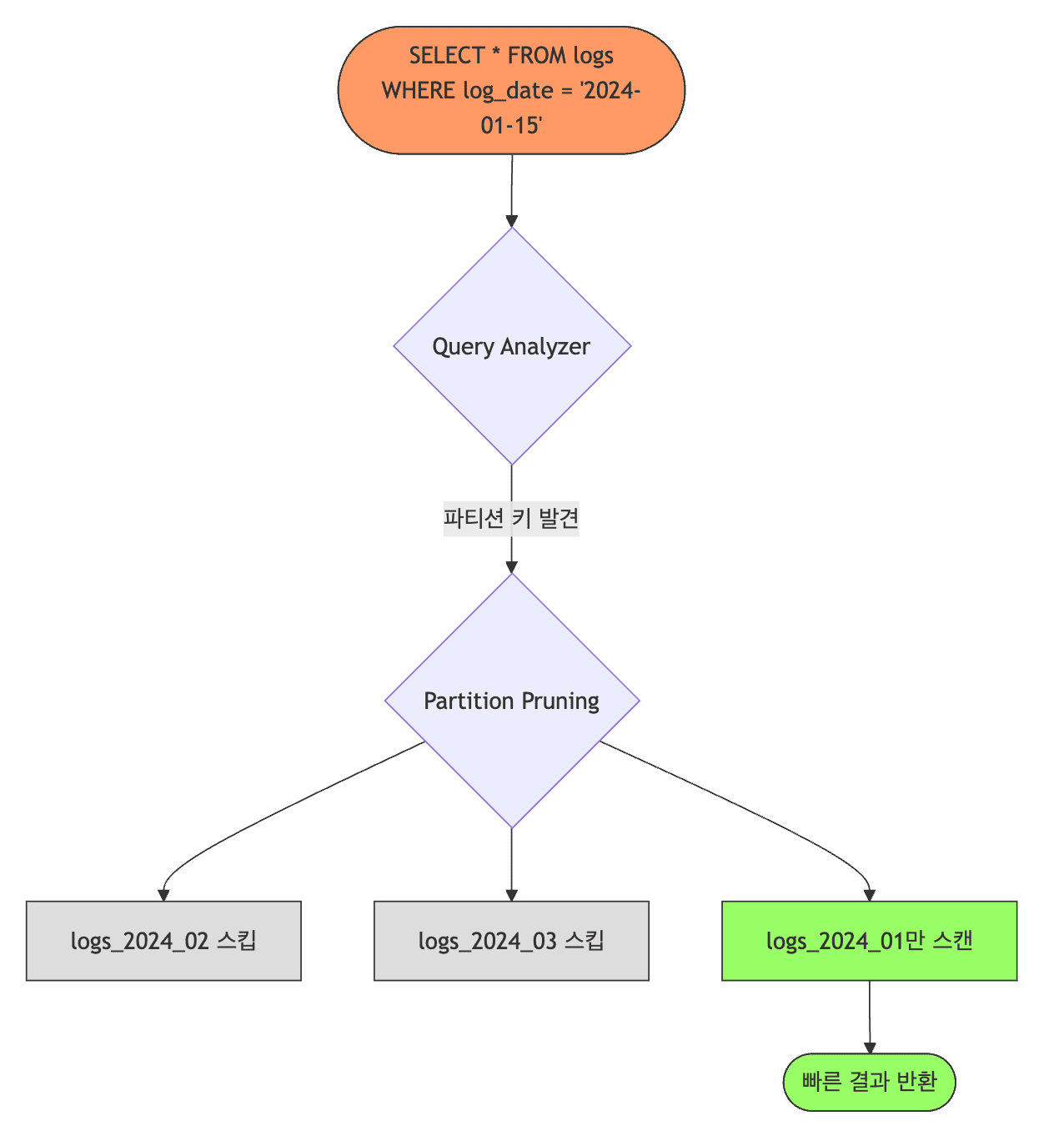
- 효율적 사용
1 2
EXPLAIN SELECT * FROM logs WHERE log_date = '2024-01-15'; -- → logs_2024_01만 스캔
- WHERE에 파티션 키 포함 → Partition Pruning 작동
- 비효율적 사용
1 2
EXPLAIN SELECT * FROM logs WHERE level = 'ERROR'; -- → logs_2024_01, logs_2024_02, ... 모두 스캔
- WHERE에 파티션 키 없음 → 모든 파티션 스캔
Partition 인덱싱
1
2
-- 부모 테이블에 인덱스 생성
CREATE INDEX idx_logs_date ON logs (log_date);
- PostgreSQL 11+에서는 자동으로 모든 자식 파티션에도 인덱스 생성됨
Partition 관리
1
2
3
4
5
6
-- 파티션을 일반 테이블로 분리 (아카이빙)
ALTER TABLE logs DETACH PARTITION logs_2023_01;
-- 이제 logs_2023_01은 독립적인 테이블
> **참고**: 운영 환경에서는 수동 관리보다 **pg_partman** 같은 확장 도구를 사용하여 파티션 생성 및 유지보수(Retention)를 자동화하는 것이 일반적입니다.
예시 시나리오
멀티테넌트 로그 시스템
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
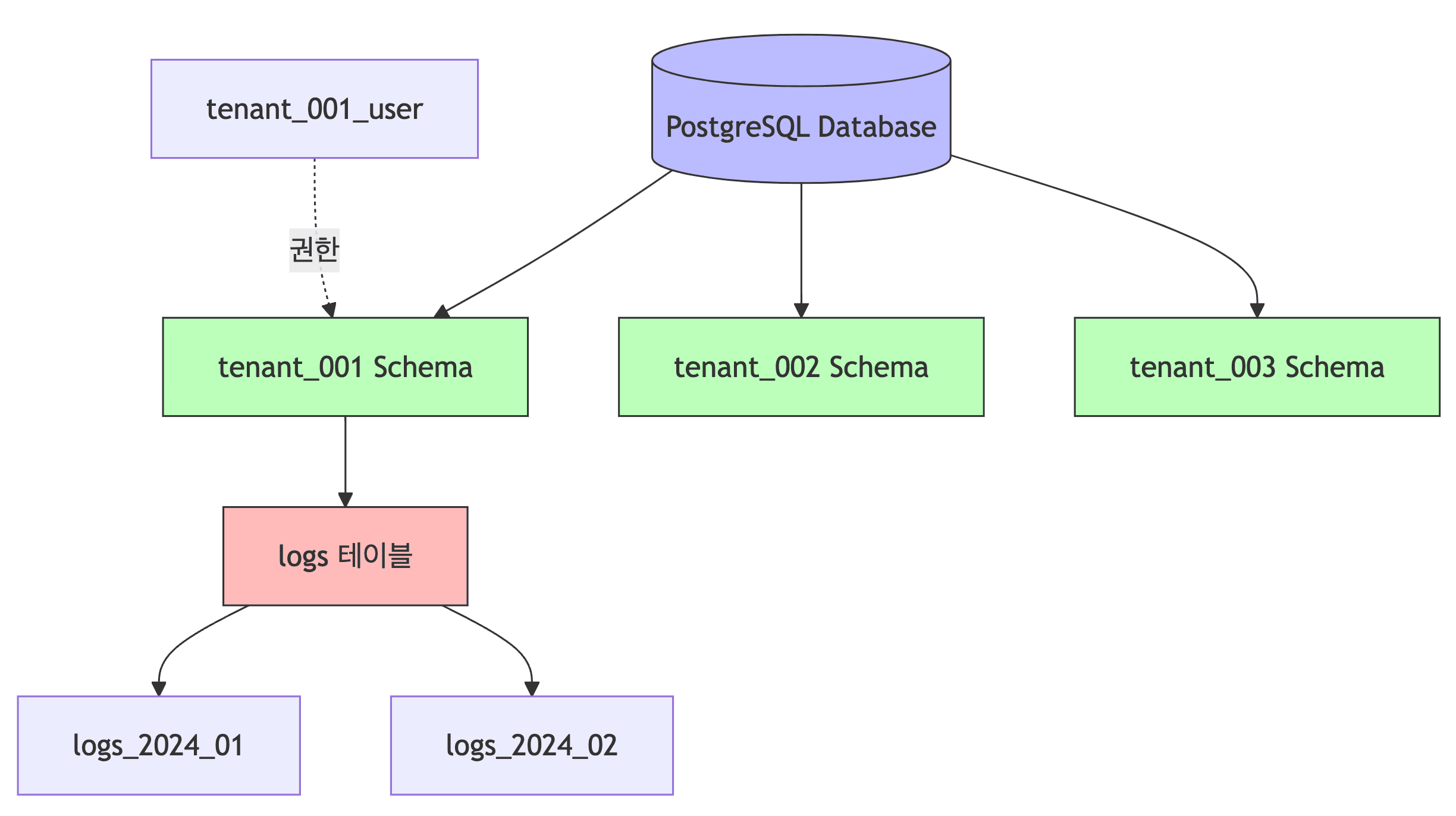
-- 테넌트별 스키마 생성
CREATE SCHEMA tenant_001;
CREATE SCHEMA tenant_002;
-- 권한 설정
CREATE ROLE tenant_001_user WITH LOGIN PASSWORD 'pass1';
GRANT USAGE ON SCHEMA tenant_001 TO tenant_001_user;
ALTER ROLE tenant_001_user SET search_path TO tenant_001, public;
-- 파티션된 로그 테이블 생성
CREATE TABLE tenant_001.logs (
log_id BIGSERIAL,
log_date DATE NOT NULL,
user_id INT,
action VARCHAR(50),
details JSONB,
CONSTRAINT pk_logs PRIMARY KEY (log_id, log_date)
) PARTITION BY RANGE (log_date);
CREATE TABLE tenant_001.logs_2024_01 PARTITION OF tenant_001.logs
FOR VALUES FROM ('2024-01-01') TO ('2024-02-01');
Tip: 파티션 테이블에 Unique나 PK를 설정하려면 반드시 파티션 키 컬럼(
log_date)을 포함해야 합니다. 포함하지 않으면 “unique constraint on partitioned table must include all partitioning columns” 에러가 발생합니다.
성능 개선 효과
| 구분 | 파티션 전 | 파티션 후 |
|---|---|---|
| 테이블 크기 | 10억 행 | 월별 파티션 (평균 8,300만 행) |
| 쿼리 시간 | 45초 (전체 스캔) | 2초 (Partition Pruning) |
| 성능 향상 | - | 22배 개선 |
체크리스트
프로덕션 배포 전
1
2
3
4
5
6
7
8
-- Role과 권한 확인
SELECT * FROM pg_user WHERE usesuper = true;
-- 파티션 설정 확인
SELECT schemaname, tablename FROM pg_tables WHERE tablename LIKE 'logs%';
-- Partition Pruning 작동 확인
EXPLAIN (ANALYZE) SELECT * FROM logs WHERE log_date = '2024-01-15';
정기 유지보수
- 월 1회
- 권한 감시
- 파티션 크기 확인
- 분기 1회
- 사용하지 않는 Role 정리
1
2
3
4
5
6
7
-- 파티션 크기 확인
SELECT
schemaname, tablename,
pg_size_pretty(pg_total_relation_size(schemaname||'.'||tablename)) AS total_size
FROM pg_tables
ORDER BY pg_total_relation_size(schemaname||'.'||tablename) DESC
LIMIT 20;
정리
| 개념 | 역할 | 주요 활용 |
|---|---|---|
| Role | 계정과 권한 관리 | 팀별, 직급별 접근 제어 |
| Schema | 네임스페이스 격리 | 멀티테넌트, 환경 분리 (dev/prod) |
| Constraint | 데이터 무결성 보장 | 비즈니스 규칙 강제 |
| Partition | 대규모 테이블 성능 최적화 | 로그, 시계열 데이터 관리 |