API 개발 고급 - 지연 로딩과 조회 성능 최적화
- 김영한님의 실전! 스프링 부트와 JPA 활용2 - API 개발과 성능 최적화 강의를 기반으로 주문 + 배송정보 + 회원을 조회하는 API를 4단계 버전으로 발전시키며, 지연 로딩으로 인한 성능 문제를 단계적으로 해결하는 과정을 정리함
전체 구조 개요

- V1에서 V4까지 단계적으로 성능 문제를 해결함
- V1 → 엔티티 직접 노출 (프록시 직렬화, 순환참조 문제)
- V2 → DTO 변환 (N+1 쿼리 문제)
- V3 → 페치 조인 최적화 (1번 쿼리로 해결)
- V4 → JPA에서 DTO 직접 조회 (추가 최적화)
도메인 연관관계
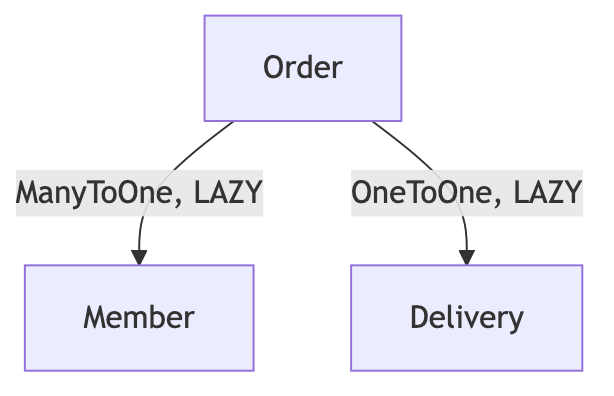
xToOne관계(ManyToOne,OneToOne)는 기본 fetch 전략이EAGER이므로, 반드시LAZY로 명시 설정해야 함- 지연 로딩을 기본으로 설정하고 성능 최적화가 필요한 곳에만 페치 조인을 사용하는 것이 원칙임
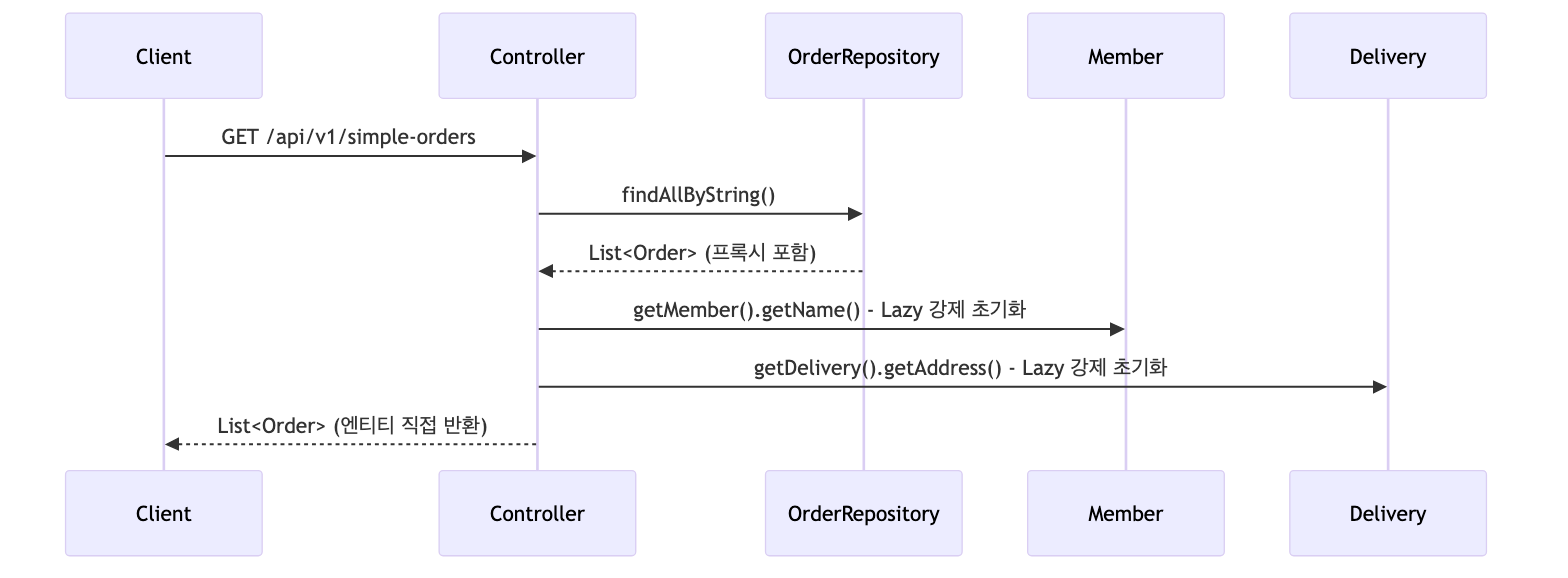
V1 - 엔티티 직접 노출
1
2
3
4
5
6
7
8
9
@GetMapping("/api/v1/simple-orders")
public List<Order> ordersV1() {
List<Order> all = orderRepository.findAllByString(new OrderSearch());
for (Order order : all) {
order.getMember().getName(); // Lazy 강제 초기화
order.getDelivery().getAddress(); // Lazy 강제 초기화
}
return all;
}
-
문제점
- Jackson 라이브러리는 프록시 객체를 JSON으로 직렬화하는 방법을 알지 못해 예외가 발생함
Hibernate5JakartaModule을 스프링 빈으로 등록해야 함- 양방향 연관관계에서 양쪽을 서로 호출하며 무한 루프가 발생하므로, 한쪽에 반드시
@JsonIgnore를 설정해야 함
- LAZY를 피하려고 EAGER로 변경하면 안 됨
- 연관관계가 필요 없는 경우에도 항상 데이터를 조회하게 되어 성능 문제가 발생하고 성능 튜닝이 매우 어려워짐
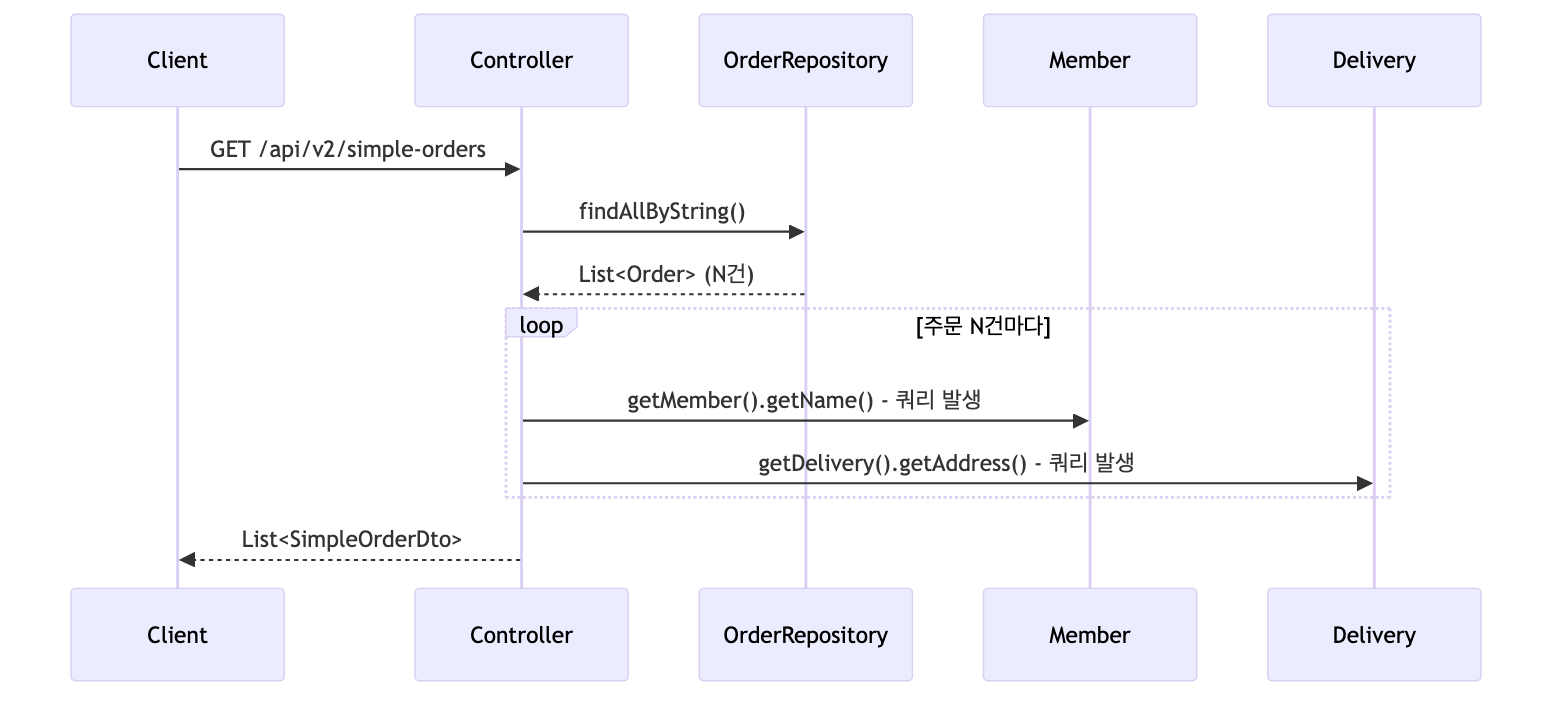
V2 - 엔티티를 DTO로 변환
1
2
3
4
5
6
7
@GetMapping("/api/v2/simple-orders")
public List<SimpleOrderDto> ordersV2() {
List<Order> orders = orderRepository.findAllByString(new OrderSearch());
return orders.stream()
.map(o -> new SimpleOrderDto(o))
.collect(toList());
}
- N+1 문제
- 주문이 N건이면 최악의 경우
1(주문 조회) + N(회원 조회) + N(배송 조회)번의 쿼리가 실행됨 - 동일한 엔티티가 영속성 컨텍스트에 이미 존재하는 경우에는 쿼리를 생략함
- 주문이 N건이면 최악의 경우
- 엔티티를 직접 노출하지 않는다는 점에서 V1보다 나은 방법이지만, 성능 문제는 그대로 존재함
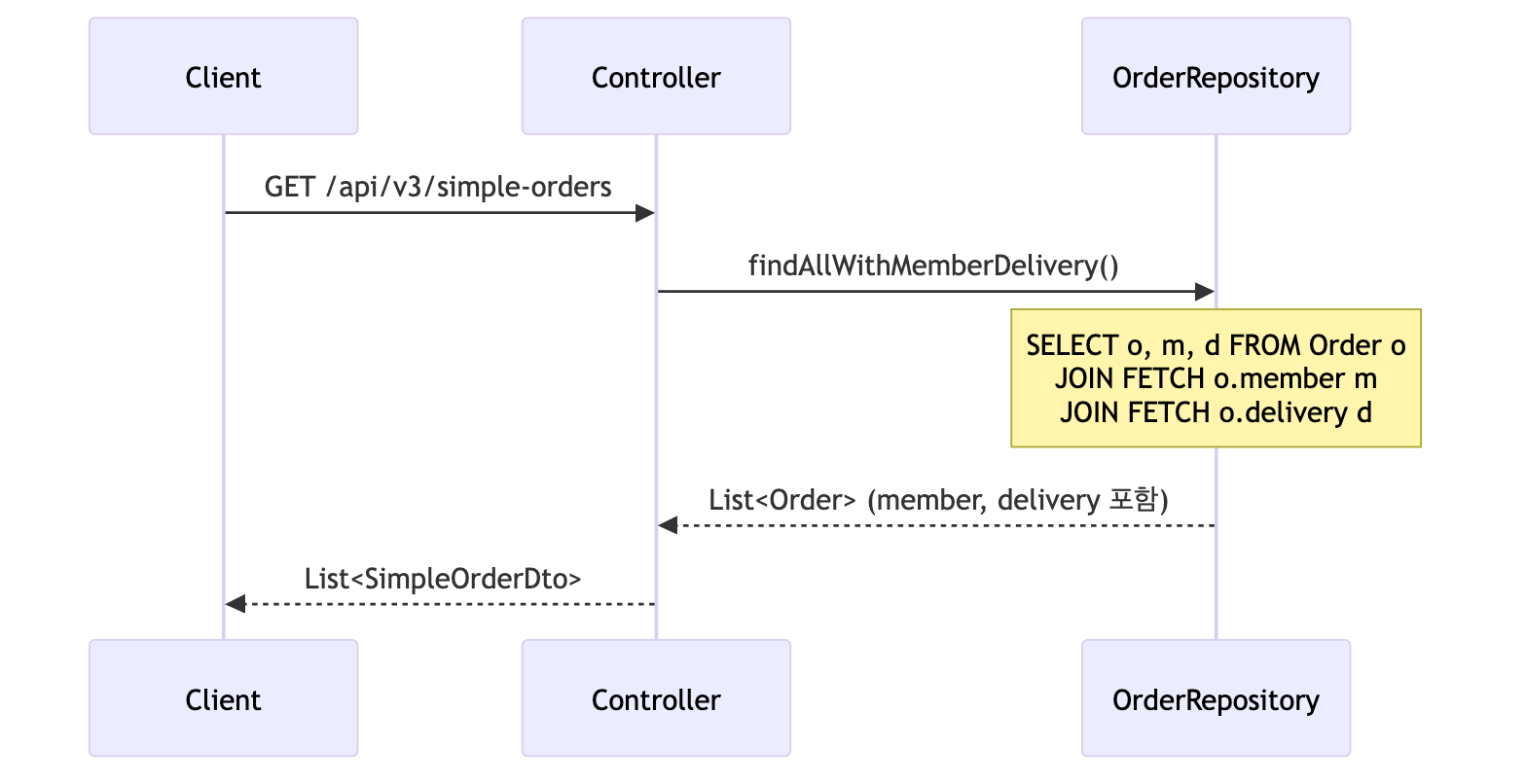
V3 - 페치 조인 최적화
1
2
3
4
5
6
7
@GetMapping("/api/v3/simple-orders")
public List<SimpleOrderDto> ordersV3() {
List<Order> orders = orderRepository.findAllWithMemberDelivery();
return orders.stream()
.map(o -> new SimpleOrderDto(o))
.collect(toList());
}
-
페치 조인 리포지토리
1 2 3 4 5 6 7
public List<Order> findAllWithMemberDelivery() { return em.createQuery( "select o from Order o" + " join fetch o.member m" + " join fetch o.delivery d", Order.class) .getResultList(); }
-
페치 조인의 효과
join fetch를 사용하면Order,Member,Delivery를 단 1번의 쿼리로 함께 조회함- 이미 조회된 상태이므로 이후
getMember(),getDelivery()호출 시 추가 쿼리가 발생하지 않음
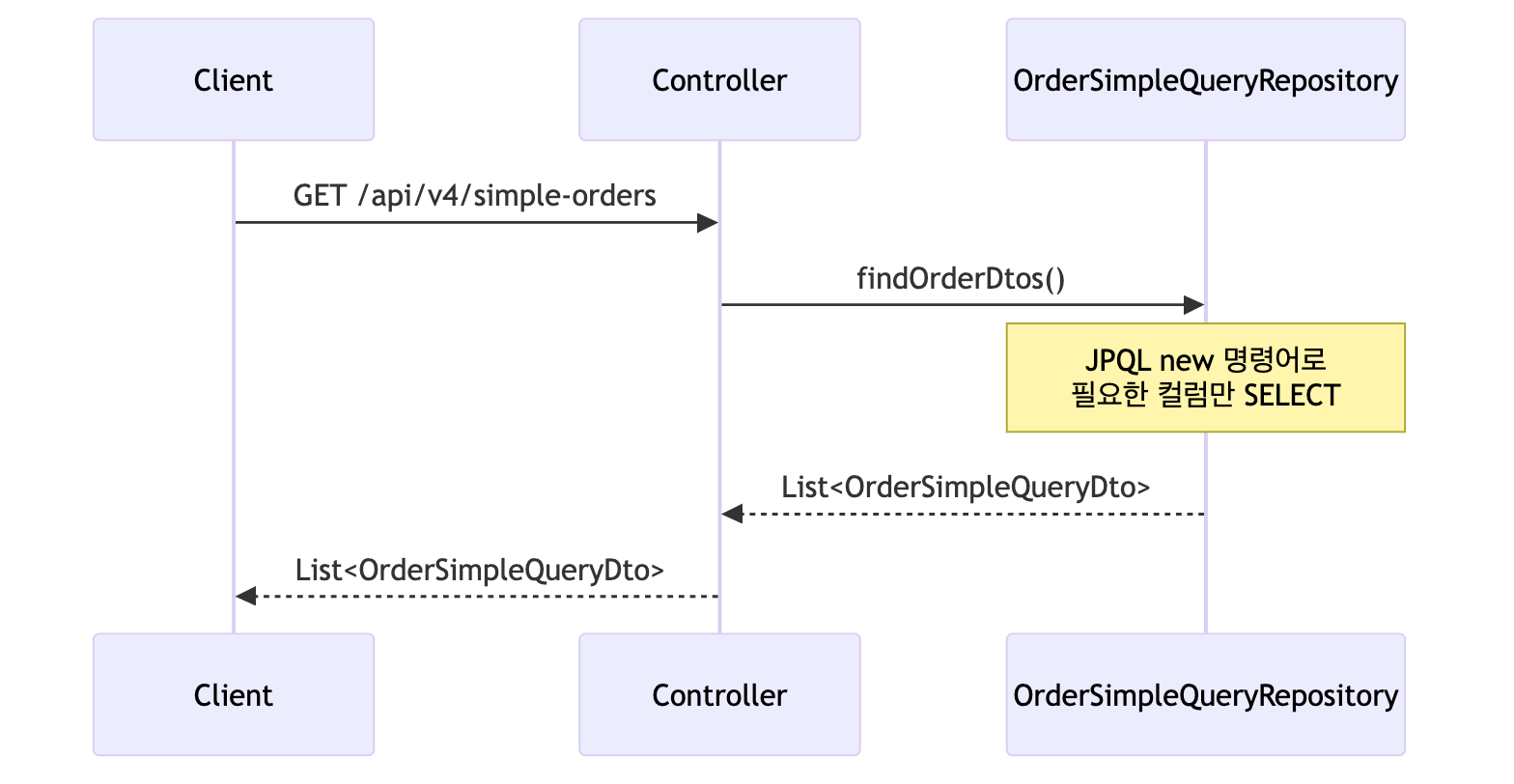
V4 - JPA에서 DTO 직접 조회
1
2
3
4
@GetMapping("/api/v4/simple-orders")
public List<OrderSimpleQueryDto> ordersV4() {
return orderSimpleQueryRepository.findOrderDtos();
}
-
조회 전용 리포지토리
1 2 3 4 5 6 7 8 9
public List<OrderSimpleQueryDto> findOrderDtos() { return em.createQuery( "select new jpabook.jpashop.repository.order.simplequery.OrderSimpleQueryDto" + "(o.id, m.name, o.orderDate, o.status, d.address)" + " from Order o" + " join o.member m" + " join o.delivery d", OrderSimpleQueryDto.class) .getResultList(); }
-
특징
- JPQL의
new명령어를 사용하여 SELECT 절에서 필요한 필드만 골라 DTO로 즉시 변환함 - 불필요한 컬럼을 조회하지 않아 네트워크 전송량이 줄어드는 장점이 있음
- 리포지토리에 API 스펙에 종속된 코드가 들어가는 단점이 있어 재사용성이 낮음
- 별도의 조회 전용 리포지토리(
OrderSimpleQueryRepository)로 분리하는 것이 바람직함
- JPQL의
버전별 비교 요약
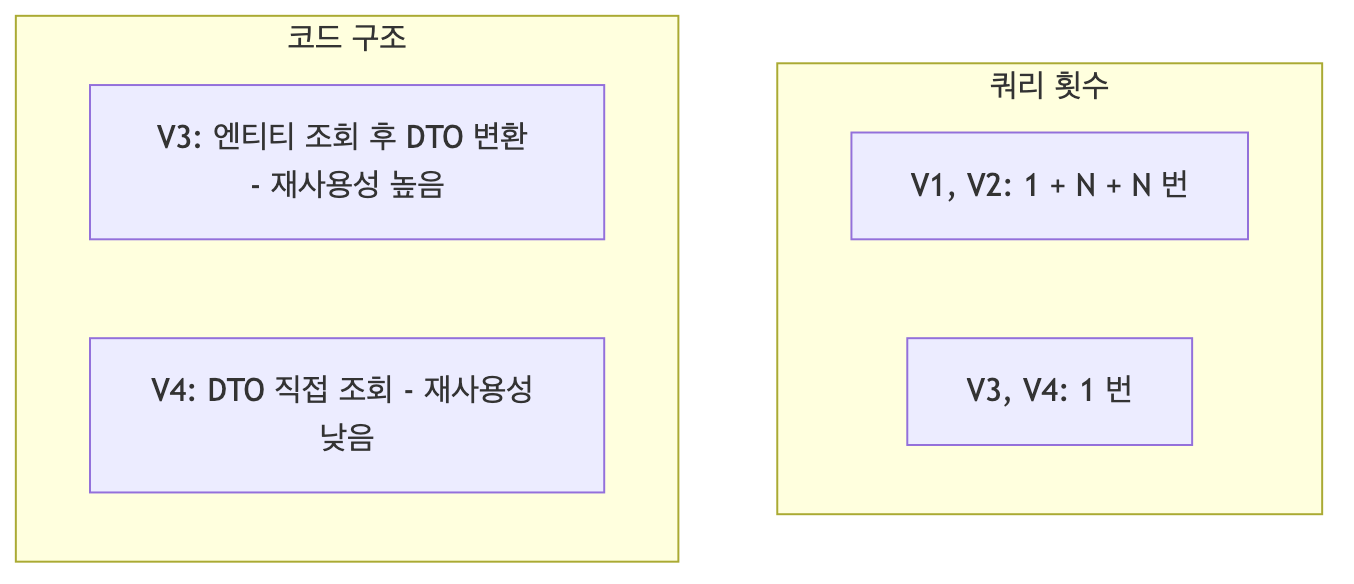
| 버전 | 방식 | 쿼리 수 | 재사용성 | 권장 여부 |
|---|---|---|---|---|
| V1 | 엔티티 직접 노출 | 1 + N + N | - | 비권장 |
| V2 | 엔티티 → DTO 변환 | 1 + N + N | 높음 | 기본 시작점 |
| V3 | 페치 조인 + DTO 변환 | 1 | 높음 | 권장 |
| V4 | JPA → DTO 직접 조회 | 1 | 낮음 | 추가 최적화 시 |
쿼리 방식 선택 권장 순서
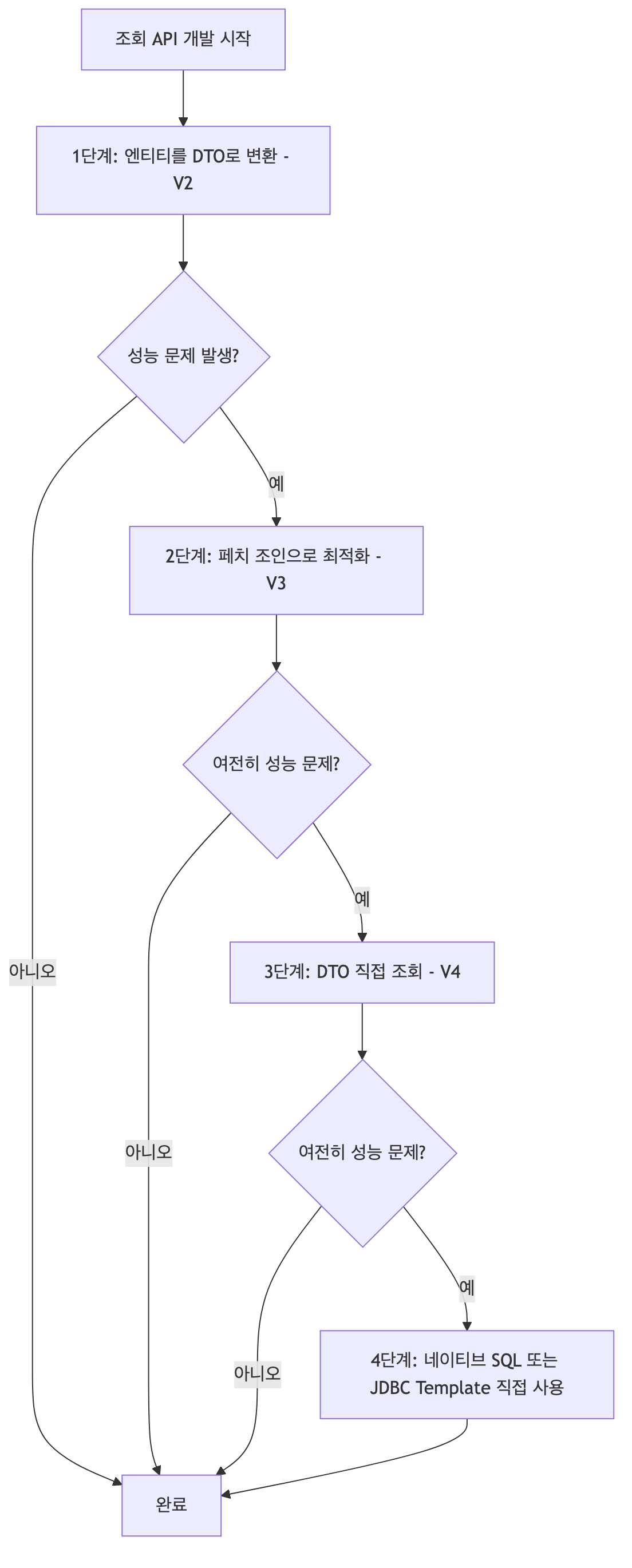
- 대부분의 성능 이슈는 페치 조인(V3)으로 해결됨
- 엔티티로 조회하면 리포지토리 재사용성도 높고 개발이 단순해지므로, DTO 직접 조회(V4)는 V3으로도 해결되지 않는 경우에만 선택함
연습 문제
-
JPA 엔티티를 API 응답으로 직접 노출할 때 발생할 수 있는 주요 문제는 무엇일까요?
a. 무한 루프 발생
- 양방향 연관관계에서
@JsonIgnore처리가 없으면 직렬화 시 서로를 계속 참조하며 무한 루프가 발생할 수 있음 - 엔티티 직접 노출은 API 스펙 변경, 성능 문제 등 다양한 부작용을 초래함
- 양방향 연관관계에서
-
엔티티를 DTO로 변환하는 V2 방식에서, 지연 로딩된 연관 객체 조회 시 발생하는 성능 문제는 무엇일까요?
a. N+1 문제
- 초기 쿼리로 N개의 주문을 가져온 뒤, 각 주문마다 지연 로딩된 멤버나 배송 정보를 조회하기 위한 추가 쿼리가 발생함
- 결과적으로 총 1 + N + N (혹은 그 이상)의 쿼리가 실행되어 성능이 저하될 수 있음
-
JPA 연관관계 매핑 시, 특별한 성능 최적화가 필요하지 않다면 기본 로딩 전략으로 추천되는 것은 무엇인가요?
a. LAZY 로딩
EAGER(즉시) 로딩은 예상치 못한 복잡한 쿼리를 유발하거나 불필요한 데이터를 한꺼번에 로딩하는 문제를 일으킴LAZY(지연) 로딩을 기본으로 설정하고, 성능 최적화가 필요한 시점에 페치 조인(Fetch Join) 등을 활용하는 것이 정석임
-
N+1 문제를 해결하기 위해 JPA에서 자주 사용되는 성능 최적화 기법 중, 연관된 엔티티를 함께 한 번에 조회하는 방식은 무엇일까요?
a. Fetch Join
- 페치 조인은 JPQL에서 SQL JOIN을 사용하여 연관된 엔티티를 즉시 로딩되도록 강제함
- N+1 문제 없이 단 한 번의 쿼리로 필요한 모든 데이터를 객체 그래프 형태로 가져올 수 있음
-
JPA에서 JPQL의
new명령을 이용해 엔티티 대신 DTO로 직접 조회하는 방식(V4)의 특징은 무엇일까요?a. 필요한 데이터만 선택 조회 가능함
- V4 방식은 SELECT 절에서 원하는 컬럼만 선택하여 DTO 생성자로 바로 전달함
- 애플리케이션 계층이 화면 요구사항(DTO)에 의존하게 되는 단점은 있지만, 네트워크 전송 데이터양을 줄여 성능을 극대화할 수 있는 트레이드오프가 있음
요약 정리
- V1(엔티티 직접 노출)은 프록시 직렬화 오류와 순환참조 무한 루프 문제가 발생하며,
Hibernate5Module등록과@JsonIgnore설정이 필요하여 비권장됨 - V2(DTO 변환)는 엔티티를 직접 노출하지 않지만, 지연 로딩으로 인한 N+1 문제가 그대로 존재하여 주문 N건 시 최대 1 + 2N번의 쿼리가 실행됨
- V3(페치 조인)은
join fetch로 연관 엔티티를 한 번에 조회하여 N+1 문제를 해결하며, 리포지토리 재사용성이 높아 권장됨 - V4(DTO 직접 조회)는 필요 컬럼만 SELECT하여 네트워크 전송량을 줄이지만, API 스펙에 종속되어 재사용성이 낮으므로 V3으로도 부족할 때만 사용함
- 쿼리 방식 선택 순서는 V2(기본) → V3(페치 조인) → V4(DTO 직접 조회) → 네이티브 SQL 순으로, 대부분의 성능 이슈는 V3에서 해결됨