쿼리 메소드 기능
- 김영한님의 실전! 스프링 데이터 JPA 강의를 기반으로 스프링 데이터 JPA가 제공하는 쿼리 메소드 기능(메소드 이름으로 쿼리 생성, @Query, 파라미터 바인딩, 페이징 정렬, 벌크 수정, @EntityGraph 등)을 정리함
개요 및 전체 구조
- 스프링 데이터 JPA는 리포지토리 인터페이스만 선언하면 쿼리를 자동으로 생성·실행하는 편리한 기능을 제공함
-
쿼리 메소드 기능은 크게 세 가지 방식으로 나뉨
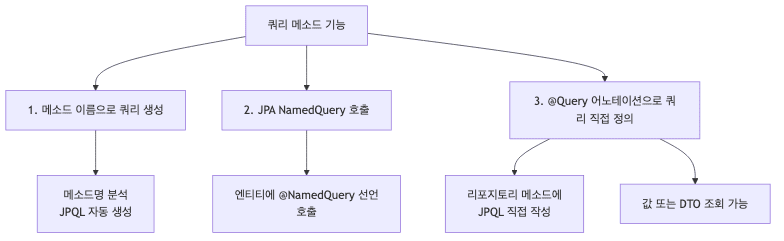
- 주요 장점
- 세 가지 방식 모두 애플리케이션 시작 시점에 JPQL 문법 오류를 발견할 수 있음
- 런타임이 아닌 로딩 시점에 오류를 인지하는 것이 스프링 데이터 JPA의 아주 큰 이점임
메소드 이름으로 쿼리 생성
- 메소드 이름을 분석하여 JPQL을 자동으로 생성하고 실행하며, 간단한 조건 조회에 적합함
-
순수 JPA 방식에서는 쿼리를 직접 작성해야 함
1 2 3 4 5 6
public List<Member> findByUsernameAndAgeGreaterThan(String username, int age) { return em.createQuery("select m from Member m where m.username = :username and m.age > :age", Member.class) .setParameter("username", username) .setParameter("age", age) .getResultList(); }
-
스프링 데이터 JPA 방식에서는 메소드 이름 하나로 동일한 쿼리가 자동 생성됨
1 2 3
public interface MemberRepository extends JpaRepository<Member, Long> { List<Member> findByUsernameAndAgeGreaterThan(String username, int age); }
-
동작 테스트
1 2 3 4 5
@Test public void findByUsernameAndAgeGreaterThan() { List<Member> result = memberRepository.findByUsernameAndAgeGreaterThan("AAA", 15); assertThat(result.size()).isEqualTo(1); }
-
지원하는 쿼리 메소드 키워드
기능 키워드 설명 및 반환 타입 조회 find…By,read…By,query…By,get…By조건에 맞는 엔티티 조회 ( List, 단건,Optional)COUNT count…By반환 타입 longEXISTS exists…By반환 타입 boolean삭제 delete…By,remove…By반환 타입 longDISTINCT findDistinct,findMemberDistinctBy중복 제거 조회 LIMIT findFirst3,findTop,findTop3상위 N건 조회 - 주의 사항
- 엔티티의 필드명이 변경되면 인터페이스에 정의한 메서드 이름도 반드시 함께 변경해야 함
- 변경하지 않으면 애플리케이션 시작 시점에 오류가 발생함
JPA NamedQuery
-
엔티티 클래스에
@NamedQuery로 쿼리를 미리 정의하고, 이름으로 호출하는 방식임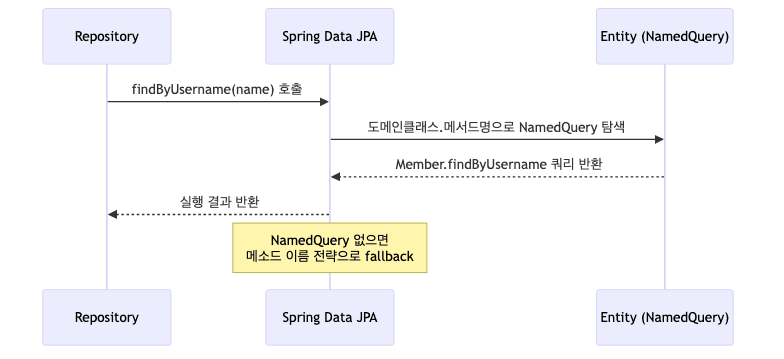
-
엔티티에 NamedQuery 정의
1 2 3 4 5 6
@Entity @NamedQuery( name = "Member.findByUsername", query = "select m from Member m where m.username = :username" ) public class Member { ... }
-
스프링 데이터 JPA로 호출 시
@Query(name = ...)생략 가능하며, ‘도메인 클래스.메서드이름’ 으로 자동 탐색함1 2 3
public interface MemberRepository extends JpaRepository<Member, Long> { List<Member> findByUsername(@Param("username") String username); }
@Query — 리포지토리 메소드에 쿼리 직접 정의
-
실행할 메서드에 JPQL 정적 쿼리를 직접 작성하며, 이름 없는 NamedQuery이므로 애플리케이션 시작 시점에 문법 오류를 발견할 수 있음
-
기본 사용
1 2 3 4
public interface MemberRepository extends JpaRepository<Member, Long> { @Query("select m from Member m where m.username = :username and m.age = :age") List<Member> findUser(@Param("username") String username, @Param("age") int age); }
-
단순 값 및 DTO 조회
1 2 3 4 5 6 7
// 단순 값 타입 조회 @Query("select m.username from Member m") List<String> findUsernameList(); // DTO 직접 조회 (new 명령어와 생성자 일치 필요) @Query("select new study.datajpa.dto.MemberDto(m.id, m.username, t.name) from Member m join m.team t") List<MemberDto> findMemberDto();
파라미터 바인딩과 반환 타입
- 파라미터 바인딩
- 위치 기반 바인딩은 순서 변경 시 오류 위험이 있어 권장하지 않음
- 이름 기반 바인딩(
@Param사용)이나 컬렉션 파라미터를 사용한IN절을 사용하는 방식을 지향함
1 2
@Query("select m from Member m where m.username in :names") List<Member> findByNames(@Param("names") List<String> names);
- 반환 타입
- 컬렉션(
List)- 결과 없음 시 빈 컬렉션 반환
- 단건(
Entity)- 결과 없음 시
null반환 - 2건 이상 시
NonUniqueResultException
- 결과 없음 시
- 단건(
Optional<Entity>)- 결과 없음 시
Optional.empty() - 2건 이상 시
IncorrectResultSizeDataAccessException
- 결과 없음 시
- 컬렉션(
페이징과 정렬
- 페이징 및 정렬 파라미터로는
Pageable과Sort인터페이스를 제공함 PageRequest.of()메서드를 통해 요청 페이지 번호, 사이즈, 정렬 조건을 지정할 수 있음- 리포지토리 메서드의 반환 타입에 따라 실행되는 방식과 제공하는 기능이 달라짐
Page- 페이징 데이터와 함께 전체 데이터 수 등을 제공함 (
getTotalElements,getTotalPages) - 전체 데이터 수를 파악하기 위해 내부적으로 추가
count쿼리가 동반됨
- 페이징 데이터와 함께 전체 데이터 수 등을 제공함 (
Slicecount쿼리 없이 다음 페이지가 존재하는지 여부만 확인함- 내부적으로 요청된
limit보다 데이터를 1건 더 조회하여 다음 페이지 유무를 판단함
List- 부가적인
count쿼리 없이 단순히 데이터 결과 리스트만 반환함
- 부가적인
-
스프링 데이터 JPA 페이징 사용
1 2 3
public interface MemberRepository extends Repository<Member, Long> { Page<Member> findByAge(int age, Pageable pageable); }
-
페이징 테스트
1 2 3 4 5 6 7 8 9 10
@Test public void page() throws Exception { PageRequest pageRequest = PageRequest.of(0, 3, Sort.by(Sort.Direction.DESC, "username")); Page<Member> page = memberRepository.findByAge(10, pageRequest); List<Member> content = page.getContent(); assertThat(content.size()).isEqualTo(3); assertThat(page.getTotalElements()).isEqualTo(5); }
- 실무 최적화 (count 쿼리 분리)
- 복잡한 쿼리에서 count 쿼리는 join 없이 단순하게 실행할 수 있으므로 분리하면 성능이 향상됨
1 2
@Query(value = "select m from Member m", countQuery = "select count(m.username) from Member m") Page<Member> findMemberAllCountBy(Pageable pageable);
- 엔티티를 DTO로 변환
page.map(m -> new MemberDto(m.getId(), ...))를 통해 API 반환용으로 안전하게 변환 가능
벌크성 수정 쿼리
-
대량의 데이터를 한 번에 수정하는 쿼리로, 영속성 컨텍스트를 무시하고 DB에 직접 반영되므로 주의가 필요함
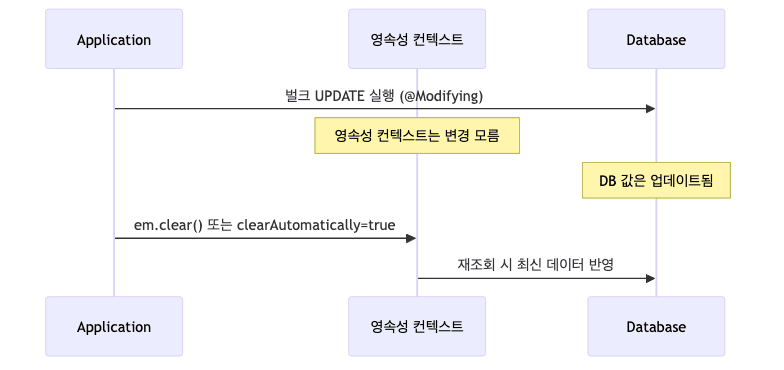
-
스프링 데이터 JPA 벌크 연산
1 2 3
@Modifying(clearAutomatically = true) @Query("update Member m set m.age = m.age + 1 where m.age >= :age") int bulkAgePlus(@Param("age") int age);
-
권장 방안
- 영속성 컨텍스트에 엔티티가 없는 상태에서 벌크 연산을 먼저 실행함
- 부득이하게 엔티티가 있으면 벌크 연산 직후 영속성 컨텍스트를 초기화(
clearAutomatically = true)함
@EntityGraph
-
연관된 엔티티를 SQL 한 번에 조회하는 방법으로, JPQL 없이 페치 조인 효과를 낼 수 있음
-
지연 로딩 시 발생할 수 있는 N+1 문제를
@EntityGraph로 간단하게 해결할 수 있음 (내부적으로 LEFT OUTER JOIN 사용)1 2 3 4 5 6 7 8
// 공통 메서드 오버라이드 @Override @EntityGraph(attributePaths = {"team"}) List<Member> findAll(); // 메서드 이름 쿼리에서 가장 편리 @EntityGraph(attributePaths = {"team"}) List<Member> findByUsername(String username);
JPA Hint & Lock
@QueryHints를 이용한 읽기 전용 최적화- JPA 구현체(Hibernate)에게 힌트를 제공하여
readOnly설정 시 스냅샷을 만들지 않아 메모리와 성능을 최적화함
1 2
@QueryHints(value = @QueryHint(name = "org.hibernate.readOnly", value = "true")) Member findReadOnlyByUsername(String username);
- JPA 구현체(Hibernate)에게 힌트를 제공하여
- Lock 모드
- 낙관적 락 (
OPTIMISTIC)- 버전을 관리하는
@Version어노테이션을 사용함 - 데이터 충돌이 발생할 경우 예외를 발생시킴
- 버전을 관리하는
- 비관적 락 (
PESSIMISTIC_WRITE)- 쿼리 실행 시
SELECT FOR UPDATE구문을 사용하여 데이터베이스 단에서 락을 걺 - 다른 트랜잭션의 접근을 차단하고 대기하게 만듦
- 쿼리 실행 시
1 2
@Lock(LockModeType.PESSIMISTIC_WRITE) List<Member> findByUsername(String name);
- 낙관적 락 (
연습 문제
-
Spring Data JPA에서 리포지토리 메서드의 이름만으로 쿼리를 생성할 때, 조건을 정의하는 부분의 시작을 나타내는 키워드는 무엇일까요?
a. By
- 메서드 이름으로 쿼리를 만들 때
find...By나count...By처럼By키워드 뒤에 검색 조건을 붙임
- 메서드 이름으로 쿼리를 만들 때
-
메서드 이름으로 쿼리를 생성하는 방식이 복잡한 검색 조건에 적합하지 않은 주요 이유는 무엇일까요?
a. 메서드 이름이 너무 길어져 가독성이 떨어지기 때문
- 여러 조건을 조합할수록 메서드 이름이 매우 길어지므로, 복잡한 쿼리는
@Query사용을 권장함
- 여러 조건을 조합할수록 메서드 이름이 매우 길어지므로, 복잡한 쿼리는
-
Spring Data JPA에서 리포지토리 메서드에 JPQL 쿼리 문을 직접 정의하고 싶을 때 사용하는 어노테이션은 무엇일까요?
a. @Query
@Query어노테이션을 리포지토리 인터페이스의 메서드에 붙여 JPQL이나 네이티브 SQL 쿼리를 직접 작성할 수 있으며, 애플리케이션 로딩 시점에 파싱됨
-
@Query를 사용하여 JPQL로 엔티티 객체 대신 특정 필드 값이나 DTO를 직접 조회할 때, JPQL 구문 내에서 DTO를 생성하기 위해 사용해야 하는 키워드는 무엇일까요?
a. SELECT NEW
- JPQL에서 DTO를 직접 조회하려면
SELECT NEW 패키지명.DTO클래스명형식을 사용해야 함
- JPQL에서 DTO를 직접 조회하려면
-
Spring Data JPA에서 JPQL에 파라미터를 바인딩할 때, 유지보수와 가독성 향상을 위해 권장되는 방식은 무엇일까요?
a. 이름 기반 바인딩 (:파라미터명)
- 위치 기반 바인딩은 파라미터 순서가 변경되면 오류가 발생할 위험이 있으므로 이름 기반 바인딩(
@Param사용)이 권장됨
- 위치 기반 바인딩은 파라미터 순서가 변경되면 오류가 발생할 위험이 있으므로 이름 기반 바인딩(
-
Spring Data JPA 리포지토리 메서드가 단일 결과를 반환할 것으로 예상되지만, 결과가 없을 수도 있는 경우 Null 대신 사용하는 것이 좋은 Java 8 반환 타입은 무엇일까요?
a. Optional
- 단일 결과를 조회할 때 데이터가 없으면 기본적으로 Null을 반환하므로,
Optional로 감싸서 반환하는 것이 좋음
- 단일 결과를 조회할 때 데이터가 없으면 기본적으로 Null을 반환하므로,
-
Spring Data JPA의 페이징 기능을 사용하면서, 현재 페이지의 내용물뿐만 아니라 전체 데이터 개수(‘TotalCount’) 정보까지 함께 받고 싶을 때 리포지토리 메서드의 반환 타입으로 가장 적합한 것은 무엇일까요?
a. Page
Page는 페이징된 콘텐츠와 함께 전체 요소 수 등 관련 정보를 모두 포함하며,Slice는 다음 페이지 존재 여부만 확인 가능함
-
Spring Data JPA에서 @Query 어노테이션을 사용하여 UPDATE나 DELETE 같은 벌크성 변경 쿼리를 실행할 때, 해당 메서드에 반드시 함께 붙여야 하는 어노테이션은 무엇일까요?
a. @Modifying
- 쿼리가 조회(SELECT)가 아닌 변경 작업을 수행함을 나타내며,
executeUpdate가 호출되게 함
- 쿼리가 조회(SELECT)가 아닌 변경 작업을 수행함을 나타내며,
-
JPA에서 연관 관계가 Lazy 로딩으로 설정된 엔티티를 조회한 후, 연관된 엔티티에 접근할 때마다 추가 쿼리가 발생하는 ‘N+1 문제’를 효율적으로 해결하기 위해 Spring Data JPA에서 지원하는 어노테이션은 무엇일까요?
a. @EntityGraph
- Fetch Join을 추상화하여 조회 시점에 함께 가져올 연관 엔티티를 지정할 수 있어 N+1 문제를 간단하게 해결함
-
JPA 표준은 아니지만 JPA 구현체에 쿼리 실행 방식을 최적화하도록 지시하는 메커니즘으로, 주로 읽기 전용 쿼리 성능 개선 등에 사용될 수 있는 기능은 무엇일까요?
a. JPA Hint
org.hibernate.readOnly같은 힌트를 사용해 읽기 전용 쿼리 시 내부 최적화(변경 감지 생략 등)를 유도할 수 있음
요약 정리
- 메소드 이름 분석만으로 간단한 조건 쿼리를 생성할 수 있으나, 복잡한 쿼리에는 리포지토리 인터페이스 메서드에
@Query를 선언하여 JPQL을 직접 작성하는 방식이 권장됨 - 파라미터 바인딩 시 유지보수 문제를 피하기 위해 순서 기반이 아닌
@Param을 이용한 이름 기반 바인딩을 사용해야 함 - 페이징 처리 시 반환 타입으로
Page를 선언하면 카운트 쿼리까지 자동으로 실행되고 최적화 분리도 가능하며 벌크 연산(@Modifying), N+1 문제 해결(@EntityGraph) 등을 통해 다양한 데이터 조회 병목 지점들을 손쉽게 제어할 수 있음