개요
- 시스템 아키텍처(System Architecture)란 여러 대의 서버, 서비스, 데이터베이스 등 다양한 인프라 요소들이 어떻게 연결되고 상호작용하는지를 정의하는 전체적인 구조적 밑그림임
- 애플리케이션의 규모, 비즈니스 요구사항, 조직의 구조에 따라 유연하게 선택되어야 함
모놀리식 아키텍처 (Monolithic Architecture)
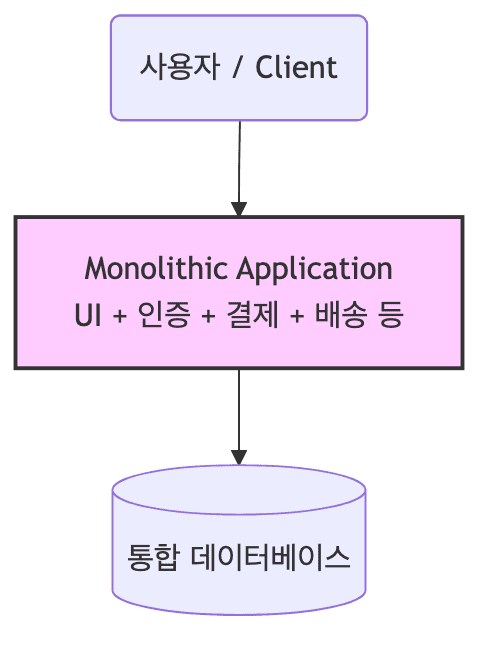
- 애플리케이션의 모든 비즈니스 로직(UI, 인증, 결제, 배송 등)과 데이터 접근 계층이 하나의 거대한 코드베이스로 통합 배포되는 아키텍처임
장점
- 초기 개발 속도
- 구성 요소 간 호출이 로컬 함수 호출이므로 네트워크 지연이 없고 디버깅 및 테스트가 단순함
- 배포 및 관리 용이
- 하나의 결과물(ex. war, jar 파일)만 빌드하여 서버에 올리면 됨
- 간단한 트랜잭션
- 동일한 데이터베이스를 공유하므로 ACID 트랜잭션이나 데이터 무결성 유지가 쉬움
단점
- 유연성 부족
- 코드가 거대해질수록 빌드 및 배포 시간이 기하급수적으로 늘어남
- 부분 장애의 전파
- 특정 모듈(ex. 결제)의 메모리 누수나 장애가 전체 시스템의 다운으로 이어질 수 있음
- 기술 스택 종속
- 애플리케이션 전체가 동일한 언어 및 프레임워크에 종속되어 새로운 기술 도입이 어려움
마이크로서비스 아키텍처 (MSA, Microservices Architecture)
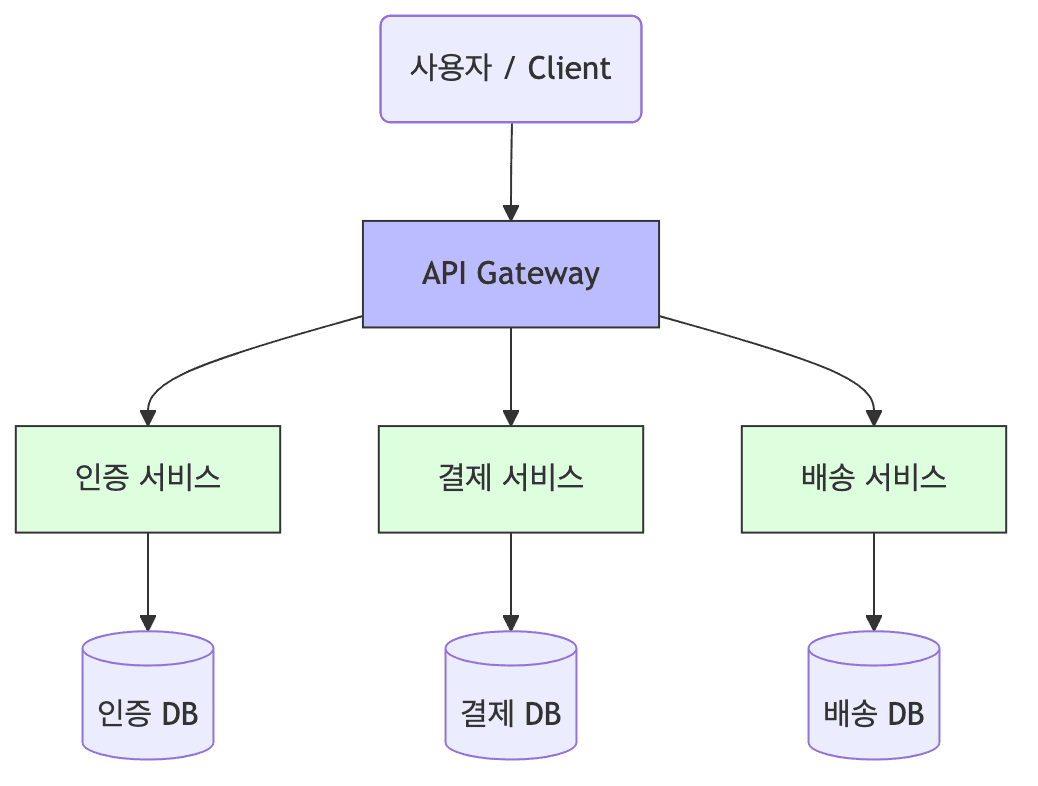
- 크고 복잡한 애플리케이션을 작고 독립적으로 배포 가능한 여러 개의 서비스(Microservice) 단위로 잘게 나누어 설계하는 방식임
- 각 서비스는 주로 REST API, gRPC, 메시지 큐 등을 통해 서로 통신함
장점
- 독립적 배포 및 확장
- 트래픽이 몰리는 특정 서비스만 스케일 아웃(Scale-out)할 수 있어 리소스 효율성이 좋음
- 장애 격리
- 하나의 서비스에 장애가 발생하더라도 서킷 브레이커 패턴 등을 통해 타 서비스로의 장애 전파를 막을 수 있음
- 다형성
- 각 서비스의 특성에 맞는 최적의 언어와 데이터베이스(RDB, NoSQL 등)를 자유롭게 선택할 수 있음
단점
- 복잡도 증가
- 네트워크 통신, 서비스 디스커버리, API 게이트웨이 등 분산 시스템 관리를 위한 인프라 복잡도가 대폭 상승함
- 데이터 일관성 관리
- 각 서비스가 고유한 DB를 가지므로, 분산 트랜잭션 및 데이터 동기화 처리가 매우 어려움
- 테스트 및 디버깅
- 여러 서비스를 거쳐 일어나는 장애를 추적하고 통합 테스트하기가 까다로움
서버리스 아키텍처 (Serverless Architecture)
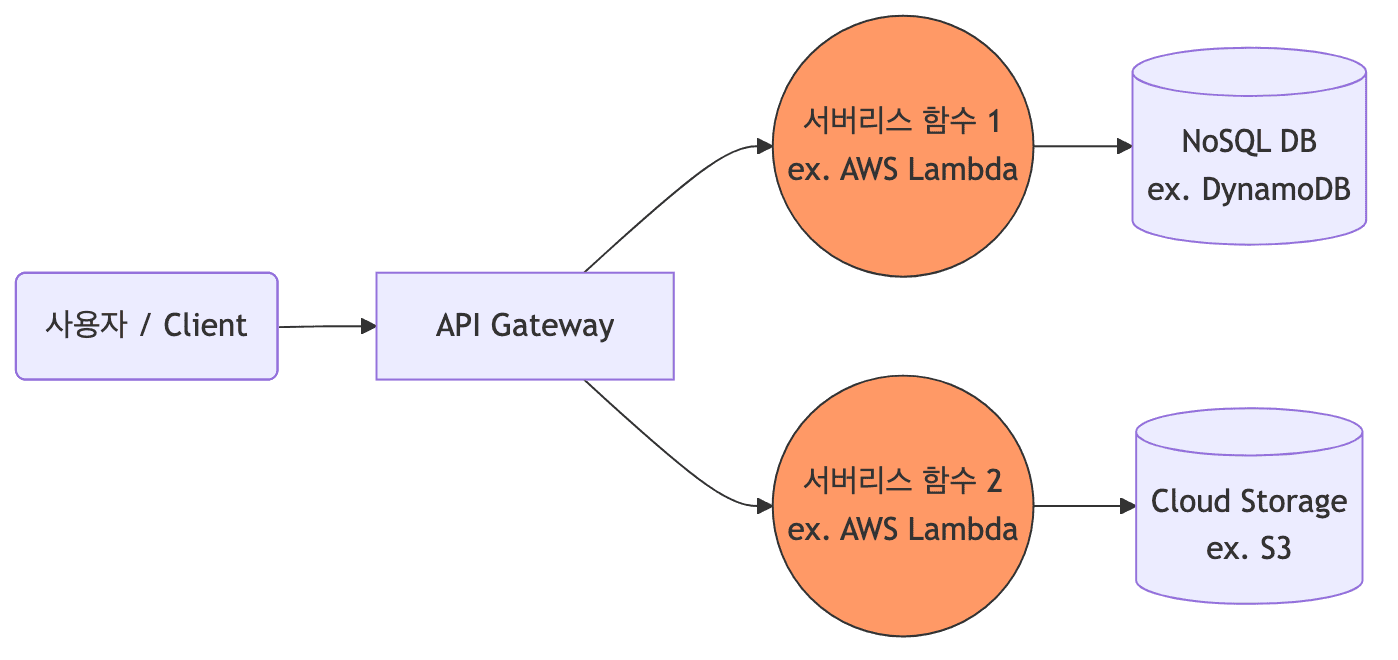
- 개발자가 서버의 프로비저닝, 스케일링, 운영 체제 유지보수 등을 전혀 신경 쓰지 않고 클라우드 제공자(AWS Lambda 등)에게 온전히 위임하는 방식임
- 코드가 오로지 특정 이벤트(HTTP 요청, DB 변경 등)가 발생했을 때만 실행되는 FaaS(Function as a Service) 형태가 대표적임
장점
- 운영 부담 최소화
- 인프라 관리에 리소스를 낭비하지 않고 비즈니스 로직 개발에만 집중할 수 있음
- 비용 효율성
- 서버가 켜져 있는 시간이 아니라, 실제로 함수가 실행된 횟수나 시간(ms 단위)만큼만 비용을 지불함
- 오토 스케일링
- 트래픽이 폭증해도 클라우드 벤더 측에서 자동으로 무한에 가깝게 리소스를 확장해 줌
단점
- 콜드 스타트(Cold Start)
- 함수가 오랫동안 멈춰있다가 처음 호출될 때 컨테이너를 구동하느라 지연 시간이 발생함 (실시간성이 중요한 작업에 치명적)
- 벤더 락인(Vendor Lock-in)
- AWS, GCP 등 특정 클라우드 프로바이더의 생태계와 아키텍처에 강하게 종속됨
- 상태 유지 불가 (Stateless)
- 함수 실행이 끝나면 메모리가 초기화되므로 메모리에 데이터를 보존할 수 없어 무조건 외부 저장소가 필요함
이벤트 기반 아키텍처 (Event-Driven Architecture)
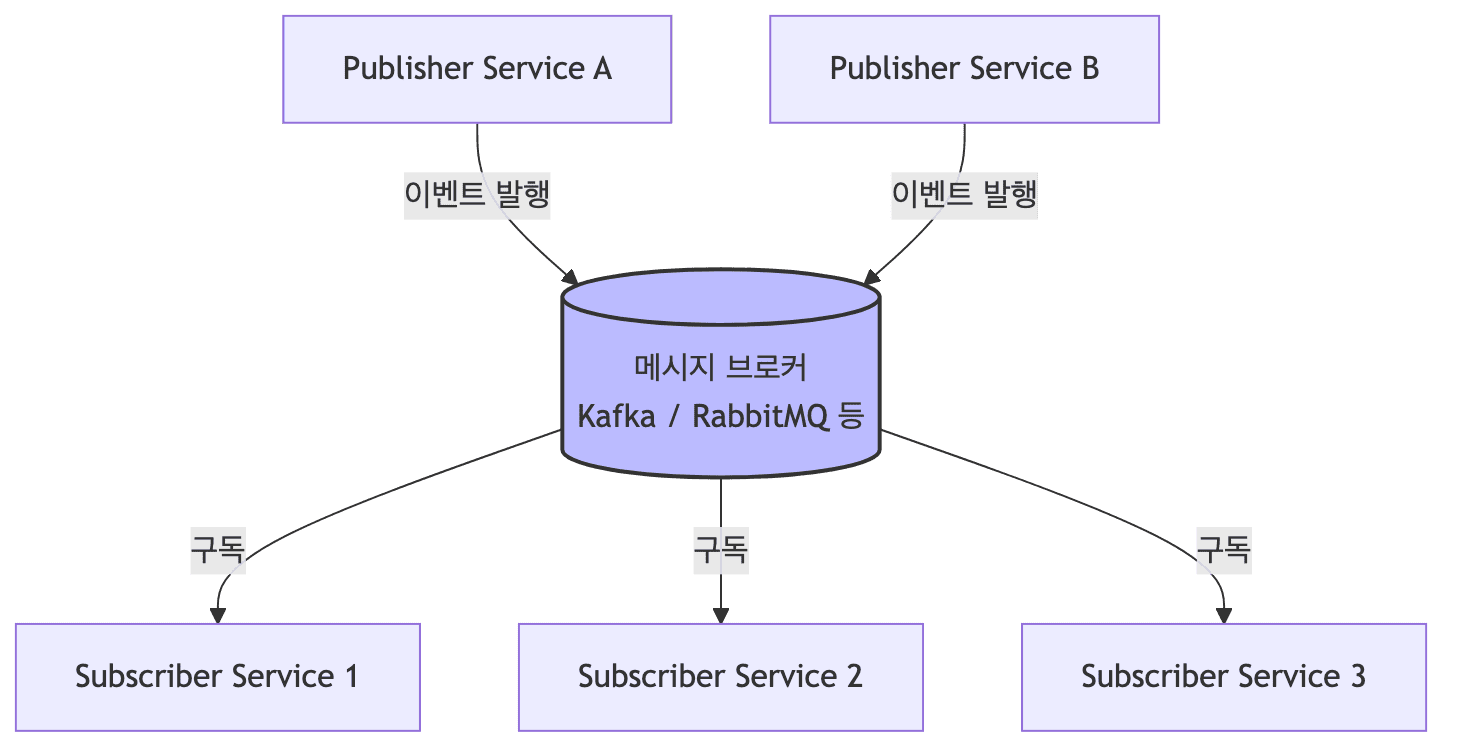
- 시스템의 구성 요소들이 상태 변경(Event)의 발생 및 감지(Publish/Subscribe)를 통해 통신하고 비동기적으로 동작하는 아키텍처임
- Kafka, RabbitMQ 같은 메시지 브로커가 역할을 담당함
장점
- 비동기 결합 해제
- 발행자(Publisher)는 구독자(Subscriber)가 누구인지, 살았는지 죽었는지 알 필요 없이 브로커에 던지기만 하면 되므로 서비스 간 결합도가 대폭 낮아짐
- 탄력성 및 버퍼링
- 트래픽이 폭주하더라도 메시지 큐가 버퍼 역할을 하여 안정적인 처리(순차적 Consume)가 가능해 서버 다운을 방지함
- 확장성
- 이벤트 스트림을 기준으로 쉽게 새로운 기능을 끼워(Subscribe) 넣을 수 있음
단점
- 결과적 일관성
- 데이터가 즉시 일치하는 것이 아니라 “언젠가는 동기화된다”는 전제를 가지므로 실시간 동기 처리가 중요한 비즈니스(송금 등)에는 부적합할 수 있음
- 로직 파편화 및 디버깅
- 시스템 전체의 비즈니스 흐름(어떤 이벤트가 연쇄적으로 트리거되는지)을 파악하기가 직관적이지 않음
- 메시지 브로커 의존
- 메시지 큐 자체가 단일 장애점(SPOF)이 될 수 있어, 브로커에 대한 고가용성(HA) 구성 지식이 필수적임