Apache Kafka 시리즈
- Apache Kafka 기본 개념 - 메시징 시스템의 이해 ← 현재 글
- Apache Kafka 파티션과 컨슈머 그룹
- Apache Kafka 복제와 고가용성 - 데이터 안정성 보장
- Apache Kafka 성능 튜닝과 운영 - 최적화
- Spring Boot와 KRaft를 활용한 Apache Kafka 개발
- Apache Kafka 모니터링과 운영 - Prometheus & Grafana
개요
- Apache Kafka는 실시간으로 대량의 데이터를 안전하게 전달하고 처리하기 위한 플랫폼임
Kafka가 필요한 이유
- 현대 서비스들(넷플릭스, 쇼핑몰, SNS 등)은 수많은 데이터를 실시간으로 처리해야 함
- 사용자의 클릭, 검색, 결제 데이터
- 서비스 로그, 에러 메시지
- IoT 센서 데이터
- 실시간 알림
- 이러한 데이터를 안전하고 빠르게 처리하기 위해 Kafka를 사용함
기술 선정 기준 (Kafka vs RabbitMQ vs Redis)
- 상황별 기술 선택 가이드
-
단순히 “Kafka가 가장 좋다”는 것이 아니라, 각 기술의 특징에 맞춰 적절한 도구를 선택해야 함
-
Apache Kafka를 선택해야 하는 경우
- 이벤트 재생(Replay)이 필요한 경우
- 데이터를 디스크에 영구 저장하므로, 과거 데이터를 다시 읽거나 장애 복구 시 이전을 재처리해야 할 때 필수적임
- 초당 수십만 건 이상의 대용량 처리
- 배치 전송과 순차 I/O를 통해 높은 처리량(Throughput)을 제공함
- MSA 간 느슨한 결합
- 서비스 간 이벤트를 통한 비동기 통신 시스템 구축에 최적화되어 있음
- 예시
- 사용자 활동 로그 수집, 결제 데이터 스트리밍, CDC(DB 변경 감지)
- 이벤트 재생(Replay)이 필요한 경우
-
RabbitMQ를 선택해야 하는 경우
- 복잡한 라우팅이 필요한 경우
- Topic, Direct, Header 등 다양한 교환기(Exchange)를 통해 정교한 메시지 라우팅이 가능함
- 우선순위 큐(Priority Queue)가 필요한 경우
- 중요도에 따라 메시지 처리 순서를 조정해야 할 때 적합함
- 데이터가 즉시 처리되고 사라져야 하는 작업 큐
- 메시지를 쌓아두기보다 빠르게 소비하고 제거하는 작업 할당 패턴에 유리함
- 예시
- PDF 생성 작업 큐, 이메일 발송 요청, 선착순 이벤트 처리
- 복잡한 라우팅이 필요한 경우
-
Redis Pub/Sub을 선택해야 하는 경우
- 메시지 영속성이 필요 없는 경우
- 소비자가 없으면 메시지가 즉시 휘발되어도 상관없는 가벼운 통신에 적합함
- 극강의 속도가 필요한 실시간 통신
- 인메모리 기반으로 가장 빠른 응답 속도를 제공함
- 구축 편의성
- 별도의 인프라 구성 없이 Redis만으로 즉시 사용 가능함
- 예시
- 실시간 채팅방 메시지, 일회성 알림 발송, 대시보드 실시간 갱신
- 메시지 영속성이 필요 없는 경우
- 요약 비교표
| 특징 | Kafka | RabbitMQ | Redis Pub/Sub |
|---|---|---|---|
| 메시지 보관 | 디스크 영구 저장 (설정 기간) | 메모리 (소비 후 삭제) | 메모리 (즉시 휘발) |
| 처리 방식 | Pull (컨슈머가 가져감) | Push (브로커가 밀어줌) | Push |
| 주요 용도 | 대용량 로그, 이벤트 스트리밍 | 복잡한 라우팅, 작업 큐 | 간단한 알림, 채팅 |
| 장점 | 높은 처리량, 재생(Replay) 가능 | 다양한 라우팅 패턴, 우선순위 큐 | 매우 빠름, 설치 간편 |
기본 개념
메시지 전달 구성 요소
-
카프카를 우체국에 비유하면 다음과 같음
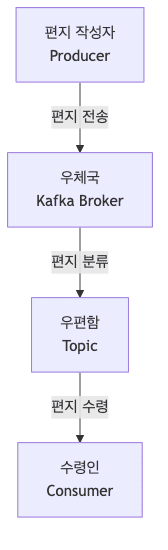
- Producer (생산자)
- 편지를 쓰는 사람
- Kafka Broker (우체국)
- 메시지를 저장하고 전달하는 서버
- Topic (토픽)
- 메시지를 종류별로 구분하여 저장하는 공간
- 일반 우편함과 달리, 메시지를 가져가도 삭제되지 않고 설정된 보관 기간(retention period) 동안 유지됨
- 보관 기간 기본값: 7일 (168시간)
- 설정 가능 범위: 몇 시간 ~ 무제한
- 여러 컨슈머가 같은 메시지를 독립적으로 읽을 수 있음
- 보관 기간이 지나면 가장 오래된 메시지부터 자동 삭제됨
- Consumer (소비자)
- 메시지를 받아서 처리하는 프로그램
- 각 컨슈머는 자신의 오프셋을 관리하여 어디까지 읽었는지 추적함
- Producer (생산자)
메시지 추적과 관리
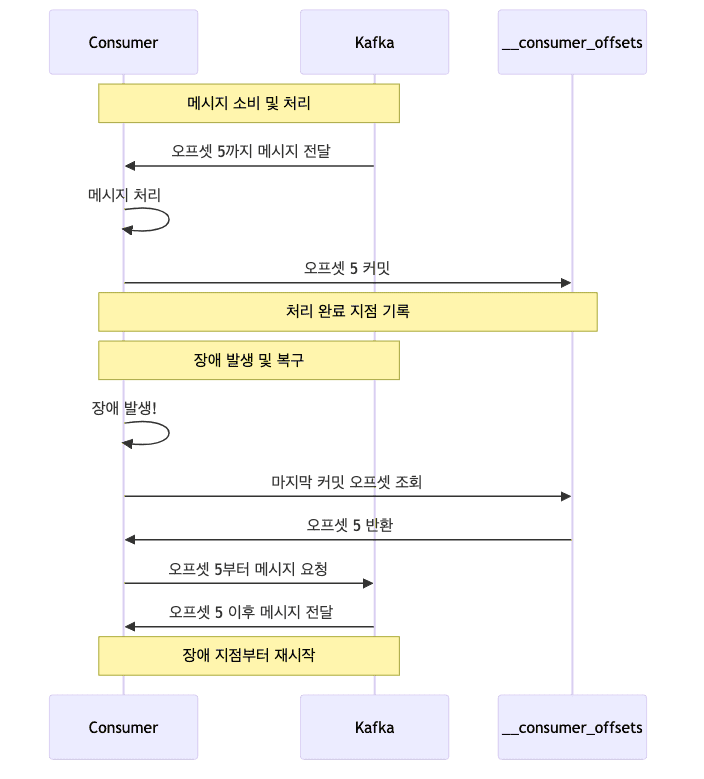
- 커밋 (Commit)
- 컨슈머가 어디까지 메시지를 처리했는지 표시하는 것
- 마치 책갈피처럼 다음에 어디서부터 읽어야 할지 기억
- 메시지 처리 진행 상황을 추적하고 관리
- 오프셋 (Offset)
- 각 파티션 내의 메시지 위치를 가리키는 번호
- 첫 메시지는 0번부터 시작해서 순차적으로 증가
- 메시지의 고유한 ‘주소’나 ‘페이지 번호’ 같은 역할

-
커밋과 오프셋의 관계
- 컨슈머는 처리한 메시지의 오프셋을 커밋
- 커밋된 오프셋을 통해 처리 진행상황 파악
- 장애 발생 시 마지막 커밋 오프셋부터 재시작
전체 아키텍처
-
Kafka의 전체 구조를 이해하면 데이터가 어떻게 흐르는지 파악할 수 있음
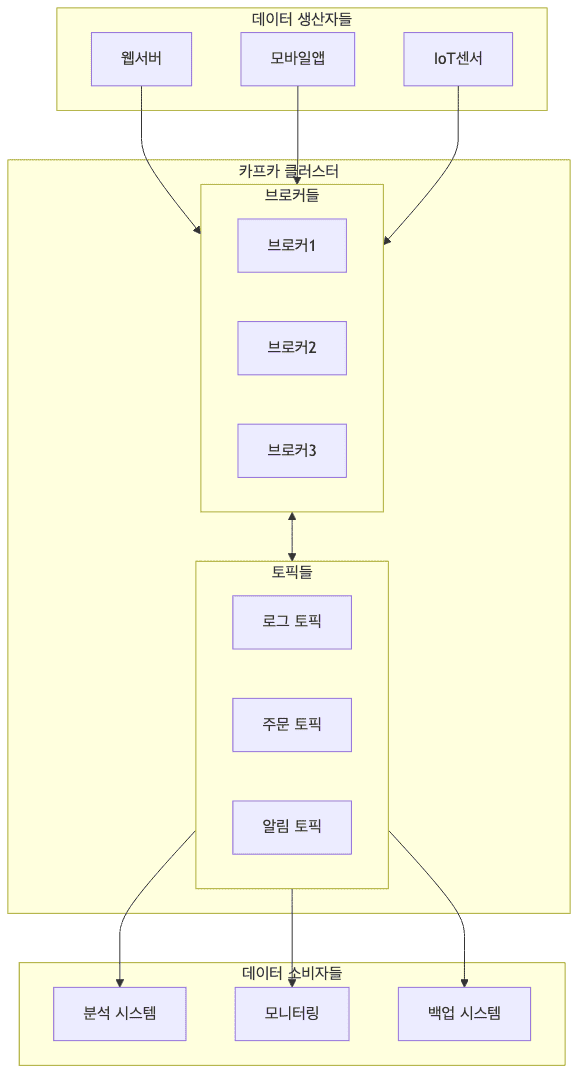
주요 특징
- 안정성
- 데이터를 안전하게 보관 (마치 은행 금고처럼)
- 여러 서버에 복사본 저장으로 데이터 유실 방지
- 서버 장애가 발생해도 서비스 계속 운영
- 확장성
- 처리할 데이터가 늘어나면 서버 추가로 확장
- 카카오톡 단체방처럼 많은 사용자 동시 처리 가능
- 필요할 때마다 쉽게 용량 증설
- 고성능
- 대량의 데이터를 빠르게 처리
- 효율적인 데이터 저장 방식 사용
- 여러 소비자가 동시에 데이터 읽기 가능
핵심 구성 요소
메시지 생산자 (Producer)
-
데이터를 만들어서 Kafka로 보내는 프로그램
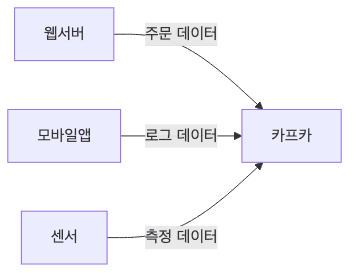
-
예시
- 쇼핑몰의 주문 처리 시스템
- 핸드폰 앱의 사용자 활동 로그
- 기상 관측소의 온도 센서
메시지 소비자 (Consumer)
- Kafka에서 데이터를 가져와서 처리하는 프로그램
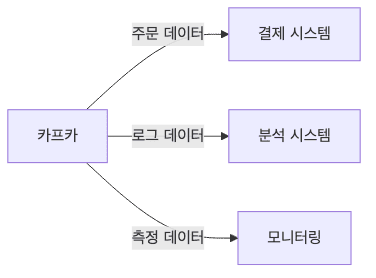
- 예시
- 주문 데이터를 받아서 배송 처리하는 시스템
- 사용자 행동 데이터를 분석하는 시스템
- 실시간 알림을 보내는 서비스
메시지 저장소 (Broker)
- Kafka 서버를 브로커라고 부름
-
데이터를 저장하고 관리하는 창고와 같음
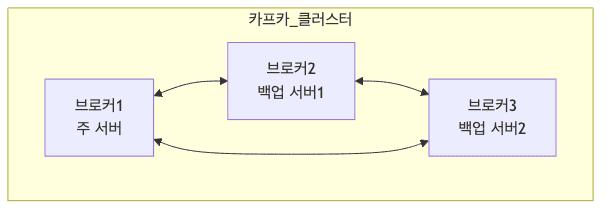
- 특징
- 여러 서버가 협력하여 작동 (마치 여러 지점을 가진 은행처럼)
- 한 서버가 고장나도 다른 서버가 대신 처리
- 데이터를 안전하게 보관하고 전달
메시지 분류 (Topic)
- 토픽은 같은 종류의 메시지를 모아두는 공간임
-
도서관의 서가나 우체국의 우편함과 비슷함
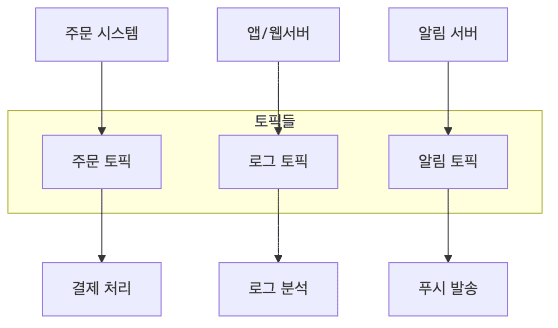
- 예시
- 주문 토픽
- 모든 주문 관련 데이터 저장
- 로그 토픽
- 시스템 로그 메시지 저장
- 알림 토픽
- 사용자 알림 메시지 저장
- 주문 토픽