Apache Kafka 시리즈
- Apache Kafka 기본 개념 - 메시징 시스템의 이해
- Apache Kafka 파티션과 컨슈머 그룹
- Apache Kafka 복제와 고가용성 - 데이터 안정성 보장
- Apache Kafka 성능 튜닝과 운영 - 최적화
- Spring Boot와 KRaft를 활용한 Apache Kafka 개발 ← 현재 글
- Apache Kafka 모니터링과 운영 - Prometheus & Grafana
시스템 개요
- KRaft 모드로 단일 서버 환경에서 Docker Compose를 사용하여 고가용성 Kafka 클러스터를 구축하는 전체 과정을 다룸
- 브로커가 직접 메타데이터 관리
- Production-Grade 에러 핸들링 및 멱등성 보장
시나리오
-
시스템 목적
- 스마트 팩토리 환경 모니터링 시스템
- 제조 공정의 온습도를 실시간으로 수집/분석하여 품질 관리
- 이상 상태 즉시 감지 및 알림으로 불량률 최소화
-
시스템 구성 요소
- 데이터 수집층
- 공정별 온습도 센서 네트워크
- 센서당 초당 1회 데이터 수집
- 총 1000개 센서 (10개 공정 * 100개 측정 포인트)
- 데이터 처리층
- Kafka 기반 실시간 스트리밍 처리
- 3대 브로커 고가용성 구성
- 다중 컨슈머 그룹으로 용도별 처리
- 데이터 활용층
- 실시간 모니터링 대시보드
- 이상 징후 자동 감지 및 알림
- 품질 분석을 위한 데이터 적재
- 데이터 수집층
시스템 요구사항 및 설계 원칙
-
성능 요구사항
- 처리 성능
- 초당 1000개 이상 메시지 처리
- 10ms 이내 단일 구간 처리 지연 목표 (end-to-end가 아닌 Kafka 브로커 내 처리 시간)
- 네트워크 레이턴시, 직렬화/역직렬화 시간은 별도
- 로컬 테스트 결과가 실제 트래픽이 몰리는 운영 환경의 성능을 대변하지 않음
- 정확한 성능 측정은 실제 운영 환경과 유사한 조건에서 부하 테스트 필요
- 전송 및 복제 단계에서의 데이터 유실 방지
- min.insync.replicas=2 + acks=all 설정
- 전송 과정에서의 유실 차단
- 물리적 재해(동시 디스크 손상)는 별도 백업 필요
- 브로커 3대 구성 권장 (고가용성 달성 조건)
- 가용성
- 99.9% 이상 서비스 가용성
- 브로커 3대 구성으로 단일 장애 대응
- 자동 복구 및 재조정
- 모니터링
- 실시간 메트릭 수집 (15초 주기)
- 텔레그램 즉시 알림
- 시스템 자원 모니터링
- 처리 성능
-
기술 스택 선정
- 애플리케이션
- Spring Boot 3.x.x
- Spring Kafka의 강력한 추상화와 Actuator를 통한 손쉬운 모니터링 연동 지원
- 메시징
- Apache Kafka (KRaft Mode)
- ZooKeeper 의존성 제거로 운영 복잡도 감소 및 메타데이터 처리 속도 향상
- 저장소
- PostgreSQL
- 시계열 데이터 처리에 유리한 파티셔닝 지원과 안정적인 트랜잭션 처리
- 압축 알고리즘
- Zstd
- LZ4 대비 높은 압축률, GZIP 대비 낮은 CPU 사용량으로 네트워크 대역폭 절약 최적화
- 모니터링
- Prometheus
- Grafana
- 애플리케이션
시스템 아키텍처
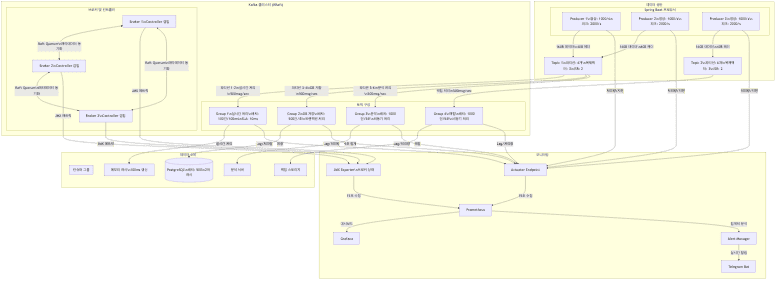
상세 아키텍처 설계
-
처리량 및 가용성 설계
- 수집 데이터 분석
- 정상 상태
- 초당 1000개 센서 데이터
- 순간 피크
- 초당 2000개로 증가 가능
- 메시지 크기
- 200바이트
- 온도/습도 데이터 160바이트
- 메시지 헤더 40바이트
- 정상 상태
- 브로커 구성 결정
- 브로커 3대 운영
- min.insync.replicas=2 설정 시 최소 3대 필요
- 브로커 1대 장애 발생 시에도 2대가 남아 ISR 조건 충족
- 브로커 2대 구성에서 1대 장애 시 쓰기 작업 불가로 서비스 중단
- 데이터 무손실과 서비스 지속성을 동시에 달성하려면 3대 이상 구성 필수
- KRaft 모드 (2025년 표준)
- Kafka 3.3+ 프로덕션 준비 완료
- ZooKeeper 완전 제거
- 브로커가 직접 메타데이터 관리
- Raft 합의 알고리즘 사용
- 운영 복잡도 감소, 성능 향상
- 브로커 3대 운영
- 파티션 및 데이터 관리 설계
- 기본 처리량 분석
- 단일 파티션 처리량 500 msg/s
- 필요 파티션 수 2000 ÷ 500 = 4개
- 네트워크 대역폭 2000 msg/s * 200B = 400KB/s
- Topic 1 컨슈머 그룹 고려
- 실시간 처리용 2개 파티션
- DB 저장용 2개 파티션
- 분석용 2개 파티션
- 총 6개 파티션 필요
- Topic 2 (백업) 파티션 설계
- 처리량 요구사항 Topic 1과 동일
- 파티션 수 6개 (2000 msg/s 처리 위해)
- 파티션 분배 단일 컨슈머 그룹에서 전체 파티션 처리
- 처리 방식 비동기 배치 처리로 성능 최적화
- 데이터 보존 정책
- Topic 1 7일 보관 (실시간/분석 데이터)
- Topic 2 30일 보관 (백업 데이터)
- 디스크 사용량 경고 임계치 80%
- 고가용성 및 정합성 전략
- 복제본 수 3 (1 리더 + 2 팔로워)
- ISR 설정 2 (데이터 유실 방지)
- Producer acks all (모든 ISR 확인)
- 리더 선출 preferred leader auto 활성화
- 재시도 정책 최대 3회, 지수 백오프
- 기본 처리량 분석
- 수집 데이터 분석
-
컨슈머 그룹 설계
- 실시간 처리
- 파티션 1-2번
- 배치 100건/100ms
- SLA 10ms 이내
- 데이터베이스 저장
- 파티션 3-4번
- 배치 500건/1초
- 트랜잭션 처리
- 데이터 분석
- 파티션 5-6번
- 배치 1000건/5초
- 비동기 처리
- 실시간 처리
환경 구성
본 가이드는 학습 편의를 위해
PLAINTEXT프로토콜을 사용하지만, 실제 운영 환경(Production)에서는 보안 컴플라이언스 준수를 위해 반드시 SASL/SSL을 적용하여 통신을 암호화하고 인증 절차를 거쳐야 함
Ubuntu 서버 준비
-
시스템 업데이트
1 2 3 4 5
# 패키지 매니저 업데이트 sudo apt update # 시스템 패키지 업그레이드 sudo apt upgrade -y
Java 개발 환경 설정
-
JDK 17 설치
1 2 3 4 5 6 7
# JDK 17 설치 sudo apt install openjdk-17-jdk # JAVA_HOME 환경변수 설정 echo "export JAVA_HOME=/usr/lib/jvm/java-17-openjdk-amd64" >> ~/.bashrc echo "export PATH=\$PATH:\$JAVA_HOME/bin" >> ~/.bashrc source ~/.bashrc
-
Gradle 설치
1 2 3 4 5 6
# SDKMAN 설치 curl -s "https://get.sdkman.io" | bash source "$HOME/.sdkman/bin/sdkman-init.sh" # Gradle 8.6 설치 sdk install gradle 8.6
Docker 설치
-
Docker & Docker Compose 설치
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
# Docker GPG 키 추가 sudo apt install ca-certificates curl gnupg sudo install -m 0755 -d /etc/apt/keyrings curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg # Docker 저장소 추가 echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu \ $(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \ sudo tee /etc/apt/sources.list.d/docker.list > /dev/null # Docker 엔진 설치 sudo apt update sudo apt install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin # 사용자를 docker 그룹에 추가 sudo usermod -aG docker $USER newgrp docker
Kafka 클러스터 구성
토픽 초기화 스크립트
-
scripts/kafka-init.sh파일 생성1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
#!/bin/bash # 토픽 생성 함수 create_topic() { kafka-topics.sh --create \ --if-not-exists \ --bootstrap-server kafka1:9092,kafka2:9093,kafka3:9094 \ --topic $1 \ --partitions $2 \ --replication-factor $3 \ --config cleanup.policy=delete \ --config retention.ms=$4 } # sensor-data 토픽 생성 (7일 보존, 복제 팩터 3) create_topic "sensor-data" 6 3 604800000 # sensor-data-backup 토픽 생성 (30일 보존, 복제 팩터 3) create_topic "sensor-data-backup" 6 3 2592000000 # DLT(Dead Letter Topic) 생성 (Spring Kafka 기본값: 원본토픽명.DLT) create_topic "sensor-data.DLT" 6 3 604800000 echo "Kafka topics initialized successfully"
[!TIP] > 스크립트 실행 권한
scripts/kafka-init.sh파일을 생성한 후에는 반드시 실행 권한을 부여해야 Docker가 실행할 수 있습니다.1
chmod +x scripts/kafka-init.shWindows 사용자 주의사항
Windows에서 파일을 작성할 경우 줄바꿈 문자가CRLF로 저장되어 스크립트 실행 에러가 발생할 수 있습니다. 에디터(VS Code 등)에서 줄바꿈 형식을 반드시LF로 변경하여 저장해주세요.
Docker Compose 설정
docker-compose.yml파일 생성-
Kafka 메모리 구성 원칙
- Heap
- JVM 객체, 메타데이터 저장
- 보통 4-6GB 최대 권장
- Page Cache
- OS 파일 시스템 캐시
- 나머지 메모리 전부 할당
- 컨테이너 메모리별 권장 설정
- 2GB
- Heap 1GB (50/50)
- 4GB
- Heap 2GB (50/50)
- 8GB
- Heap 4GB (50/50)
- 16GB 이상
- Heap 6GB (Heap 37.5%, Page Cache 62.5%)
- 메모리가 많을수록 Page Cache 비중을 높이는 것이 유리함
- 2GB
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193
version: "3.8" services: # Kafka Broker 1 - KRaft 모드 (Controller + Broker) kafka1: image: confluentinc/cp-kafka:7.5.1 container_name: kafka1 ports: - "9092:9092" - "9991:9991" volumes: - ./data/kafka1:/var/lib/kafka/data environment: # KRaft 기본 설정 KAFKA_NODE_ID: 1 KAFKA_PROCESS_ROLES: "broker,controller" KAFKA_CONTROLLER_QUORUM_VOTERS: "1@kafka1:19093,2@kafka2:19093,3@kafka3:19093" # 리스너 설정 (내부: 29092, 외부: 9092, 컨트롤러: 19093) KAFKA_LISTENERS: "INTERNAL://kafka1:29092,EXTERNAL://0.0.0.0:9092,CONTROLLER://kafka1:19093" KAFKA_ADVERTISED_LISTENERS: "INTERNAL://kafka1:29092,EXTERNAL://localhost:9092" KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: "CONTROLLER:PLAINTEXT,INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT" KAFKA_CONTROLLER_LISTENER_NAMES: "CONTROLLER" KAFKA_INTER_BROKER_LISTENER_NAME: "INTERNAL" # 클러스터 ID # 보안 경고: 아래 CLUSTER_ID는 학습용 예시이며, 프로덕션 환경에서 절대 사용 금지 # 각 클러스터는 고유한 ID가 필요하며, 동일 ID 사용 시 데이터 손상 위험 # 프로덕션 ID 생성: # docker run --rm confluentinc/cp-kafka:7.5.1 kafka-storage random-uuid CLUSTER_ID: "MkU3OEVBNTcwNTJENDM2Qk" # 절대 프로덕션에 사용 금지 # 복제 및 고가용성 KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 3 KAFKA_DEFAULT_REPLICATION_FACTOR: 3 KAFKA_MIN_INSYNC_REPLICAS: 2 KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 3 KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 2 # 데이터 처리 KAFKA_MESSAGE_MAX_BYTES: 1048576 KAFKA_COMPRESSION_TYPE: producer KAFKA_NUM_PARTITIONS: 6 # 로그 보존 KAFKA_LOG_RETENTION_HOURS: 168 KAFKA_LOG_SEGMENT_BYTES: 1073741824 # 모니터링 KAFKA_JMX_PORT: 9991 KAFKA_JMX_OPTS: -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false KAFKA_HEAP_OPTS: "-Xmx1G -Xms1G" deploy: resources: limits: memory: 2G reservations: memory: 1G healthcheck: test: [ "CMD-SHELL", "kafka-broker-api-versions --bootstrap-server localhost:9092 || exit 1", ] interval: 30s timeout: 10s retries: 3 # Kafka Broker 2 kafka2: image: confluentinc/cp-kafka:7.5.1 container_name: kafka2 ports: - "9093:9093" - "9992:9992" volumes: - ./data/kafka2:/var/lib/kafka/data environment: KAFKA_NODE_ID: 2 KAFKA_PROCESS_ROLES: "broker,controller" KAFKA_CONTROLLER_QUORUM_VOTERS: "1@kafka1:19093,2@kafka2:19093,3@kafka3:19093" # 리스너 설정 (내부: 29093, 외부: 9093, 컨트롤러: 19093) KAFKA_LISTENERS: "INTERNAL://kafka2:29093,EXTERNAL://0.0.0.0:9093,CONTROLLER://kafka2:19093" KAFKA_ADVERTISED_LISTENERS: "INTERNAL://kafka2:29093,EXTERNAL://localhost:9093" KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: "CONTROLLER:PLAINTEXT,INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT" KAFKA_CONTROLLER_LISTENER_NAMES: "CONTROLLER" KAFKA_INTER_BROKER_LISTENER_NAME: "INTERNAL" CLUSTER_ID: "MkU3OEVBNTcwNTJENDM2Qk" KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 3 KAFKA_DEFAULT_REPLICATION_FACTOR: 3 KAFKA_MIN_INSYNC_REPLICAS: 2 KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 3 KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 2 KAFKA_JMX_PORT: 9992 KAFKA_JMX_OPTS: -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false KAFKA_HEAP_OPTS: "-Xmx1G -Xms1G" deploy: resources: limits: memory: 2G # Kafka Broker 3 kafka3: image: confluentinc/cp-kafka:7.5.1 container_name: kafka3 ports: - "9094:9094" - "9993:9993" volumes: - ./data/kafka3:/var/lib/kafka/data environment: KAFKA_NODE_ID: 3 KAFKA_PROCESS_ROLES: "broker,controller" KAFKA_CONTROLLER_QUORUM_VOTERS: "1@kafka1:19093,2@kafka2:19093,3@kafka3:19093" # 리스너 설정 (내부: 29094, 외부: 9094, 컨트롤러: 19093) KAFKA_LISTENERS: "INTERNAL://kafka3:29094,EXTERNAL://0.0.0.0:9094,CONTROLLER://kafka3:19093" KAFKA_ADVERTISED_LISTENERS: "INTERNAL://kafka3:29094,EXTERNAL://localhost:9094" KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: "CONTROLLER:PLAINTEXT,INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT" KAFKA_CONTROLLER_LISTENER_NAMES: "CONTROLLER" KAFKA_INTER_BROKER_LISTENER_NAME: "INTERNAL" CLUSTER_ID: "MkU3OEVBNTcwNTJENDM2Qk" KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 3 KAFKA_DEFAULT_REPLICATION_FACTOR: 3 KAFKA_MIN_INSYNC_REPLICAS: 2 KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 3 KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 2 KAFKA_JMX_PORT: 9993 KAFKA_JMX_OPTS: -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false KAFKA_HEAP_OPTS: "-Xmx1G -Xms1G" deploy: resources: limits: memory: 2G # Prometheus prometheus: image: prom/prometheus:v2.48.0 container_name: prometheus ports: - "9090:9090" volumes: - ./prometheus/prometheus.yml:/etc/prometheus/prometheus.yml - ./data/prometheus:/prometheus command: - "--config.file=/etc/prometheus/prometheus.yml" - "--storage.tsdb.path=/prometheus" - "--storage.tsdb.retention.time=30d" # Grafana grafana: image: grafana/grafana:10.2.0 container_name: grafana ports: - "3000:3000" environment: - GF_SECURITY_ADMIN_USER=admin - GF_SECURITY_ADMIN_PASSWORD=admin volumes: - ./data/grafana:/var/lib/grafana depends_on: - prometheus # Alert Manager alertmanager: image: prom/alertmanager:v0.26.0 container_name: alertmanager ports: - "9095:9093" volumes: - ./alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml # Kafka 토픽 초기화 kafka-init: image: confluentinc/cp-kafka:7.5.1 depends_on: kafka1: condition: service_healthy kafka2: condition: service_healthy kafka3: condition: service_healthy volumes: - ./scripts/kafka-init.sh:/scripts/kafka-init.sh command: > bash -c " echo 'KRaft cluster ready' && /scripts/kafka-init.sh"
- Heap
모니터링 설정
-
Prometheus 설정 (
prometheus/prometheus.yml)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35
global: scrape_interval: 15s # 메트릭 수집 주기 evaluation_interval: 15s # 규칙 평가 주기 rule_files: - "rules/*.yml" # 알림 규칙 파일 alerting: alertmanagers: - static_configs: - targets: ["alertmanager:9093"] scrape_configs: - job_name: "kafka" static_configs: - targets: - "kafka1:9991" # Kafka 브로커 1 JMX - "kafka2:9992" # Kafka 브로커 2 JMX - "kafka3:9993" # Kafka 브로커 3 JMX - job_name: "spring-actuator" metrics_path: "/actuator/prometheus" scrape_interval: 5s static_configs: - targets: # macOS/Windows Docker Desktop용 설정 # Ubuntu 환경에서는 작동하지 않음 # Ubuntu에서는 docker-compose.yml의 prometheus 서비스에 # extra_hosts: - "host.docker.internal:host-gateway" 추가 필요 - "host.docker.internal:8080" # Spring Boot 애플리케이션 - job_name: "node-exporter" static_configs: - targets: - "node-exporter:9100" # 시스템 메트릭
-
Alert Manager 설정 (
alertmanager/alertmanager.yml)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32
global: resolve_timeout: 5m route: receiver: "telegram" group_by: ["alertname", "severity", "consumer_group"] group_wait: 10s group_interval: 10s repeat_interval: 1h routes: - match: severity: critical group_wait: 0s repeat_interval: 5m - match: severity: warning group_wait: 30s repeat_interval: 15m receivers: - name: "telegram" telegram_configs: - bot_token: "YOUR_BOT_TOKEN" chat_id: YOUR_CHAT_ID parse_mode: "HTML" api_url: "https://api.telegram.org" message: |- [Alert] <b>{{ .GroupLabels.alertname }}</b> 심각도: {{ .Labels.severity }} 컨슈머 그룹: {{ .Labels.consumer_group }} {{ .Annotations.description }}
클러스터 실행
-
도커 컴포즈로 시작
1 2 3 4 5 6 7 8
# 컨테이너 실행 docker-compose up -d # 컨테이너 상태 확인 docker-compose ps # 로그 확인 docker-compose logs -f
Spring Boot 애플리케이션 개발
Gradle 의존성
-
build.gradle설정1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38
plugins { id 'java' id 'org.springframework.boot' version '3.4.1' id 'io.spring.dependency-management' version '1.1.4' } group = 'com.example' version = '1.0.0' sourceCompatibility = '17' repositories { mavenCentral() } dependencies { // Spring Boot implementation 'org.springframework.boot:spring-boot-starter' implementation 'org.springframework.boot:spring-boot-starter-web' implementation 'org.springframework.kafka:spring-kafka' // Database & Caching implementation 'org.springframework.boot:spring-boot-starter-data-jpa' implementation 'org.postgresql:postgresql' implementation 'org.hibernate.orm:hibernate-jcache' implementation 'org.ehcache:ehcache:3.10.8' // Observability implementation 'org.springframework.boot:spring-boot-starter-actuator' implementation 'io.micrometer:micrometer-registry-prometheus' // lombok compileOnly 'org.projectlombok:lombok' annotationProcessor 'org.projectlombok:lombok' // 테스트 testImplementation 'org.springframework.boot:spring-boot-starter-test' testImplementation 'org.springframework.kafka:spring-kafka-test' }
애플리케이션 설정
application.yml설정
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108
server: shutdown: graceful # 톰캣 종료 시 대기 spring: lifecycle: timeout-per-shutdown-phase: 30s # 최대 30초 대기 # Kafka 설정 kafka: bootstrap-servers: localhost:9092,localhost:9093,localhost:9094 producer: key-serializer: org.apache.kafka.common.serialization.StringSerializer value-serializer: org.springframework.kafka.support.serializer.JsonSerializer acks: all # 모든 ISR 확인 retries: 3 # 재시도 정책: 최대 3회 retry-backoff-ms: 1000 # 지수 백오프 시작값 batch-size: 16384 # 16KB (네트워크 패킷 효율과 지연 시간의 균형점) buffer-memory: 33554432 # 32MB (프로듀서가 전송 대기 중인 레코드를 버퍼링할 메모리) # 압축 알고리즘 선택 가이드 # # 시나리오별 권장: # 1. 네트워크 대역폭이 병목 (원격 데이터센터 간 복제) # → zstd (높은 압축률로 전송 데이터량 최소화) # # 2. 실시간 처리가 중요 (IoT 센서, 실시간 알림) # → lz4 (낮은 지연시간, 빠른 압축/해제) # # 3. 대부분의 일반적인 경우 # → snappy (압축률과 속도의 균형) # # 현재 설정: zstd (스마트 팩토리 환경에서 네트워크 비용 절감 우선) compression-type: zstd max-request-size: 1048576 # 최대 요청 크기 1MB # 공통 컨슈머 설정 consumer: key-deserializer: org.apache.kafka.common.serialization.StringDeserializer value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer enable-auto-commit: false # 수동 커밋 auto-offset-reset: earliest # 오프셋 초기화 heartbeat-interval: 3000 # 하트비트 간격 session-timeout-ms: 45000 # 세션 타임아웃 # 실시간 처리 컨슈머 설정 consumer-realtime: group-id: realtime-processor max-poll-records: 100 # 100건/100ms fetch-max-wait: 100 # 100ms fetch-min-bytes: 1 # 최소 페치 크기 max-partition-fetch-bytes: 1048576 # 데이터베이스 저장 컨슈머 설정 consumer-database: group-id: database-processor max-poll-records: 500 # 500건/1초 fetch-max-wait: 1000 # 1초 isolation-level: read_committed # 트랜잭션 처리 fetch-min-bytes: 1024 max-partition-fetch-bytes: 1048576 # 데이터 분석 컨슈머 설정 consumer-analytics: group-id: analytics-processor max-poll-records: 1000 # 1000건/5초 fetch-max-wait: 5000 # 5초 fetch-min-bytes: 2048 max-partition-fetch-bytes: 1048576 # Database 설정 datasource: # PostgreSQL 배치 삽입 최적화 # reWriteBatchedInserts=true 파라미터 필수 # 이 파라미터 없이는 jdbc.batch_size 설정의 성능 향상이 미미함 url: jdbc:postgresql://localhost:5432/kafka_stream?reWriteBatchedInserts=true username: postgres password: postgres driver-class-name: org.postgresql.Driver hikari: maximum-pool-size: 10 minimum-idle: 5 # JPA 설정 jpa: hibernate: ddl-auto: update properties: hibernate: dialect: org.hibernate.dialect.PostgreSQLDialect format_sql: true show_sql: true generate_statistics: true cache: use_second_level_cache: true region.factory_class: org.hibernate.cache.jcache.JCacheRegionFactory provider_configuration_file_path: ehcache.xml jdbc: batch_size: 500 batch_versioned_data: true order_inserts: true order_updates: true # 액추에이터 설정 management: endpoints: web: exposure: include: health,metrics,prometheus metrics: tags: application: ${spring.application.name}
데이터 모델
-
SensorDataRepository.java- 센서 데이터 레포지토리1 2 3 4 5 6 7
/** * 센서 데이터 영속성을 관리하는 리포지토리 인터페이스 * JpaRepository를 상속하여 기본적인 CRUD 작업과 페이징 기능을 제공 */ @Repository public interface SensorDataRepository extends JpaRepository<SensorData, Long> { }
-
SensorData.java- 센서 데이터 모델1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32
@Data @Entity @Table(name = "sensor_data", uniqueConstraints = { @UniqueConstraint(name = "uk_sensor_timestamp", columnNames = {"sensor_id", "timestamp"}) }) @Cacheable @org.hibernate.annotations.Cache(usage = org.hibernate.annotations.CacheConcurrencyStrategy.READ_WRITE) public class SensorData { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; @Column(name = "sensor_id", nullable = false) @Index(name = "idx_sensor_id") // 조회 성능 향상을 위한 인덱스 생성 private String sensorId; @Column(nullable = false) private Double temperature; // 온도 데이터 컬럼 @Column(nullable = false) private Double humidity; // 습도 데이터 컬럼 @Column(nullable = false) @Index(name = "idx_timestamp") // 시간 기반 조회를 위한 인덱스 private LocalDateTime timestamp; // 측정 시간 컬럼 // 낙관적 락을 위한 버전 관리 // 동시성 제어: 여러 트랜잭션이 동시에 같은 데이터를 수정하는 것을 방지 @Version private Long version; }
메시지 생산자
-
KafkaProducerConfig.java- 생산자 설정1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38
/** * Kafka 프로듀서 관련 설정을 담당하는 설정 클래스 * 메시지 직렬화, 브로커 연결 등 프로듀서의 핵심 설정을 정의 */ @Configuration // 스프링 설정 클래스임을 표시 public class KafkaProducerConfig { /** * Kafka 프로듀서 팩토리 빈 생성 * 프로듀서의 기본 설정을 구성하고 인스턴스를 생성하는 팩토리 제공 * * @return 설정이 완료된 프로듀서 팩토리 */ @Bean public ProducerFactory<String, SensorData> producerFactory() { Map<String, Object> config = new HashMap<>(); // 브로커 서버 리스트 설정 config.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092,localhost:9093"); // 메시지 키의 직렬화 방식 설정 config.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class); // 메시지 값의 직렬화 방식 설정 (JSON 형식) // TIP: 대용량 처리 및 스키마 관리가 필요한 상용 환경에서는 Avro + Schema Registry 사용 권장 config.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class); // 멱등성 프로듀서 활성화 (중복 전송 방지 및 순서 보장) config.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true); return new DefaultKafkaProducerFactory<>(config); } /** * Kafka 템플릿 빈 생성 * * @return 설정된 Kafka 템플릿 */ @Bean public KafkaTemplate<String, SensorData> kafkaTemplate() { return new KafkaTemplate<>(producerFactory()); } }
-
SensorDataProducer.java- 센서 데이터 생산1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47
/** * 센서 데이터를 생성하고 Kafka로 전송하는 서비스 클래스 * 실시간으로 센서 데이터를 시뮬레이션하고 Kafka 토픽으로 전송 */ @Service @Slf4j @RequiredArgsConstructor public class SensorDataProducer { // Kafka로 메시지를 전송하기 위한 템플릿 private final KafkaTemplate<String, SensorData> kafkaTemplate; // 센서 데이터가 전송될 Kafka 토픽 이름 private static final String TOPIC = "sensor-data"; /** * 센서 데이터 생성 및 전송 메서드 * 매 밀리초마다 실행되어 임의의 센서 데이터를 생성하고 Kafka로 전송 * * 주의사항 * 자바 스케줄러는 스레드 풀 상황과 OS 스케줄링의 영향을 받아 1ms 주기를 정확히 보장하기 어려움 * 실제 초당 1000건(1000 TPS)의 일정한 부하를 생성하려면 아래 방법 권장 * 1. CompletableFuture 등을 활용한 비동기 병렬 전송 * 2. ExecutorService를 사용한 멀티 스레드 부하 생성 * 3. JMeter, nGrinder 등 전문 부하 테스트 도구 사용 (권장) */ //@Scheduled(fixedRate = 1) // @Scheduled는 단일 스레드로 동작하므로 고부하 테스트에 부적합 public void generateData() { // 실전에서는 외부 트리거네 ExecutorService를 통해 호출 권장 SensorData data = new SensorData(); data.setSensorId("SENSOR-" + ThreadLocalRandom.current().nextInt(1, 1001)); // 1부터 1000까지의 센서 ID 임의 생성 data.setTemperature(20.0 + ThreadLocalRandom.current().nextDouble() * 10); // 20-30도 사이의 임의 온도 생성 data.setHumidity(40.0 + ThreadLocalRandom.current().nextDouble() * 20); // 40-60% 사이의 임의 습도 생성 data.setTimestamp(LocalDateTime.now()); // 현재 시간 기록 // CompletableFuture를 사용한 비동기 전송 kafkaTemplate.send(TOPIC, data.getSensorId(), data) .whenComplete((result, ex) -> { if (ex == null) { log.info("Sent data: {} with offset: {}", data, result.getRecordMetadata().offset()); } else { log.error("Unable to send data: {} due to: {}", data, ex.getMessage()); } }); } }
메시지 소비자
-
KafkaConsumerConfig.java- 소비자 설정1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72
/** * Kafka 컨슈머 관련 설정을 담당하는 설정 클래스 * 메시지 역직렬화, 컨슈머 그룹, 배치 처리 등 컨슈머의 핵심 설정을 정의 */ @Configuration public class KafkaConsumerConfig { /** * Kafka 컨슈머 팩토리 빈 생성 * 컨슈머의 기본 설정을 구성하고 인스턴스를 생성 * * @return 설정이 완료된 컨슈머 팩토리 */ @Bean public ConsumerFactory<String, SensorData> consumerFactory() { Map<String, Object> config = new HashMap<>(); // 브로커 서버 리스트 설정 config.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092,localhost:9093"); // 컨슈머 그룹 ID 설정 config.put(ConsumerConfig.GROUP_ID_CONFIG, "sensor-group"); // TIP: K8s/Docker 환경에서는 'group.instance.id'를 설정(Static Membership)하여 불필요한 리밸런싱 방지 권장 // 메시지 키의 역직렬화 방식 설정 config.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); // 메시지 값의 역직렬화 방식 설정 (JSON 형식) config.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class); return new DefaultKafkaConsumerFactory<>(config); } /** * Kafka 리스너 컨테이너 팩토리 빈 생성 * * @return 설정된 리스너 컨테이너 팩토리 */ @Bean public ConcurrentKafkaListenerContainerFactory<String, SensorData> kafkaListenerContainerFactory() { ConcurrentKafkaListenerContainerFactory<String, SensorData> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); factory.setBatchListener(true); // 배치 처리 모드 활성화 factory.setConcurrency(3); // 병렬 처리를 위한 컨슈머 스레드 수 설정 factory.setCommonErrorHandler(errorHandler()); // 에러 핸들러 설정 (DLT) factory.getContainerProperties().setPollTimeout(3000); // 폴링 대기 시간 설정(ms) return factory; } /** * 에러 핸들러 빈 생성 (DLT 설정) * 실패 시 재시도(최대 3회, 지수 백오프) 후 Dead Letter Topic으로 전송 */ @Bean public DefaultErrorHandler errorHandler() { // DeadLetterPublishingRecoverer: 실패 메시지를 DLT로 전송하는 복구 로직 // 기본적으로 topic-name.DLT 토픽으로 전송됨 DeadLetterPublishingRecoverer recoverer = new DeadLetterPublishingRecoverer(kafkaTemplate()); // ExponentialBackOff: 지수 백오프 (1초 → 2초 → 4초, 최대 3회) // 일시적 장애 복구에 더 효과적 ExponentialBackOff backOff = new ExponentialBackOff(1000L, 2.0); backOff.setMaxElapsedTime(10000L); // 최대 10초 // 또는 고정 간격 사용 시: // FixedBackOff backOff = new FixedBackOff(1000L, 3L); return new DefaultErrorHandler(recoverer, backOff); } /** * KafkaTemplate 빈 주입 (Recoverer에서 사용) */ @Autowired private KafkaTemplate<String, SensorData> kafkaTemplate; }
-
SensorDataConsumer.java- 센서 데이터 소비1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49
/** * 센서 데이터를 소비하고 처리하는 서비스 클래스 * Kafka에서 메시지를 배치로 수신하여 데이터베이스에 저장하고 이상 징후를 모니터링 */ @Service @Slf4j @RequiredArgsConstructor public class SensorDataConsumer { private final SensorDataRepository sensorDataRepository; // 센서 데이터 저장을 위한 리포지토리 /** * Kafka 토픽으로부터 센서 데이터를 배치로 수신하고 처리하는 메서드 * 데이터베이스에 배치 저장하고 온도 이상 징후를 모니터링 * * @param dataList 수신된 센서 데이터 목록 * @param partitions 메시지가 수신된 파티션 번호 목록 * @param offsets 메시지의 오프셋 목록 * @throws RuntimeException 배치 처리 실패 시 발생 */ @KafkaListener( topics = "sensor-data", // 구독할 토픽 groupId = "db-saver-group", // 컨슈머 그룹 ID containerFactory = "kafkaListenerContainerFactory" // 컨테이너 팩토리 ) @Transactional // 트랜잭션 처리를 위한 어노테이션 public void consume(@Payload List<SensorData> dataList) { log.info("Received batch of {} records", dataList.size()); try { // JPA를 사용하여 데이터를 배치로 저장 sensorDataRepository.saveAll(dataList); // 고온 경고를 위한 메트릭 기록 및 모니터링 for (SensorData data : dataList) { if (data.getTemperature() > 25.0) { log.warn("High temperature alert: {}", data); } } } catch (Exception e) { log.error("Error processing batch: {}", e.getMessage()); // 배치 처리 중 에러 발생 시 예외를 던져 DLT(Dead Letter Topic) 로직을 트리거 // DefaultErrorHandler가 이를 감지하여 재시도 후 실패 시 DLT로 전송 throw new RuntimeException("Failed to process batch", e); } } }
외부 브로커 없이도 테스트가 가능한
Testcontainers라이브러리가 있음 Docker가 설치된 환경이라면 테스트 코드 실행 시점에 격리된 Kafka 컨테이너를 자동으로 띄우고 종료해주어, Jenkins나 GitHub Actions에서도 안정적인 테스트가 가능함
트러블슈팅 및 운영 팁
자주 발생하는 오류 가이드
-
Broker may not be available
- 원인
- Docker 컨테이너 간 네트워크 DNS 해석 실패, 혹은 로컬 호스트와 컨테이너 간의 포트 매핑 불일치
- 해결
docker-compose.yml의KAFKA_ADVERTISED_LISTENERS설정이 클라이언트가 접근하는 주소와 일치하는지 확인 (Spring Boot가 Docker 외부에서 실행 중이라면localhost:9092등으로 접근)
- 원인
-
CommitFailedException
- 원인
- 컨슈머의 메시지 처리 시간이
max.poll.interval.ms(기본 5분)를 초과하여 리밸런싱이 발생함
- 컨슈머의 메시지 처리 시간이
- 해결
max.poll.records를 줄여 배치 크기를 감소시키거나, 처리 로직을 최적화
- 원인
-
NotLeaderOrFollowerException
- 원인
- 브로커 장애 감지, 리더 선출 과정, 또는 새 브로커 추가 직후 메타데이터 동기화 지연
- 해결
- 일시적인 현상일 수 있으므로
retries설정에 따라 자동 재시도됨 - 지속될 경우 브로커 로그 확인 필요
- 일시적인 현상일 수 있으므로
- 원인
분산 추적 (Distributed Tracing) 도입
- MSA 환경에서 메시지 흐름 추적의 한계
- 메트릭만으로는 “어디서” 지연이 발생했는지 정확히 파악하기 어려움
- OpenTelemetry (Zipkin/Jaeger) 도입 권장
- Producer → Kafka → Consumer로 이어지는 전체 트랜잭션을 추적 ID(Trace ID)로 연결
- Spring Boot 3.x부터는 Micrometer Tracing을 통해 손쉽게 연동 가능
Transactional Outbox
- 분산 시스템 데이터 정합성 보장
- 문제점
- DB 저장과 Kafka 발행이 원자적(Atomic)이지 않음
- DB 커밋 후 Kafka 발행 실패 시 데이터 불일치 발생
- Kafka 발행 후 DB 롤백 시 “없는 데이터”가 이벤트로 발행됨
- 해결책
- Outbox Pattern
-
- 동일 트랜잭션 내에서 비즈니스 데이터와 메시지 발행 내용을 ‘Outbox’ 테이블에 함께 저장
-
- 별도의 Relay 프로세스(예 - Debezium, Polling Publisher)가 Outbox 테이블을 모니터링하여 Kafka로 발행
-
- 발행 후 Outbox 데이터 삭제 또는 상태 변경
- 구현 방법 (Spring Boot)
ApplicationEventPublisher로 이벤트 발행@TransactionalEventListener(phase = AFTER_COMMIT)을 사용하여 트랜잭션 성공 시에만 Kafka 발행 시도- 실패 시 재시도 로직이나 Outbox 테이블 저장 로직 수행
다음 단계
Apache Kafka 모니터링과 운영 - Prometheus & Grafana