Apache Kafka 시리즈
- Apache Kafka 기본 개념 - 메시징 시스템의 이해
- Apache Kafka 파티션과 컨슈머 그룹
- Apache Kafka 복제와 고가용성 - 데이터 안정성 보장 ← 현재 글
- Apache Kafka 성능 튜닝과 운영 - 최적화
- Spring Boot와 KRaft를 활용한 Apache Kafka 개발
- Apache Kafka 모니터링과 운영 - Prometheus & Grafana
개요
- Kafka의 핵심 특징인 데이터 복제(Replication) 메커니즘과 이를 통한 고가용성(High Availability) 보장 원리를 분석함
- ISR(In-Sync Replicas) 개념과 리더 선출 과정, 그리고 데이터 유실 방지를 위한 최적의 브로커 설정 전략을 제시함
고급 기능
데이터 일관성과 안정성
-
메시지 전송 보장 수준 (acks)
acks=0- 전송 즉시 성공으로 간주
- 속도는 가장 빠르지만 데이터 유실 위험 높음
acks=1- 리더가 메시지 수신 확인 시 성공
- 적절한 속도와 안정성의 균형
acks=all- 모든 복제본이 메시지 수신 확인 시 성공
- 가장 안전하지만 속도는 느림
1 2 3 4 5 6 7 8 9 10 11 12 13
// 프로듀서 설정 Properties props = new Properties(); // 빠른 처리 속도 우선 props.put("acks", "0"); // 안정성과 속도의 균형 props.put("acks", "1"); // 데이터 안정성 우선 props.put("acks", "all"); KafkaProducer<String, String> producer = new KafkaProducer<>(props);
-
복제 설정
replication.factor- 각 파티션의 복제본 수 지정
- 높을수록 안전하지만 리소스 사용량 증가
- 일반적으로 3 설정 (1 리더 + 2 팔로워)
min.insync.replicas- 최소 동기화 복제본 수
- 이 수보다 적으면 쓰기 거부
- 데이터 안정성 보장을 위한 중요 설정
- 고가용성을 위한 브로커 구성
min.insync.replicas=2설정 시 최소 3대의 브로커 권장- 브로커 1대 장애 발생 시에도 2대가 남아 ISR 조건 충족
- 브로커 2대 구성 시 1대 장애 발생하면 ISR이 1대가 되어 쓰기 작업 불가
- 데이터 무손실과 서비스 지속성을 동시에 달성하려면 브로커 3대 이상 구성 권장
-
acks와 min.insync.replicas 관계
acks min.insync.replicas 동작 유실 가능성 1 N/A 리더만 확인 리더 장애 시 유실 가능 all 1 리더만 확인 (acks=1과 동일) 리더 장애 시 유실 가능 all 2 리더 + 최소 1개 팔로워 확인 데이터 무손실 보장
1 2 3 4 5 6
# 토픽 생성 시 복제 설정 kafka-topics.sh --create \ # 토픽 생성 명령 --bootstrap-server localhost:9092 \ # Kafka 브로커 주소 --topic my-topic \ # 생성할 토픽 이름 --partitions 3 \ # 파티션 수 (병렬 처리 단위) --replication-factor 3 # 복제본 수 (데이터 안정성)
1 2 3 4 5
# 브로커 설정 파일에서 최소 동기화 복제본 설정 # 고가용성을 위해 브로커 3대 이상 구성 권장 min.insync.replicas=2 unclean.leader.election.enable=false
unclean.leader.election.enable설정 가이드false(기본값, 권장)- 데이터 일관성 우선
- ISR에 복제본이 없으면 파티션 사용 불가 (쓰기 차단)
- 트레이드오프
- 모든 ISR 브로커 동시 장애 시 서비스 중단
true(특수 상황)- 서비스 가용성 우선
- ISR이 없어도 Out-of-Sync 복제본을 리더로 승격
- 트레이드오프
- 최근 데이터 유실 가능 (보통 수백~수천 메시지)
- 권장 전략
- 금융/결제
false(데이터 유실 절대 불가)
- 로그/메트릭
true고려 가능 (일부 유실 허용)
- 금융/결제
-
데이터 정합성 보장
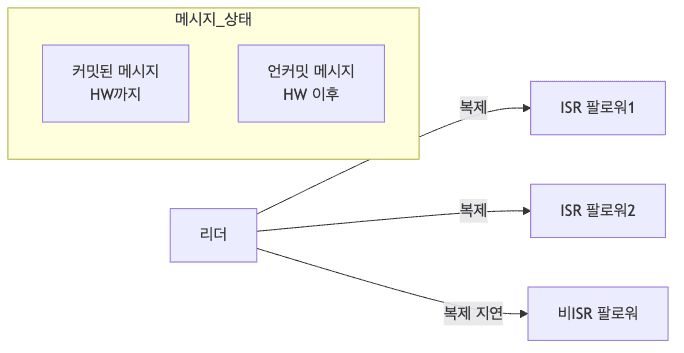
- ISR(In-Sync Replicas)
- 리더와 제대로 동기화된 복제본들의 집합
replica.lag.time.max.ms설정 시간 내에 리더와 동기화된 복제본만 포함- ISR이 아닌 복제본은 장애 복구 시 리더가 될 수 없음
- 파티션 리더 선출
- 리더 장애 시 ISR 중에서만 새 리더 선출
- 가장 최신 데이터(높은 LEO)를 가진 복제본이 우선 선출
- ISR 아닌 복제본은 데이터 유실 위험으로 리더가 될 수 없음
- 커밋된 메시지 처리
- High Watermark(HW)
- 모든 ISR이 복제 완료한 최신 오프셋
- 소비자는 HW까지의 메시지만 읽을 수 있음
- 리더 변경 시에도 HW 이후 메시지는 롤백되어 데이터 일관성 유지
- High Watermark(HW)
- ISR(In-Sync Replicas)
장애 복구 시뮬레이션
- 브로커 장애 발생 시 ISR이 어떻게 변화하는지 직접 확인해 봄
1
2
3
4
5
6
7
8
9
10
11
12
# 1. 현재 토픽의 ISR 상태 확인 (정상 상태: 1,2,3 모두 존재)
kafka-topics.sh --bootstrap-server localhost:9092 --topic sensor-data --describe
# 2. 브로커 2번 강제 종료 (장애 발생)
docker stop kafka2
# 3. ISR 변화 확인 (브로커 2가 빠졌는지 확인)
kafka-topics.sh --bootstrap-server localhost:9092 --topic sensor-data --describe
# 4. 브로커 2번 재기동 및 복구 확인
docker start kafka2
# 잠시 후 ISR에 다시 합류하는지 확인