Apache Kafka 시리즈
개요
- Kafka의 핵심 모델인 파티션(Partition)의 분산 저장 원리와 컨슈머 그룹(Consumer Group)을 통한 병렬 처리 메커니즘을 설명함
- 대용량 데이터 처리의 핵심인 파티셔닝 전략과 컨슈머 스케일아웃 방법을 다룸
데이터 분산 저장 (Partition)
- 각 토픽은 여러 개의 파티션으로 나뉘어 저장됨
- 하나의 큰 책을 여러 장으로 나누어 보관하는 것과 같음

- 장점
- 대량의 데이터를 나눠서 처리 가능
- 여러 소비자가 동시에 데이터 처리 가능
- 데이터 처리 속도 향상
데이터 흐름
메시지가 전달되는 과정
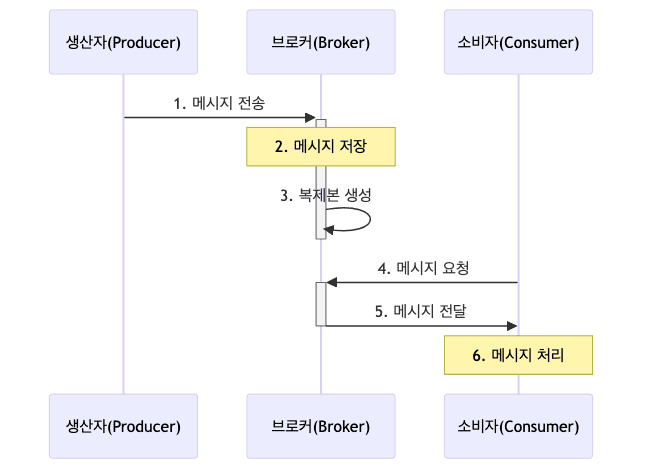
- ex)
- 사용자가 온라인 쇼핑몰에서 주문 버튼 클릭
- 주문 시스템(Producer)이 주문 데이터를 Kafka로 전송
- Kafka가 주문 데이터를 ‘주문’ 토픽에 안전하게 저장
- 결제 시스템(Consumer)이 새로운 주문 데이터를 가져감
- 배송 시스템(Consumer)이 동일한 주문 데이터로 배송 처리
데이터 처리 방식
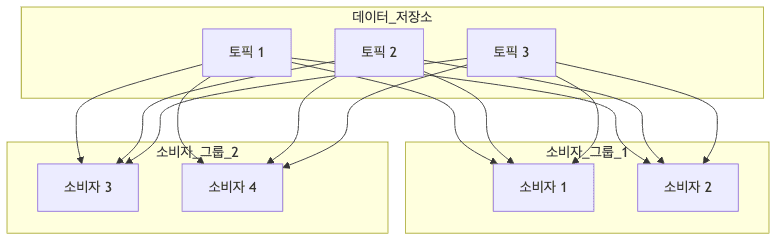
-
병렬 처리
- 여러 소비자가 동시에 데이터 처리
- 처리 속도 향상
- 부하 분산
-
독립적 처리
- 각 소비자 그룹은 독립적으로 데이터 처리
- 한 그룹의 문제가 다른 그룹에 영향을 주지 않음
- 다양한 용도로 같은 데이터 사용 가능
-
순서 보장
- 같은 키를 가진 메시지는 순서대로 처리
- ex)
- 같은 사용자의 주문은 순서대로 처리
- 다른 사용자의 주문은 병렬로 처리
컨슈머 그룹 운영의 규칙
- 병렬 처리를 위해 컨슈머를 늘릴 때 반드시 고려해야 할 Kafka만의 제약 사항임
컨슈머와 파티션의 1:1 매핑 규칙
- 기본 원칙
- 파티션은 하나의 컨슈머 그룹 내에서 오직 하나의 컨슈머에게만 할당됨
- 하나의 컨슈머는 여러 파티션을 담당할 수 있음
- 확장의 한계 (Idle Consumer)
- 컨슈머 개수는 파티션 개수보다 많을 수 없음
- ex) 파티션이 3개인데 컨슈머를 4개로 늘리면, 1개의 컨슈머는 할당받을 파티션이 없어 유휴 상태(Idle)가 됨
- 스케일 아웃 전략
- 처리량을 늘리려면 파티션 개수와 컨슈머 개수를 함께 늘려야 함
리밸런싱 (Rebalancing)
- 개념
- 컨슈머 그룹에 새로운 컨슈머가 추가되거나 기존 컨슈머가 제외될 때, 파티션 소유권을 다시 분배하는 과정
- 발생 시점
- 컨슈머 추가/종료 시(스케일 아웃/인)
- 컨슈머 장애 감지 시(Heartbeat 실패)
- 주의사항 (Stop-the-World)
- 리밸런싱이 진행되는 동안은 일시적으로 메시지 처리가 중단될 수 있음
- 잦은 리밸런싱은 성능 저하의 주원인이므로, 운영 환경에서는 불필요한 리밸런싱을 줄이는 설정(Static Membership 등)이 중요함
적정 파티션 개수 산정 가이드
- “파티션은 많을수록 좋은가?”에 대한 답은 “아니오”임
- 파티션 개수를 결정할 때는 목표 처리량(Throughput)과 리소스 오버헤드 사이의 트레이드오프를 고려해야 함
파티션 개수 산정 공식
- 목표 처리량 기준
- 단순 공식
파티션 수 = Max(목표 프로듀서 처리량, 목표 컨슈머 처리량)
- 실무 공식 (성장률 30% 여유분 포함 권장)
필요 파티션 수 = MAX(처리량 기준, 컨슈머 기준, 보관 기준)- 처리량 기준
CEIL((예상 최대 처리량 * 1.3) / 단일 파티션 처리량)
- 컨슈머 기준
목표 병렬 처리 수준- 일반적으로 처리량 기준과 동일하게 설정
- 컨슈머는 파티션보다 많을 수 없음 (초과 시 유휴 컨슈머 발생)
- 보관 기준
CEIL((일일 데이터량 * 보관일수 * 1.3) / (단일 파티션 권장 최대 크기 * 0.7))
- 처리량 기준
- 계수 설명
- 1.3 = 성장률 여유분 (30%)
- 0.7 = 안전율 (파티션당 최대 크기의 70%만 사용)
- CEIL = 올림 함수
- 실제 환경에서는 컨슈머 처리 로직의 CPU 부하가 더 큰 병목인 경우가 많음
- 단순 공식
- 예시
- 프로듀서가 초당 100MB를 전송하고, 컨슈머 하나가 초당 50MB를 처리할 수 있다면?
- 최소 파티션 수 = CEIL(100MB / 50MB) = 2개
- 성장률 고려 시 CEIL(100 * 1.3 / 50) = 3개 이상으로 설정하는 것이 안전함
파티션 과다 설정 시 문제점
- 장애 복구 시간 증가
- 브로커 장애 시 수천 개의 파티션에 대해 리더 선출(Leader Election)이 발생하면 수 초~수 분간 서비스 중단(Downtime) 발생
- 메모리 리소스 낭비
- 파티션마다 파일 핸들과 버퍼 메모리를 점유하므로, 지나치게 많으면 브로커 OOM(Out of Memory) 위험 증가
컨슈머 랙 (Consumer Lag)과 성능 모니터링
- Kafka 운영에서 가장 중요한 지표는 Consumer Lag임
Consumer Lag란?
- 정의
Lag = (최신 메시지 오프셋) - (컨슈머가 커밋한 오프셋)- 프로듀서가 데이터를 쌓는 속도보다 컨슈머가 처리하는 속도가 느려서 발생하는 지연 건수
- 위험성 (Why it matters)
- 실시간성 저하
- Lag가 커지면 “실시간 알림”이 10분 뒤에 오는 현상 발생
- 데이터 유실 가능성
- Lag가 토픽의 보존 기간(Retention Period)을 넘어서면, 아직 처리하지 못한 데이터가 Kafka에서 삭제될 수 있음
- 실시간성 저하
Lag 발생 시 대응 전략
- 컨슈머 로직 최적화
- DB Bulk Insert 적용, 불필요한 연산 제거 등으로 처리 속도 향상
- 파티션 & 컨슈머 확장 (Scale-out)
- 가장 확실한 해결책
- 파티션 수를 늘리고 그에 맞춰 컨슈머 인스턴스도 함께 증설하여 병렬 처리량 극대화
파티셔닝 전략
- 프로듀서가 데이터를 보낼 때 어떤 파티션에 저장할지 결정하는 알고리즘
- 비즈니스 요건(순서 보장 여부)에 따라 적절한 전략 선택 필요
라운드 로빈 (Round Robin) - 키가 없는 경우
- 동작 방식
- 메시지 키(Key)가
null인 경우 사용
- 메시지 키(Key)가
- 특징
- 데이터를 모든 파티션에 균등하게 분배
- 특정 파티션에 데이터가 몰리는 현상 방지
- Kafka 2.4+ 부터는 Sticky Partitioning이 적용됨
- 하나의 배치가 찰 때까지 기다렸다가 한 번에 전송하여 성능 효율 극대화
- 적합한 경우
- 순서가 중요하지 않고 최대 처리량이 필요한 경우 (로그 수집 등)
키 기반 파티셔닝 (Key-based Partitioning) - 키가 있는 경우
- 동작 방식
- 메시지 키의 해시값(Hash)을 구해서 특정 파티션에 매핑
Partition = hash(Key) % Partition_Count
- 메시지 키의 해시값(Hash)을 구해서 특정 파티션에 매핑
- 특징
- 동일한 키를 가진 메시지는 항상 동일한 파티션으로 전송됨
- 이를 통해 순서 보장(Ordering) 가능
- 주의사항 (Data Skew)
- 특정 키(예: ‘슈퍼 인플루언서’ ID)의 데이터가 너무 많으면 특정 파티션에만 데이터가 몰려 처리 지연 발생 가능
- 키의 분산도(Cardinality)가 높은 값을 키로 선정해야 함
- ex) 주문 ID는 좋음, 성별은 나쁨
커스텀 파티셔닝 (Custom Partitioning)
- 동작 방식
- 개발자가 직접 파티션 할당 로직을 구현
- 특징
- 특정 조건의 데이터(예: VIP 고객)를 전용 고성능 파티션으로 보내거나 특정 파티션 제외 가능
- 구현
Partitioner인터페이스를 상속받아partition()메서드 재정의
활용 사례
로그 수집
- 실시간 로그 처리
- 시스템/애플리케이션 로그 수집
- 서버, 애플리케이션의 모든 로그를 중앙 집중화
- 실시간 모니터링 데이터 처리
- 시스템 성능, 사용자 행동 패턴 실시간 추적
- 보안 이벤트 로그 분석
- 보안 위협 실시간 탐지 및 대응
- 시스템/애플리케이션 로그 수집
- 구현 고려사항
- 로그 포맷 표준화
- JSON 형식 등 일관된 로그 형식 정의
- 보관 기간 설정
- 법적 요구 사항, 디스크 용량을 고려한 보관 기간 설정
- 처리 파이프라인 구성
- 수집 → 필터링 → 저장 → 분석 단계별 처리
- 로그 포맷 표준화
이벤트 스트리밍
- 실시간 데이터 처리
- 실시간 분석
- 사용자 행동, 시장 동향 등 실시간 분석
- IoT 데이터 수집
- 센서 데이터 실시간 수집 및 모니터링
- 실시간 처리 파이프라인
- 들어오는 데이터를 지연 없이 처리
- 실시간 분석
- 주요 패턴
- Event Sourcing
- 상태 변경을 이벤트로 저장하여 이력 관리
- CQRS
- 읽기와 쓰기 작업을 분리하여 성능 최적화
- Stream Processing
- 데이터 흐름을 실시간으로 처리
- Event Sourcing
데이터 동기화
- 시스템 간 데이터 연동
- DB 변경 데이터 캡처(CDC)
- 데이터베이스 변경사항 실시간 추적
- 시스템 간 데이터 동기화
- 여러 시스템의 데이터 일관성 유지
- 캐시 업데이트
- 캐시 데이터의 실시간 갱신으로 성능 향상
- DB 변경 데이터 캡처(CDC)
- 구현 패턴
- Outbox Pattern
- 분산 트랜잭션 문제 해결을 위한 이벤트 발행
- Event-Driven Architecture
- 이벤트 기반의 느슨한 결합 구조
- Master-Slave Replication
- 데이터베이스 복제 및 동기화
- Outbox Pattern
메시징 시스템
- 시스템 통합
- 시스템 간 느슨한 결합
- 서비스 간 직접 의존성 제거
- 마이크로서비스 통신
- 서비스 간 비동기 메시지 교환
- 비동기 작업 처리
- 시간이 오래 걸리는 작업의 비동기 처리
- 시스템 간 느슨한 결합
- 아키텍처 패턴
- Pub/Sub Pattern
- 발행자와 구독자 간의 메시지 전달
- Point-to-Point
- 1:1 메시지 전달 방식
- Request-Reply
- 요청-응답 기반의 메시지 교환
- Pub/Sub Pattern
CLI로 직접 확인하기
-
실제 운영 환경에서 컨슈머 그룹의 상태를 확인하고 관리하는 명령어
1 2 3 4 5 6 7 8 9
# 컨슈머 그룹 목록 확인 kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list # 특정 그룹의 상세 상태 확인 (Lag, 현재 오프셋 등 필수 정보) kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group sensor-group --describe # 컨슈머 오프셋 리셋 (장애 복구 시 필수) # --to-earliest, --to-latest, --shift-by 등 옵션 설명 포함 kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group sensor-group --topic sensor-data --reset-offsets --to-earliest --execute
다음 단계
Apache Kafka 복제와 고가용성 - 데이터 안정성 보장